FUTURE ARTIFICIAL INTELLIGENCE AND DEEP LEARNING TOOLS FOR VFX
Artificial Intelligence (AI) is set to change the way VFX is approached and produced. At this year’s SIGGRAPH there are a series of key talks, papers and panels discussing applications of various forms of AI to VFX, by many of the biggest names in the Industry.
Digital Domain is one such company, they will be sharing their experience developing AI-based toolsets that apply deep learning to their content creation pipeline. Doug Roble, Digital Domain’s senior director of software R&D, will personally share DOUG as part of the FUTURE ARTIFICIAL INTELLIGENCE AND DEEP LEARNING TOOLS FOR VFX panel on the Tuesday of SIGGRAPH 2018.
AI is no longer just a research project but also a valuable technology, “There is so much interest in this area right now”, commented MPC’s Dmytro Korolov, who is organising and moderating the panel. The SIGGRAPH panel discussion will cover a range of topics especially deep learning and dive into examples of convolutional neural networks (CNNs), generative adversarial networks (GANS), and autoencoders. These examples will include flavours of neural networks useful for everything from face simulation, fluid simulations and image denoising, character animation, facial animation, and texture creation.
 Dmytro Korolov is a Technical Director, working as a Compositing Pipeline Technical Director in MPC Vancouver. He has a strong engineering background and 20 years artistic and TD experience. In 2017 he create professional LinkedIn group “Deep Learning and Artificial Intelligence for the Visual Effects industry”. The topic of the group attracted great interest of the professional community. In fact, the number of members in the group has reached 1400 people and it is the largest community on the topic of AI tools in Visual Effects.
Dmytro Korolov is a Technical Director, working as a Compositing Pipeline Technical Director in MPC Vancouver. He has a strong engineering background and 20 years artistic and TD experience. In 2017 he create professional LinkedIn group “Deep Learning and Artificial Intelligence for the Visual Effects industry”. The topic of the group attracted great interest of the professional community. In fact, the number of members in the group has reached 1400 people and it is the largest community on the topic of AI tools in Visual Effects.

Doug Roble is the senior director of software research and development at Digital Domain. He’s been working at the company for 25 years. Along the way, he’s written a computer vision toolkit that won a Scientific and Technology (Sci-Tech) Academy Award in 1998, a motion capture editing suite, a couple of fluid simulation packages (leading to another Sci-Tech Award in 2007), and much more.He was the editor-in-chief of the Journal of Graphics Tools from 2006 to 2011), is currently the chair of the Academy of Motion Picture Arts and Science’s Sci-Tech Awards committee, and is a member of the Academy’s Sci-Tech Council. This all started with a PhD in computer science from Ohio State University in 1992.
Following from last year’s MEET MIKE, Doug and the team at Digital Domain decided to make DIGITAL DOUG. (We will have more on the tech behind DIGITAL DOUG from Canada in the week of SIGGRAPH).
Doug Roble
We sat down with Doug Roble to get a preview of some of the issues and ideas that may be covered by the panel. Roble is quick to point out that it is important to understand that the term ‘A.I.’ is perhaps misleading. The panel will not be discussing the ‘Robopocalypse’, and its focus will not be on the long term possible Sci-fi futures with the technology. The panel will be more focused on how these new tools will be changing vfx pipelines in very specific areas. “These are new tools, certainly some of them are scary tools when you see them for the first time, and they could be used in evil ways,.. but then you get to a point when you see that you can use this to really do visual effects in a completely brand new way” Roble explains. There is no denying that jobs will be displaced, Roble points out there are less special effects model makers to day than before CGI, but there are also a host of new CGI jobs as most visual effects are done with computers “the field it’s self expanded but with that growth there was a shift”. He feels strongly the same things is just starting to happen with ‘AI’ tools.

“Rotoscoping is a great example, we are can already do garbage matting. That is solved, but we are really close to solving a deep learning based rotoscoping solution that will be just as good as someone can do,” he explains. He also feels that deep learning type tools will do the one thing so often discussed in effects over the years, which is to “put vfx in the hands of non-experts”.
