Introduction
In our previous articles, we focused on work that seems destined to help wide scale adoption of facial reconstruction, not necessarily aimed at just the high end or vfx market. There is naturally also work being done to produce similar facial solutions that are very much aimed at the high end. While such solutions will no doubt trickle down to wider applications, these approaches are aimed at producing immediate results in the production of advanced high end facial simulation and animation.
There are about four leading research centres around the world in this area of facial capture and reconstruction, one of those hubs is in Zurich and centered around Disney Research. The team there has been delivering outstanding contributions for some time now and their work is both pushing the boundaries of the field and finding its way into Disney pipelines at such places as ILM. We recently profiled their work on eyes, but this is just a part of their huge research momentum into of digital humans.
Disney Research Zurich’s work has also major implications and benefits to companies in the Disney Group. In an upcoming article, we will look specifically at ILM’s face pipeline and this work highlights their massive contribution with the Medusa Rig. In addition to Medusa, Disney Research Zurich is doing a range of outstanding work, they are often described as the Science behind the Magic at Disney. We recently spoke to just two of the key researchers in this area Dr. Derek Bradley, Research Scientist and Dr. Thabo Beeler Senior Research Scientist and the Group Leader Capture and Effects both at Disney Research Zurich. These researchers and their team members are as humble as they are generous and innovative and their names now regularly appear in the credit rolls of films such as
- Rogue One: A Star Wars Story
- Doctor Strange
- The Jungle Book
- Star Wars: The Force Awakens
- Teenage Mutant Ninja Turtles
- Maleficent
But perhaps just as frequently, their names also appear in SIGGRAPH papers pushing forward the frontiers of Facial capture and simulation. To look at their latest work just published, one needs to briefly look at last year’s Siggraph 2015 contribution first.
Siggraph 2015: Single Web Cam style capture
In August 2015 Disney published this Siggraph Real-time high-fidelity performance capture paper.
This paper is a major contribution as it worked from just a mono video or web cam type source and produced very high frequency detail in the output model.
The core idea the team came up with was to enhance a global real-time face tracker and solver, which provides a low-resolution face mesh, with local ‘tricks’, that add in medium-scale details, such as expression wrinkles. In effect this approach solved the face and then locally added the wrinkles. Importantly, this work is focused on processing a stream of video, and not just producing a face from a single still frame.
The team noticed that wrinkles appear in different scales and at different locations on the face. A set of wrinkles around say the eyes are fairly local to that part of the face and very self-similar. Wrinkles around the eyes happen due to the local shape of that part of the face. In other words, crows feet happen due only what is happening near the eyes on that side of your face. This meant that the team could train local regressors from high-resolution capture data in order to predict the local geometry and what that translates to great results, in terms of appearance.
They developed an automatic way to detect and align the local patches required to train the regressors and run them in real-time. Translated this means that while the tracker does not track the high frequency wrinkles directly, the software can add back in the missing wrinkles using training data learnt previously.
The system is generic and can be applied to any real-time tracker that uses a global approach, e.g. a blend-shape system. Once trained, their 2015 capture approach can be applied to any new user (face) without any additional training. The final high-fidelity facial performance reconstruction will have person-specific wrinkle details all from a mono video camera, in real-time.
New in 2016
The 2015 paper assumed a web cam style environment but the Team also cover the very high end. Last year, at Siggraph in California, the Disney Research team from Zurich published two new papers that address the high end directly, but both do not require special markers on the face. The first was published at Siggraph 2016 and the second was published recently at the 3D International Conference on 3D Vision (3DV) at the end of 2016.
