D-ID is an innovative GenAI startup making interactive digital humans.
By blending the smarts of advanced LLMs such as ChatGPT, Claude, or Llama with the natural feel of face-to-face communication, D-ID aims to have its Agents redefine digital connections, making human-computer interfaces more personal, engaging, and, well, …human.

D-ID’s Creative Reality Studio is a self-service platform featuring the best generative AI tools to enable users to create videos with moving and talking avatars. The moving avatars are trained on a few minutes of uploaded video and come with hand gestures as a mid-shot/waist-up presentation of a person. The one-shot talking heads allow a single Jpeg to be animated and output as a normal video. You can drive the digital humans with voice or text, but the still images are not interactive and not as impressive as the full digital agents.
Quick and easy Jpeg to Video.
The simplest videos D-ID provide bring a jpeg to life, but the quality is not as good as the interactive humans, and while it appears to be lip-synced, they are designed to allow anyone to provide a quick, easy and very fast pre-rendered animated clip. D-ID is not the only company doing this form of re-animation; this was the first service the startup offered a couple of years ago. You can see in the video below that the teeth are completely not seen in the source Jpeg (top left), so the GenAI has to entirely ‘guess’ or infer the interior of the mouth and teeth. Of course, this is GenAI with just 1 frame of training data. The interactive digital humans are trained on a much longer actual video clip and thus much higher quality. The still-to-video is built on a series of individual technologies and AI tools such as key point detectors, motion predictors, occlusion fields, spectrogram (audio) interpreters and naturally adversarial generators. Versions of these key technologies such as these are used throughout the company’s solutions.
Interactive digital humans

D-ID addresses the most interesting space in conversational agents, putting a face on an LLM. The knowledge sources can be Grounded, Hybrid or Ungrounded. These represent various levels of control and guide rails, and this approach is now fairly standard for state-of-the-art such systems. If your digital human is advising on cars, then it could have general knowledge about cars from ChatGPT or any similar LLM. Naturally, you may want to have specific brand knowledge about your brand’s latest model cars, including information that may not be available on the Internet and is unlikely to be up-to-date. The way this is handled is by effectively having a data sidecar. This additional information is a data file, which is part of a retrieval augmentation generation system or RAG. When a query is made, it is first directed into the RAG, which creates a vector based on the additional information it has processed. This is then bundled with the original request and passed on to the LLM. You can think of it as providing additional context and information to the LLM. This is different from more training data, as the contents of the RAG file are not absorbed into the master LLM, nor can anybody else access that information outside your digital human. This means when you ask a digital human a question, it can either answer only based on what it knows from its local file, or it can work as a hybrid using the RAG to augment a master prompt, and of course, it’s possible to pass any prompt to the LLM directly.
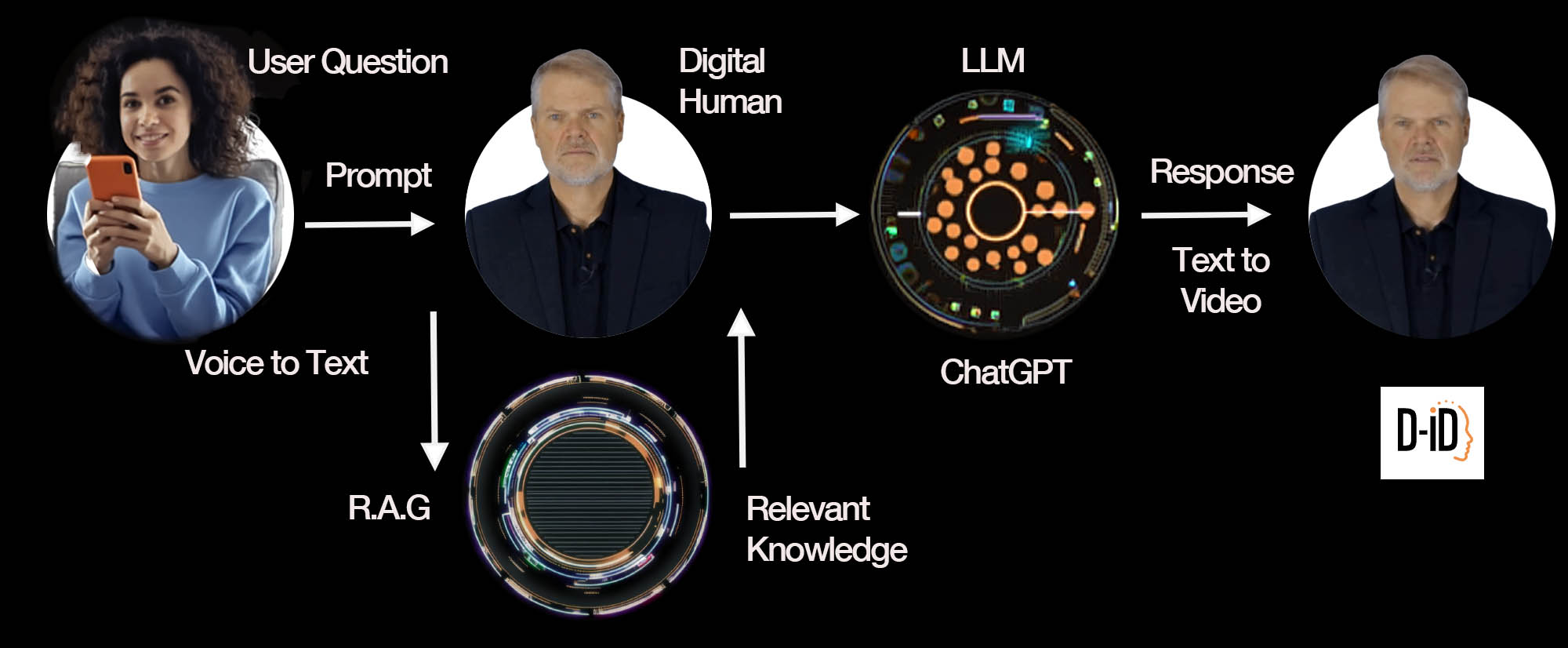
Your digital human’s appearance can be created by feeding in custom material that creates your own unique digital human, as we have done for this article, or using one of the library characters. Similarly, you can use one of the standard voices or any number of techniques to clone a voice to make it sound like your desired advisor or digital assistant.
What separates D-ID from other digital human tools is that it is not designed just to produce just an output video (although the company does have exactly that kind of a service). The difference is the interactive digital humans that the company offers. D-ID has gone to great lengths to try and make the latency as short as possible so your digital human can seem responsive, answer questions meaningfully, and appear to listen when you are talking. The company claims it’s one of the fastest (if not the fastest) interactive digital human agents currently available.
The package is available either as a black box/simple setup requiring no programming or complex computer understanding. Or you can open up the entire system to a bespoke API setup of your own design—providing your own specific LLM with complex, detailed interactions and replacing the LLM with something more structured, such as Google Dialogflow.
The company points to research showing that people are 75% more likely to watch a video with someone than just text and images and that faces are 93% more compelling and gain more attention than other visuals. The company is also very aware of the issues surrounding training data and maintaining users’ rights over uploaded material.