There are a number of ways AI or more accurately Machine Learning is being used in VFX. In part 2 of this series fxguide will look at an approach that will be shown at Real Time Live that redefines a 3D pipeline completely. These class of solutions get a result but without the traditional notion of making a model, texturing, lighting and rendering it. In other words, they fundamentally changing the way some effects are done. “If you look at almost every aspect of visual effects, we used to try and mathematically model reality, …one way or another, from fluid simulation to animation, it was all algorithms that were hand tuned. Now there is this huge shift with machine learning so that the solution is a data driven approach”, comments Roble. (More on this in Part 2).
Machine learning
There are many aspects to Machine Learning (ML), but a key point is that it often involves building a structure within which data drives a black box solution. This is very different from traditional programming that is built on ‘if-then-else’ style logic. With Machine Learning, a large amount of data allows a part of the computer program to optimise for the best result. It is called a black box as how the program does this is often times invisible to the user and something the user does not even care about. It is also marked by the common experience of taking quite some time to learn or find this optimisation, but having done so, it is then very fast to run or execute. For example, there is a fluid sim that takes data from many fluid simulations. To work out what might happen inside the limited range of a ML fluid simulation situations takes a long time, but then a very plausible fluid simulation will run extremely quickly. In the video below from 2015, the data driven simulation runs in real time, even with graphics hardware from 3 years ago.
The other important point with deep learning techniques is that, for the most part, the solution of what can be done is defined by the ‘input data space’. If you think of a mutli-dimensional space that is defined or bounded by all the training data, then it is within this space that the solution will work. Or to put it another way, the extent of the training data defines the solution space.
Finally, it is important to not over think what a ML is doing. While it can produce brilliant visual effects such as a fluid sim, it has no understanding of fluids or physics. It is easy to make the jump to thinking that these approaches are very intelligent, but it is the artists and TDs that drive these ML programs that are intelligent. The programs are data driven tools that are innovative in their conception, but they are not indicative of general computer Intelligence.
For example, at a recent Conference on Neural Information Processing Systems (NIPS), researchers from NVIDIA showcased some seriously smart machine-learning tools that are able to digitally alter a video of a winter scene so that it looks like it was shot on a clear day, even with very poor quality input video.
To create their video-altering tool, the NVIDIA team developed a neural network design to achieve unsupervised image-to-image conversion. The algorithm is described in a paper available here. While it seems like the program would need to make artistic choices to achieve this, the program works on training data. This style of tool could be immensely useful in VFX. However, NVIDIA is actually more likely to be developing this as part of their Self Driving Cars program, not withstanding this focus, the VFX community stands to benefit from this wider ML research.
Machine Learning
In this part 1, we look inside what one might call a traditional pipeline, but with dramatic new deep learning stages are being added. In our own MEET MIKE at last year’s SIGGRAPH, the Cubic Motion team used ML computer vision approaches to solve markerless face tracking. Almost every week a new paper comes out that either shows a new approach, or takes an older approach that was human intensive and adds a machine learning innovation. We asked Doug Roble for an example of a paper he that he has recently read or seen presented that really impressed him and was an example of dramatically improving a traditional way of working using machine learning. A paper that might be referenced on the upcoming SIGGRAPH Panel. He suggested this paper below from this year’s Conference on Computer Vision and Pattern Recognition (CVPR). “This paper just blew me away,” commented Roble. “It takes a single image of a person and produces a textured mesh, it is incredible. It basically models the person’s face and not only does it modelling their face, it approximates a decent texture”. While many people are aware of the advances in face recognition, “now people are building on that, and there is this multi-layer thing where someone can use the fact that the computer can recognise faces to produce faces… to make 3D models of faces” comments Roble.
Reworking Old techniques with Deep Learning
Unsupervised Training for 3D Morphable Model Regression
The 2018 paper is by Kyle Genova, Forrester Cole, Aaron Maschinot, Aaron Sarna, Daniel Vlasic and William T. Freeman. This is work mainly from Princeton University and Google Research.
