GTC Keynote
NVIDIA CEO Jen-Hsun Huang kicked things off at the GPU Technology Conference (GTC) at Tuesday’s keynote address. The conference has considerably grown in size, with attendance doubling since 2012. It’s not just the conference growing, with four times the number of registered CUDA developers compared with four years ago.
Like last year’s conference, the big theme at GTC 2015 is “Deep Learning” and artificial intelligence learning, which the parallel processing GPUs are especially suited towards. This is the highest growth area for NVIDIA, which is not surprising considering that there has been almost $2B USD of investment in AI startups according to Venture Scanner. One may think that this has little relation to visual effects, but watch fxguide in the coming months to find out why this area of research and tech is important to the industry.
While a full discussion of deep learning is outside the context of the article, as a bit of background it is about feeding input into a program and then providing some kind of feedback about this input. Over time, as more and more inputs are entered, relationships between the various inputs are made. In addition, with AI, input from humans is not necessarily needed — and the programs are “self-learning”.
A real-world example of this would be voice recognition or image classification such as AlexNet. As more and more images or sounds are fed into the system, complex multi-level relationships are created which allow the program to identify images or words. These deep neural networks become more accurate as more data is input into them. This allows something like AlexNet to recognize and identify what the content is of an image being fed to it.
Deep learning and AI are hot areas in tech, and one reason Huang says NVIDIA is “all in” on high-performance computing. The new product announcements at GTC 2106 reflect this, with the new TESLA P100 GPU and the DGX-1 high performance workstation.
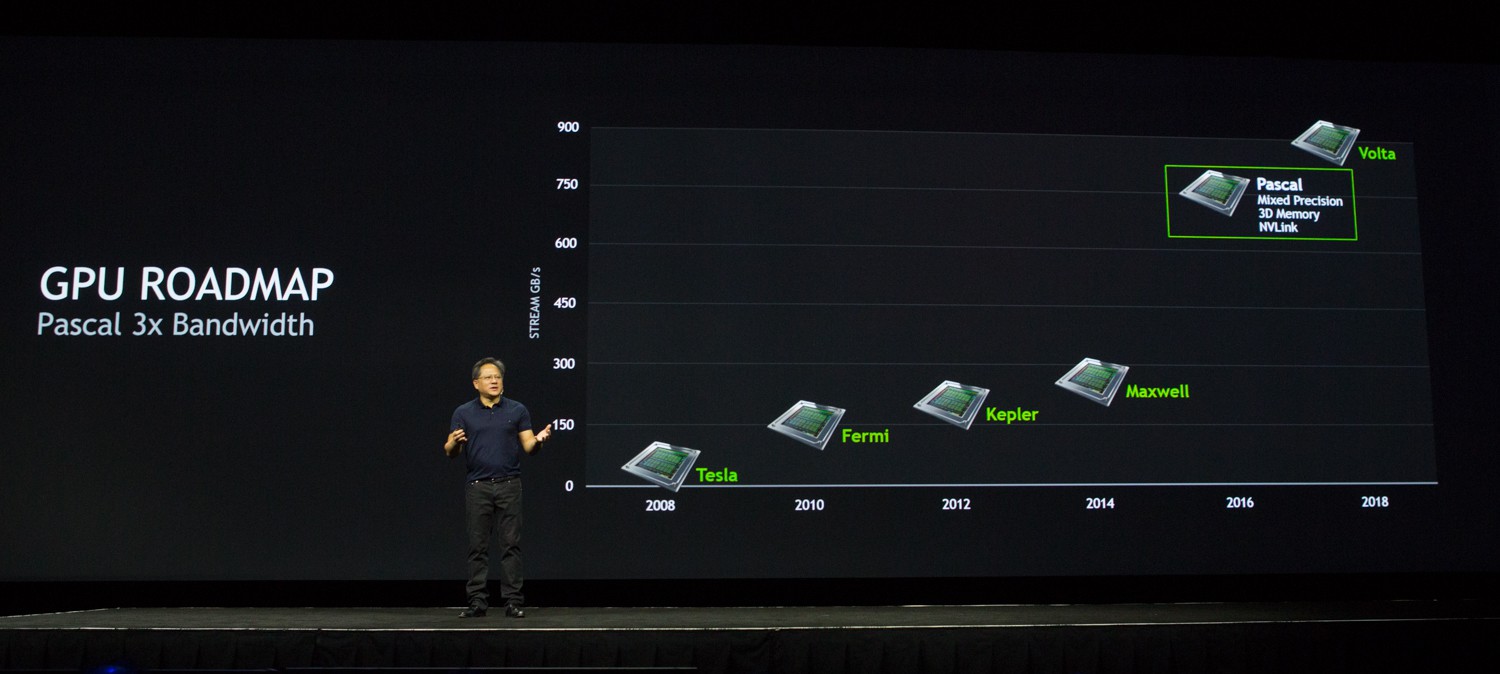
The tech behind the TESLA P100: Pascal
Pascal is NVIDIA’s next-generation GPU. Its main features include stacked (3D) memory, NV Link, and Mixed Precision processing. From a visual effects/post standpoint, the key features are the stacked memory and NV Link.