SIGGRAPH 2016: Full head reconstruction from a Mono Camera
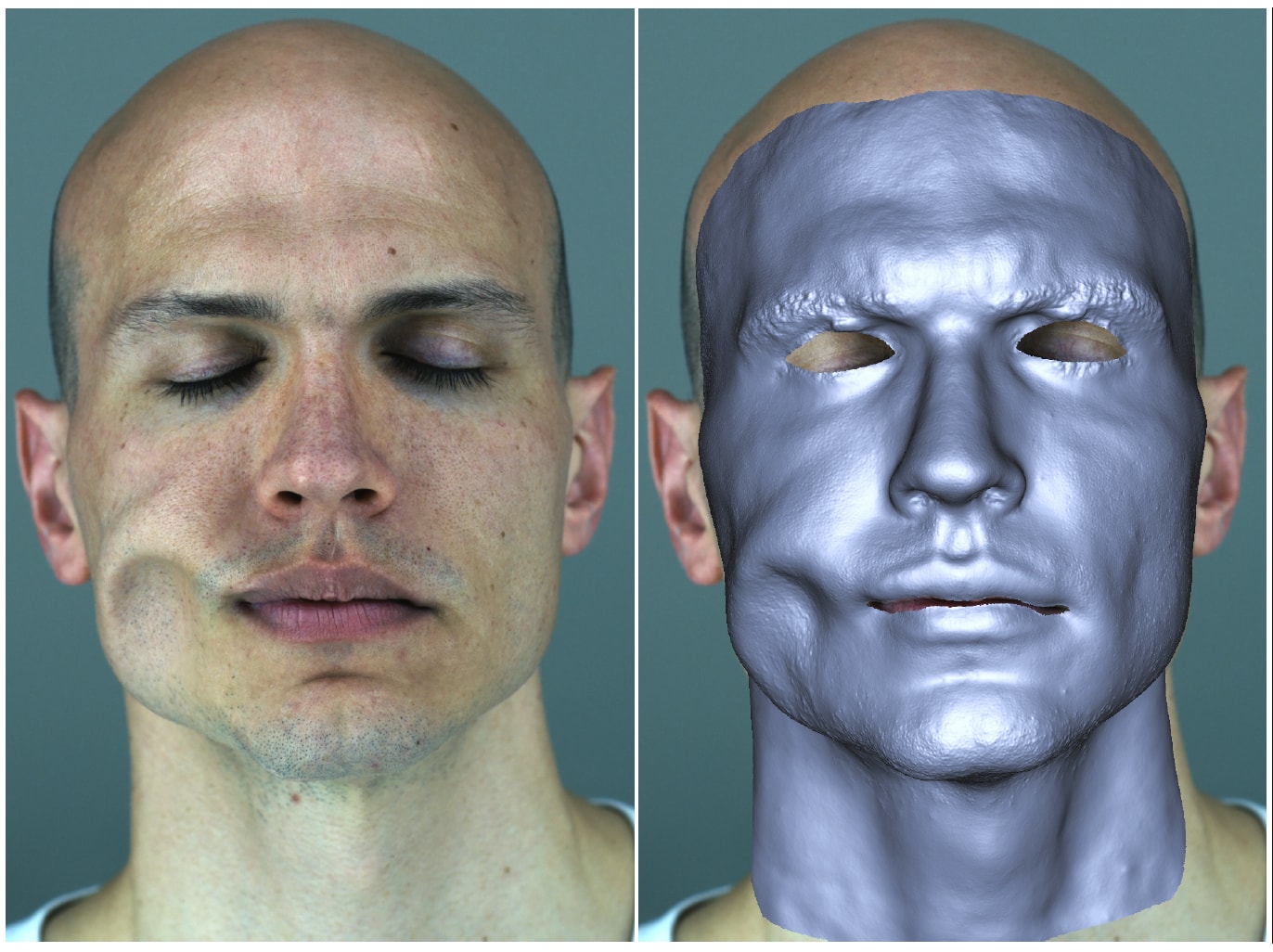
The first 2016 paper was published earlier this year at SIGGRAPH 2016. This approach works again on mono video without any special facial markers or head rigs but it produces results that are remarkable. One problem with any head rig is the very weight of the rig and the physical helmet can impact subtle facial detail. There has been some research in the UK suggesting this may be why the forehead is poorly sampled and thus animated unrealistically. Lack of subtle things like forehead movement may seem almost trivial but given just how brilliantly our brains have developed to read and process faces, subtle is the key to crossing the Uncanny Valley.
This new approach not only again uses a mono video feed, but by using assumptions about the skull and the jawbone’s range of motion, it produces incredible detail.
The team presented at SIGGRAPH 2016 a new and very high quality anatomically-constrained face modeling and fitting approach for tracking 3D faces from 2D motion data. A key part of this is introducing key constraints based on what is happening under the skin while only ‘seeing’ what is happening on the surface of the skin.