The paper that Roble flags shows a method for training a regression network from an image to 3D morphable model using only simple normal photographs. What is nice about this paper is that it builds very directly on a 1999 SIGGRAPH paper.
In the new paper, the Machine Learning engine is using a single picture of a person and trying to find their face, build a model of the face and also provide the texture for the face. “If you’d told me about this a few years ago I would have said it is not possible, but here it is working,…the results that they are getting are not bad, they are not perfect, and I don’t know if we’d use it for a feature film, but it’s getting close”, comments Roble.
The approach is built on some technology that was first published in the 90s, namely Morphable Model shapes, which are “a bit like blend shapes for facial identity” Roble adds. Cyberware, a former scanning company, was involved originally in scanning a large database of people, 200 heads of young people (100 male and 100 female) were scanned. The original paper (that this new work is built on) from SIGGRAPH 99 stated that by “exploiting the statistics of a large dataset of 3D face scans (geometric and textural data from Cyberware) we built a morphable face model … The morphable face model is a multidimensional 3D morphing function that is based on the linear combination of a large number of 3D face scans.”
The original paper (1999): A Morphable Model For The Synthesis Of 3D Faces.
The original paper by Volker Blanz Thomas Vetter of the Max-Planck Institute was titled: A Morphable Model For The Synthesis Of 3D Faces. A morphable model was said to be based on a data set of 3D faces. Morphing between faces requires full correspondence between all of the faces, and in this original paper the process required human intervention or at least human assistance.
The process from the original paper is not too complicated to understand:
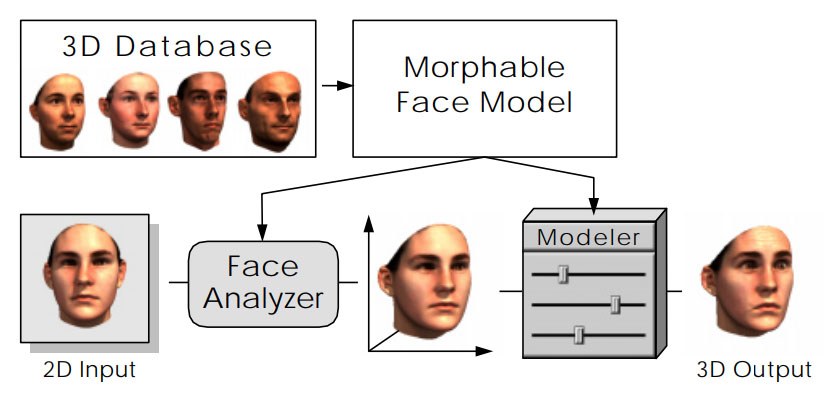
Derived from a dataset of 3D scans of faces, the morphable face model contributes to two main steps in face manipulation: (1) deriving a 3D face model from an image, and (2) modifying shape and texture in a believable and natural way.
