Adobe recognizes the ethical implications of their technology. Trust in what we see is increasingly important in a world where image editing has become ubiquitous – fake content is a serious and increasingly pressing issue. Adobe is committed to both exploring new image processing technologies, such as deploying artificial intelligence (AI) and using that same technology to increase trust and authority in digital media.
In this current environment of fake news, deep fakes and image manipulation, Adobe researchers Richard Zhang and Oliver Wang, along with their UC Berkeley collaborators, Sheng-Yu Wang, Dr. Andrew Owens, and Professor Alexei A. Efros, developed a method for detecting edits to images that were made using Photoshop’s Face-Aware Liquify feature. This work is sponsored by the DARPA MediFor program. While still in its early stages, the Adobe Research and UC Berkeley, recently showed this technology at Adobe MAX. We spoke to the team about this democratizing of image forensics. While this work is very specific, the science of uncovering and analyzing changes to digital images will increasingly be an important part of the debate as the tools become smarter.
This new Adobe and UC Berkeley research is part of a broader effort across Adobe to better detect image, video, audio and document manipulations. Past Adobe research focused on image manipulation detection from splicing, cloning, and removal, whereas this effort focuses on just Face-Aware Liquify feature in Photoshop. Face-Aware has because popular for adjusting facial features, including making adjustments to facial expressions. The team have shown that they can not only detect subtle alterations to faces but also oftentimes plausibly reverse the original alterations and undo the changes.
By training a Convolutional Neural Network (CNN), a form of deep learning, the research project is able to recognize altered images of faces. The researchers created an extensive training set of images by scripting Photoshop to use Face-Aware Liquify on thousands of pictures scraped from the Internet. A subset of those photos was randomly chosen for training. In addition, an artist was hired to alter images that were mixed into the data set. This element of direct human manipulation broadened the range of alterations used for the test set beyond those synthetically generated images.
“We started by showing image pairs (an original and an alteration) to people who knew that one of the faces was altered,” Wang says. “For this approach to be useful, it should be able to perform significantly better than the human eye at identifying edited faces.”
Those human eyes were able to judge the altered face 53% of the time, a little better than chance. But in a series of experiments, the neural network tool achieved results as high as 99%.
The tool also identified specific areas and methods of facial warping. In the experiment, the tool reverted altered images to its calculation of their original state, with results that impressed even the researchers.
“It might sound impossible because there are so many variations of facial geometry possible,” says Professor Alexei A. Efros, UC Berkeley. “But, in this case, because deep learning can look at a combination of low-level image data, such as warping artifacts, as well as higher-level cues such as layout, it seems to work.”
“The idea of a magic universal ‘undo’ button to revert image edits is still far from reality,” Zhang adds. “But we live in a world where it’s becoming harder to trust the digital information we consume, and I look forward to further exploring this area of research.”

FXG: The image processing detection is impressive, is this just working off pixel and noise level style deep learning? Would it only work on pictures manipulated with say Face-Aware or could it detect cut and paste alterations in the future?
Adobe: Our network is trained only to detect the “Face-Aware Liquify” feature in Adobe Photoshop, which is popular for adjusting facial features — including making adjustments to facial expressions. With machine learning and deep neural networks, it is usually not possible to tell exactly what it is doing. Our hypothesis is that it is exploring a combination of low-level (pixel and noise) and mid-level (contours) cues.
Our network is not aimed at detecting image splicing (cut and paste); there are recent papers aimed at that operation:
- Minyoung Huh, Andrew Liu, Andrew Owens, Alexei A. Efros. Fighting Fake News: Image Splice Detection via Learned Self-Consistency. ECCV 2018.
- Peng Zhou, Xintong Han, Vlad I. Morariu, Larry S. Davis. Learning Rich Features for Image Manipulation Detection. CVPR 2018.
FXGUIDE: Does the image detection work if the file is compressed or does JPEG compression hide some of the data that would have been used for detection? In the demo at Adobe MAX, the images are manipulated and then tested, but in the wild, altered images are compressed and uploaded, copied, etc?
Adobe: We tested against such blurring and JPEG compression. In all cases, performance degraded as expected, but not all the way down to uselessness (“chance”). We found that training the system with such perturbations, known as “data augmentation,” made it more resilient.
However, something you cannot train with is physical copying. We tried printing out images and rescanning them, which was meant to simulate whether we could detect warped images in printed media. We were excited to find that by doing more augmentation at training time, the network became more resilient to this as well.
FXGUIDE: Why not combine this with metadata detection? I assume you don’t yet so that your tech demo is clean and easy to understand?
Adobe: We wanted to see how far we could push the idea, just looking at pixels. Scientifically, we weren’t sure if this was even possible. After all, an image with a little bit of warping still looks quite realistic to our eyes.