Most global face models use a large set of blendshapes. This new approach uses a large set of small local subspaces or ‘patches’ spread over the face. This new model would normally not work well and be prone to errors but the Disney Research group added an innovation. They added assumptions and constraints built about the skull and jaw coupled with skin thickness. This means that even though the computer has no depth information from its one mono camera, it can constrain the face model to sensible solutions.
T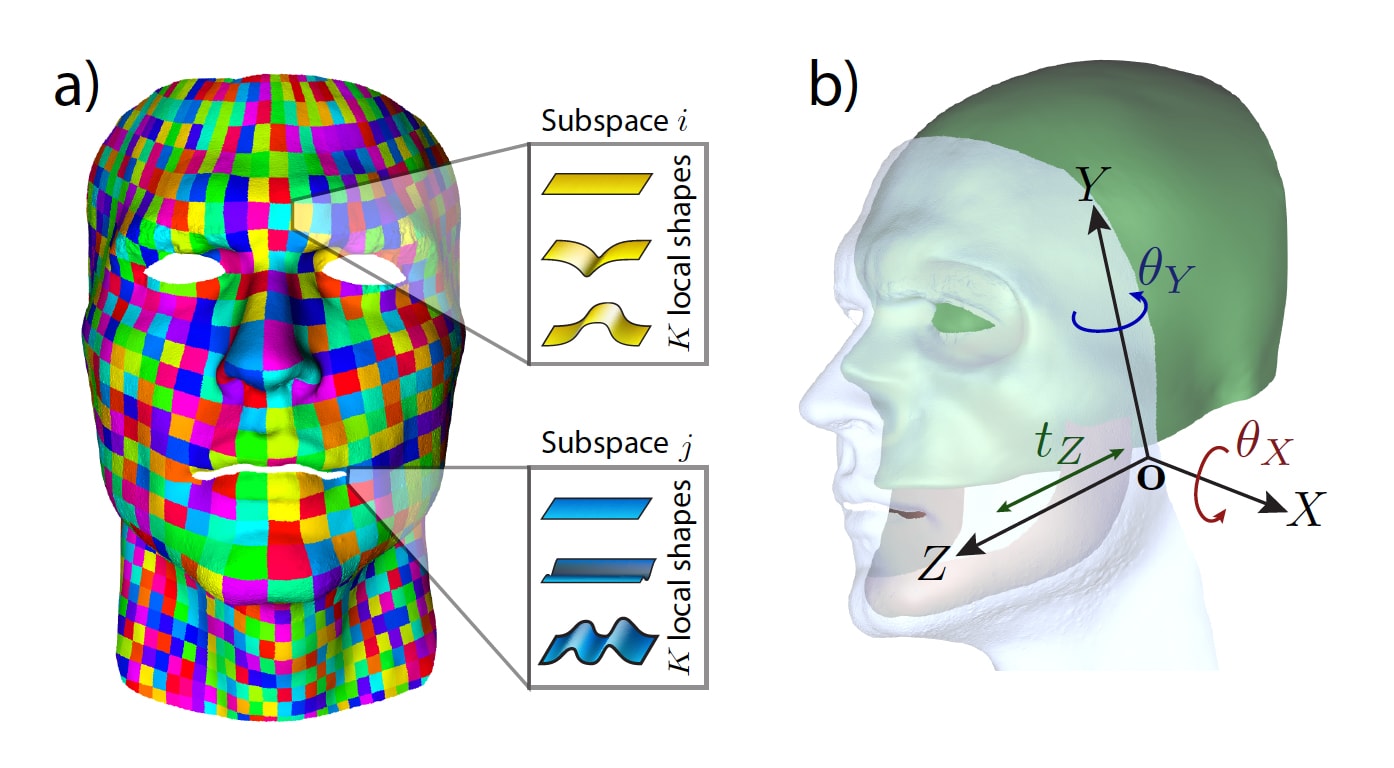 he human face is annoying from a tracking point of view as there is no fixed points. The only actual direct view of where the skull is (under the skin) is when one’s top teeth are showing. The top teeth are rigid to the skull and the skull is inflexible. In normal performances that is not enough to rely on. The second issue is that the lower face dramatically is affected by the position of one’s hinged jaw. But as the Disney Research team came to rely on, the jaw cannot move just anywhere, – it has a limited range of motion. While every face is different, we all have our jaws consistently hinged and we have similar facial skin thicknesses.
he human face is annoying from a tracking point of view as there is no fixed points. The only actual direct view of where the skull is (under the skin) is when one’s top teeth are showing. The top teeth are rigid to the skull and the skull is inflexible. In normal performances that is not enough to rely on. The second issue is that the lower face dramatically is affected by the position of one’s hinged jaw. But as the Disney Research team came to rely on, the jaw cannot move just anywhere, – it has a limited range of motion. While every face is different, we all have our jaws consistently hinged and we have similar facial skin thicknesses.