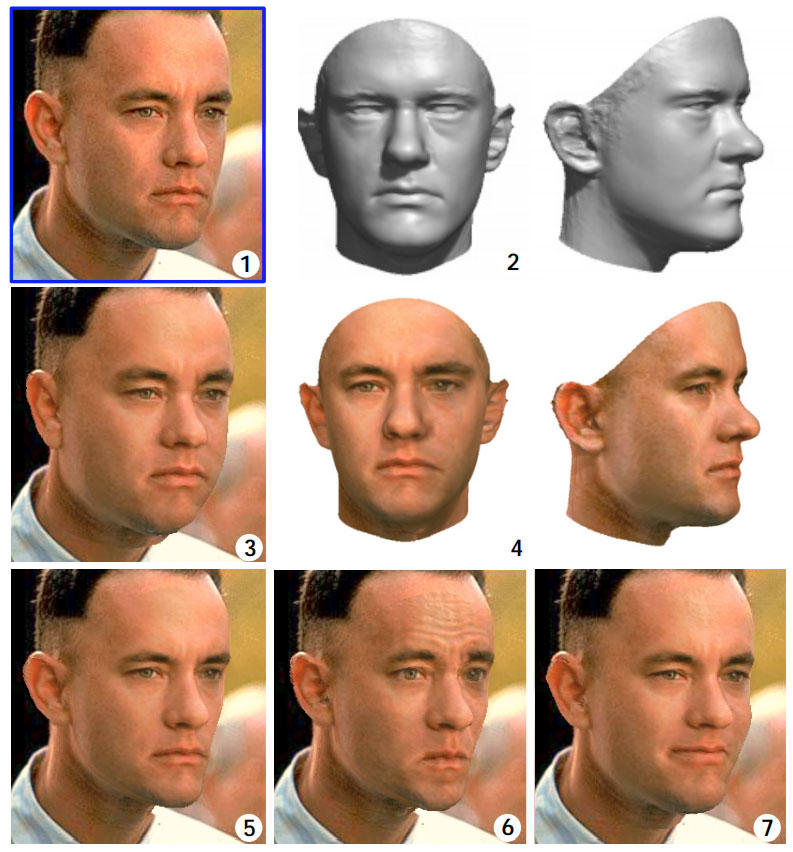
In the Tom Hanks example above: Matching a morphable model to a single image (1: Starting image) of a face results in a 3D shape (2nd image) and a texture map estimate in (3rd image). Note at this stage, the textures are rough and the face is a little heavy but for cira. 1999 this was remarkable. The texture estimate can be improved by additional texture extraction (Images marked 4). The 3D model is rendered back over the top of the original image and then bottom row of shots (5,6,&7) are all deliberate variations. (5) is the 3D after changing facial attributes to make ‘digital Tom’ loose weight (5), frowning in (6), or being forced to smile (7).
The scanning resulting in faces were represented by approximately 70,000 vertices and the same number of color values. If there is correlation between the vertices between one face and another, one could morph between the two faces and produce a blended animation ‘3d morph”. But the original paper was not aimed at doing just video style morphs. The original team worked out an average face, and then delta offsets for every face in the database that showed how the parameters of any person differed from the average. A set of ‘offsets’ from the average that would get you to a new face that matched the scan. It also allowed for mixing faces, taking the upper head region of Bob and the mouth of Jane, for example.
The set of 200 people defined the ‘face space’. i.e. the computer knew that no one has eyes further apart than the widest separated eyes from a person in the scanned ‘training’ data.
In reality, this paper did not store deltas, it used Principle Component Analysis (PCA) to say what values were important. PCA is a common technique for data compression/simplification, it performs a basis transformation to an orthogonal coordinate system formed by the eigenvector of the ‘offsets’.
In practice, the team found from the PCA, that there was a set of shapes that when combined could ‘span’ the ‘face space’. The problem becomes a set of ‘important faces’, with weightings and ways of combining them together, built on top of the ‘average 3D face”. Importantly, it was also not just vertices, it was also RGB texture values. And the same sort of approach was applied to the textures of the scanned/sampled faces.
While this worked, it did require some human assistant to line up all those vertices to key facial features. Back in 1999 only a few parts of the face could be found by a computer, and those were limited to things like the eyes and the corners of the mouth, and little else. The approach was sensible but it was still labour intensive and all the resolutions at each stage were lower resolution than we compute today.
The new paper : Unsupervised Training for 3D Morphable Model Regression
In reading the original paper it is easy to see that this is a great solution that is perfect for deep learning. The new 2018 paper replaces the need for human assistance. It takes advantage of a new program from Google, FaceNet

The new system works with a large collection of faces (from the internet). The problem with this training data is that it is only the ‘source’ or input. The photos from the internet do not have corresponding 3D mesh solutions. One of the main ways to use training data sets is to uses the input data and the solutions to that data. In other words, this class of deep learning normally needs the ‘questions and the answers’ to learn from. An image alone cannot validate if the resulting 3D models are a good likenesses or even vaguely human like.
Instead of just using internet photos, the team used the 3D Morphable model system in a hybrid solution.