Of course, the wider problem of content authenticity extends well beyond just looking at pixels in isolation. Understanding metadata and context are critical in detecting fake media. We believe that addressing the growing problem of fake content will take more collaboration between content creators, researchers, technology providers, and content distributors. To help tackle this issue, Adobe – in collaboration with The New York Times Company and Twitter – recently announced the Content Authenticity Initiative to develop an industry standard for digital content attribution.
FXGUIDE: How extensive is the training data set? Is it based on scrapped images to build vast training data, or is it trained on a much smaller in-house set of manipulated imagery? Was the training data labeled/tagged?
 Adobe: For “unmanipulated” images, we used publicly available academic datasets, which allowed us to get >100k examples. Modern machine learning algorithms require a lot of data to train. Getting a large set of warped or “manipulated” images was difficult to obtain. Instead, we scripted the Face-Aware Liquify tool in Adobe Photoshop to randomly warp the unmanipulated images, which allowed us to generate “free” training data. We ended up with one million images total, manipulated and unmanipulated.
Adobe: For “unmanipulated” images, we used publicly available academic datasets, which allowed us to get >100k examples. Modern machine learning algorithms require a lot of data to train. Getting a large set of warped or “manipulated” images was difficult to obtain. Instead, we scripted the Face-Aware Liquify tool in Adobe Photoshop to randomly warp the unmanipulated images, which allowed us to generate “free” training data. We ended up with one million images total, manipulated and unmanipulated.
One question we had is if training the system on such random warps would generalize to real use cases. So we made a separate test set, asking an artist to manipulate a small set of images, and validated the model on this set.
FXGUIDE: Given how even a tiny amount of image processing was detected, – would resizing and colour correction be flagged?
Adobe: The network is trained to identify if the Face-Aware Liquify feature has been applied in Adobe Photoshop. During training, images are slightly resized, so it should be somewhat resilient to that. However, it is not trained with photometric modifications, such as airbrushing or global illumination changes. Therefore, performance can likely degrade in those cases (meaning this would reduce our chance of correctly estimating whether images were warped or not in the presence of such changes). This is called the “dataset bias” problem, where real test cases will differ from the training distribution.
We believe our work is an important step forward in detecting and undoing facial warping by image editing tools.
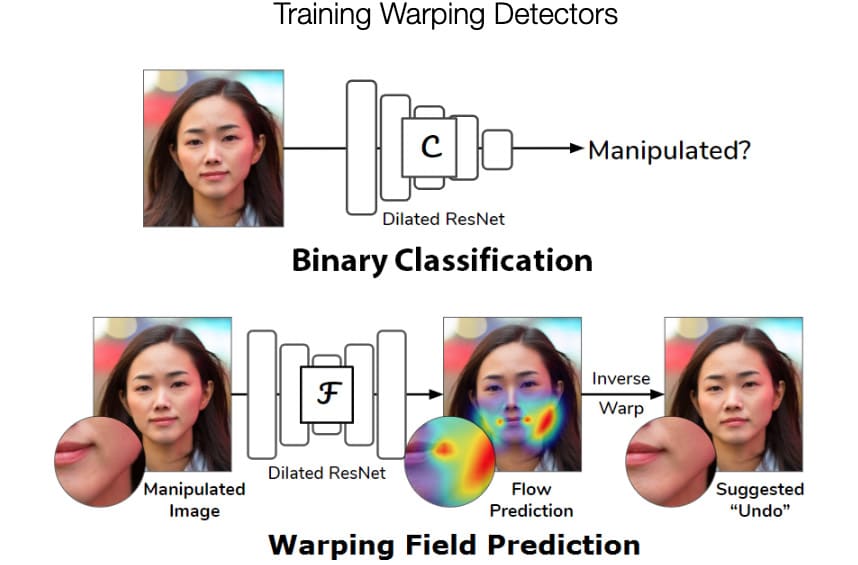
FXGUIDE: The Undo option is incredible, I assume it is balancing back to equalize the detected effect over the image regardless of what the image is… or is the UNDO using a different AI approach?
Adobe: We have two networks: the first “global” network tries to identify if Face-Aware Liquify has been used and the second tries to “undo” the change. Since the “undo” problem is very difficult, we decided to train it only on images that had been manipulated. The structure of the two networks are related but different — one has to provide a single yes/no answer, while the other tries to provide a map that describes how every single pixel was warped.
Next
Looking forward, Adobe is working across numerous research projects to help verify the authenticity of digital media created by their products and to identify and discourage misuse.
“This is an important step in being able to detect certain types of image editing, and the undo capability works surprisingly well,” commented head of Adobe Research, Gavin Miller. “Beyond technologies like this, the best defense will be a sophisticated public who know that content can be manipulated — often to delight them, but sometimes to mislead them.”
The issue of content authenticity is an industry topic that was also recently addressed at SIGGRAPH Asia in Brisbane, we will be covering that more in upcoming stories.