Given this new approach, the team can produce a 3D facial performance reconstruction from a single view at extremely high quality, far beyond previous fitting approaches. Their approach is flexible, and can be applied also when only limited motion data is available or even face posing from artistic sketches (!).

By incorporating anatomical constraints, the team can automatically stabilization the performance virtually for free. To show just how good this new approach is, the team filmed an actor being hit with an air hose, and filmed it in slow motion. The system managed to reproduce the extreme local skin deformation caused by the air from a single high-speed camera.

3DV 2016: Single camera head tracker
The second 2016 paper was published in late 2016 at 3DV. This paper deals with real time facial capture from a single head cam.

Real-time facial performance capture has recently been gaining popularity in virtual film production. This form of capture drives FACS rigs built on scans done off the main set,in say a Medusa Rig. There is a vast amount of issues with head rigs, and since their introduction, primarily on the set of Avatar, these have been slowly addressed.
The point of having the head mounted rig is that the actor can move freely and act. But such movement creates facial movement due to inertia, it also can restrict the face from moving freely by being tightly bound to the actor’s head, or worse be loose and move relative to the face, blurring the tracking info and confusing the solution.
Driven by advances in machine learning, which allows for fast inference of facial geometry from video streams, there has been great advances in head rigs and solvers. Head rigs need to be addressed for head stabilization and for tracking various points or features on the face. As mentioned the sparse data cloud of tracked human features or facial dots (if any were supplied) need to be ‘solved’ into the FACS space made from a set of offline facial scans. This solving (to the best combination of FACS blendshapes) is absolutely key to the whole face pipeline’s success.
The various computer learning-based approaches are significantly influenced by the quality and amount of labelled training data. Disney found that the tedious construction of training sets from real imagery can be replaced by rendering a facial animation rig under on-set conditions expected in production. Most computer system that people refer to as “AI” or “Deep Learning” rely on the principle of having accurate training data. This notional set of training data is not just example footage, but the data that goes ‘in’ and the human verified ‘correct solutions’. One can think of this as learning maths from a text book. You need example problems and the answers at the back of the book to see if you are doing the maths correctly. It would be very hard to learn if you never knew how accurate your answers were.
The Disney Research Team do not rely on just human verified previously solved solutions. They made a system that uses and learns from a synthetic actor. They did this by adapting a state-of-the-art facial tracking method. Synthetic training significantly reduces the capture and human annotation burden and in theory allows generation of an arbitrary amount of data. But practical realities such as training time and compute resources still limit the size of any training set. Disney Research constructed a better yet smaller training set for faces by investigating which facial images are crucial for tracking accuracy. They looked at everything from the dimensions of the expressions, viewpoint, and illumination. This lead to a reduction of training data in the range of 1 to 2 orders of magnitude, whilst being just as accuracy when tracking challenging on-set actor footage.
In a sense the Disney Research Team work worked out what would be most useful in the “maths” book to learn and reduced the automatic training data generator to producing just those sorts of examples.
While training data is not discussed as much as the results (even by us here at fxguide!), a fast solver that does things in minutes or seconds may need hours or days to evaluate or learn from training data. If you can train systems faster, then the preparation time reduces and furthermore the computer can make its own training data. This saves hours of production time but it also gives consistent results. For these approaches to work, a vfx producer needs some sense of the consistent quality that can be produced in a production environment and with a predictable amount of input in time and resources.
As is the case with much of the Disney Research teams work in Zurich, the tools are designed to be adopted widely and they avoid one off special fixes or hacks that can not have a universality be translated into a variety of real world environments.
What’s Next?
The deadline for SIGGRAPH 2017 has just happened, but the world will not know what will be published for some months. The team has been doing outstanding work with teeth reconstruction and this is already being played with and explored by ILM as you can read about in our upcoming article on the technical face pipeline at ILM.