As the diagram below shows, the system makes up synthetic parameters which produces synthetic images (but from the old paper above we know that are still inside ‘face space’, they can be thought of as 3D morphs between real faces and thus plausible). This is the top left of the pipeline.

These synthetic images are then feed into an identity encoder along with the real images from the internet. The identity encoder output is a 1024 dimensional data view on the face.
This is where Google’s FaceNet comes in. FaceNet is a near perfect facial recognition system with some 260 million faces in its database. It uses a deep convolutional network trained to matching a face using a novel online triplet mining method. The benefit of this approach is the enormous representational efficiency: it achieve state-of-the-art face recognition performance using only 128-bytes per face (128 dimensional layer). FaceNet also internally, technically provides a special “1024-D vector avgpool layer” as part if the “NN2” FaceNet architecture, and the paper actually uses this technical multi- dimensional representation of a face during the process.
Before FaceNet outputs that the input image is a picture of the face of say: ‘Mike Seymour’, it outputs a series of numbers that places the face it is own bubble or ‘hypersphere’ of possible faces. Once one has the numbers, it could look up that those numbers are equal to say “Mike Seymour’. (Note Actual Mike was not involved with this – we just use him as an example).
If we ignore the output name for a second and run Google’s FaceNet on a image that is of Mike Seymour and get a set of numbers, and then we find that one of the synthetic parameter images ALSO lands close to those numbers, then it says this random synthetic face we made, looks like Mike Seymour. BUT if it is only close, we still have something to improve upon, some target to beat. Our system can now play around with different numbers or synthetic input parameters and see if it can get a result closer to the magic numbers FaceNet output for real Mike Seymour.
Similarly, if the synthetic face looks less like Mike Seymour (from FaceNet’s point of view) it can learn from that and correct. In the diagram above, the right hand side is this process of comparing and then working out the amount the program missed the mark, so that it can try again until it produces a set of input Synthetic parameter numbers that the Google FaceNet cant tell isn’t actually a real image of Mike Seymour.
To be precise this new paper employs an encoder-decoder architecture that permits end-to-end unsupervised learning of 3D geometry and texture morphable model parameters. What that means is that, without human intervention it learns a set of parameters over time that allows it to make a 3D face, from a simple jpeg input.
“Isn’t that what an artists sort of does?” explains Roble. The machine is adjusting the parameters until it looks better, but unlike an artist who considered the image visually and tries to estimate what visual quality is not right, the pipeline above looks at some actual numbers – the 128 byte file and says I am trying to get my new made up numbers to match these, (and then we’ll have a face image that Google cant tell apart from a real photo). “Remember that face that is made, comes with both shape and texture”, comments Roble. “If you can create a face that foosl FaceNet, then that is great, – because FaceNet is hard to fool. FaceNet is darn good, Google put a lot of work into FaceNet”.
In the diagram one can see boxes called ‘loss’ functions, Parameter Loss, Loopback Loss and Batch Distribution Loss. These are just measures of how close the face is to suceeding. As discussed, the process needs to know how close we are to the correct solution and then inform that back to earlier in the process to improve. in lay terms, “if I change a value up front then how well or poorly did it change the quality of the output. Measure that amount and inform the next iteration” says Roble.
The training loss is based on features from a facial recognition network, computed on-the-fly by rendering the predicted faces with a differentiable renderer. “You need this new differentiable render as you need to be able to say ‘hey this render did not work, what do I need to do change in the Neural Network that produced this thing to make it better”, explains Roble. To make training from features feasible and avoid network fooling effects, the team introduced the three “loss’ functions: a batch distribution loss that encourages the output distribution to match the distribution of the morphable model, a loopback loss that ensures the network can correctly reinterpret its own output, and a multi-view identity loss that compares the features of the predicted 3D face and the input photograph from multiple viewing angles.
There is one final step to take the output from the system and render it as the final face, and here the advanced pipeline also cleverly manages the texture and deal with lighting on the faces. The system produces a model and a lit texture on it.
Super Simple Version (in plain english):
If one was to simplify the process to its core: it produces a lot of faces and sees which ones look like someone real based on Google’s FaceNet as the referee. When it misses the mark it works hard to tweak the values until Google’s FaceNet can’t tell the difference between this and a real photo of that person.
What is important to note is that this style of work is using some real world data and also its own synthetic data. It is also worth noting that the pipeline uses an ‘off the shelf’ Google Neural Network tool, FaceNet. It uses a vast tool from the general computer science world to serve a VFX function. Finally, it is automatic in the sense it is not a traditional artist tool, even if we can see similarities to how an artist might work.

Making 3D models from real photos is impressive enough but the process works so well it can produce a plausible face from an artistic painting or drawing of someone, or even a partial or defocused source image. This moves from impressive to almost unbelievable.

The Panel:
Time: Tuesday, 14 August 20182pm – 3:30pm
Location: East Building, Ballroom BC, Vancouver Convention Centre
Joining the panel organiser and Chair Dmytro Korolov on the panel, in addition to Doug Roble, is
Jean-Charles Bazin
Korea Advanced Institute of Science and Technology
South Korea
Jean-Charles Bazin is Assistant Professor at KAIST, South Korea. He is conducting research on Artificial Intelligence (including machine learning and deep learning) for various applications such as video effects, video editing, VR content generation, video captioning, and audio-visual processing. He has been working in both academia (ETH Zurich, NTU Singapore, University of Tokyo, KAIST) and industry (Disney Research). He published several papers in the premier venues of computer graphics (TOG, SIGGRAPH, SIGGRAPH Asia and Eurographics) and vision (TPAMI, CVPR, ECCV and ICCV). His work was covered in the news by Discovery Channel, Gizmodo, Engadget, The Verge, TechCrunch, among many others.
Rob Pieke
MPC
United Kingdom
Rob Pieké is the Head of New Technology at MPC in the heart of London. Having recently celebrated his eleventh year with the company, Rob has been involved in the development of custom technology for dozens of films, from Harry Potter to Guardians of the Galaxy and, more recently, The Jungle Book. Rob started programming in BASIC as a kid, and went on to get a degree in Computer Engineering from the University of Waterloo. With his passion for computer graphics – rendering and physical simulation in particular – VFX caught Rob’s eye quickly, and he’s never looked back since.
Renaldas Zioma
Unity Technologies
Sweden
Renaldas is leading research into Machine Learning application for game and film creation at Unity Labs department of Unity Technologies. Before devoting time to research Renaldas took several roles at Unity: introducing Physically Based Rendering in Unity 5.0, porting Unity to iOS, engine and graphics optimisations, establishing Demo team, and worked on real-time shorts including “Buttefly Effect”. In the past Renaldas contributed to rendering and AI optimisation of another game engine at Electronic Arts – Frostbite engine. Frostbite is notorious for environment destruction system and powering high-quality AAA titles.
Renaldas spoke at several large conferences – SIGGRAPH, GDC, FMX, Unite.
Jeff Kember
Google
USA
Jeff Kember is the Technical Director for Media in the Office of the CTO at Google. His background in high performance computing helps media and entertainment clients make efficient use of Google’s Cloud Platform for compute, machine learning and storage workloads. He has been advising companies across verticals to aid in their integration of machine learning technologies. Prior to joining Google, Jeff led large teams as a Computer Graphics Supervisor at Framestore. Over his 20 year career in film and gaming, he has worked at a variety of companies including Pixar, Sony Imageworks, Industrial Light & Magic and Blizzard Entertainment.
David Luebke
NVIDIA
USA
Dr. David Luebke helped found NVIDIA Research in 2006 after eight years on the faculty of the University of Virginia. Today he runs NVIDIA’s research efforts at the intersection of computer graphics, machine learning, and virtual & augmented reality. Together with his colleagues David has written a book, created a major VR museum exhibit visited by over 110,000 people, taught an online course on parallel computing that has reached over 100,000 students, and authored over a hundred papers, articles, chapters, and patents. David is an NVIDIA Distinguished Inventor and a Fellow of the IEEE.