While PCIe is fast, this bandwidth doesn’t measure up when compared to the speed at which the CPU can access memory. This bandwidth can become even further limited if systems use a PCIe switch, which can occur in multi-GPU systems. NVLink is a new high-speed interconnect for CPU to GPU and GPU to GPU communication, intended to address this problem. Co-developed with IBM, NVLink can hit speeds of between 80 and 200 GB/sec of bandwidth, providing very fast access to system memory. It is also more energy efficient in moving data than PCIe.
Stacked memory allows much more memory to be on-board and accessible to the GPU. While the bandwidth of the memory on a GPU is greater than that on the CPU, there simply isn’t enough memory on the GPU for many of the tasks needed in vfx and post. NVLink not withstanding, moving data from the GPU to the memory chip on the card is inefficient as the card itself has speed limitations due to its size and it actually takes (relatively) considerable power consumption to do the move.
In Pascal, the solution is to move the memory and stack multiple memory chips it on top of the GPU on a silicon substrate (a slice of silicon). They then cut through the memory, directly connecting the memory to the GPU. This will solve having to get memory off the actual GPU chip and onto the surrounding board. The new architecture has three times the memory bandwidth of Maxwell, which should be close to hitting about 1TB/sec. That’s welcome news for our industry.
As far as expected speed increases, Huang mentioned that the expected 12x increase in performance for Pascal is even greater than what they expected. For most visual effects/post/graphics purposes, we won’t see as dramatic an increase since much of this speed is due to improved mixed precision general purpose processing (FP16/FP32) — though sims and other processing tasks could see increases. That being said, the 3D memory can provide a 6x increase and NV Link provides huge speed increases as well — so expect to see a significant increase in performance.
As far as specifics, the P100 has the following tech specs:
- 5.3 teraflops double-precision performance, 10.6 teraflops single-precision performance and 21.2 teraflops half-precision performance with NVIDIA GPU BOOST™ technology
- 160GB/sec bi-directional interconnect bandwidth with NVIDIA NVLink
- 16GB of CoWoS HBM2 stacked memory
- 720GB/sec memory bandwidth with CoWoS HBM2 stacked memory
The GPU will initially be available in the NVIDIA DGX-1 and available for other server manufacturers in early 2017.
The NVIDIA DGX-1

Huang announced the impressive NVIDIA GTX-1, a high performance workstation with the debut of the P100 forming its core. The $125,000 turnkey rack system has eight Tesla P100 GPU accelerators that deliver up to 170 teraflops of half-precision (FP16) peak performance, effectively the equivalent of 250 CPU-based servers.
The system aims to provide incredibly high performance for computationally-intensive deep learning and artificial intelligence learning and training. Initial manufactured units will be shipped to university researchers around the world, including Stanford University, Oxford University, Carnegie Mellon, the University of California at Berkeley, and others.
The server provides incredible speed-ups for research, as Huang compared a Dual Xeon system with the GTX-1, noting that a benchmark AI Alexnet train time would drop from 150 hours to two. Due to the fact that all the compute is kept within a single piece of hardware, network and connectivity bottlenecks are dramatically reduced — bottlenecks which can seriously limit the performance of chaining multiple CPU systems together. The previously mentioned NVLink tech also dramatically increases performance, allowing much higher bandwidth communications between the GPUs in the system.
Otoy: Octane 3 Release + Version 3.1 & Beyond Revealed
OTOY’s Jules Urbach has presented at the NVDIA GTC for the last several years, which makes total sense considering the company’s investment in developing for the GPU. Last year, Octane 3 was announced and this year he revealed details regarding its release.
OctaneRender 3 will be available May 15th at a price of $399 for existing customers, and $49 for customers upgrading from OctaneRender 2.x. In addition, the release marks the debut of OctaneRender Cloud (ORC), OTOY’s on-demand cloud rendering service which runs on Amazon Web Services, Azure, SoftLayer, and even OTOY’s own servers. ORC is available on a subscription basis, starting at $9.99/month for 1,200 GPU minutes. The service includes file versioning, HTML5 browser access for app access in the cloud, as well as Dropbox and Google Drive integration for file transfers.
According to Urbach, users can take advantage of between 20 and 2,000 GPUs for their jobs, but the best price-to-performance ratio for the $9.99/month level is using 20 GPUs, which provides OctaneBench performance of around 800.
Cloud rendering is effectively a one-click operation and can be monitored on a per-job basis via a web page view. There is an initial full data sync from a local machine to the cloud, but for revisions, only changed assets are uploaded to the ORC services instead of the full setup. In addition, with ORBX versioning, users can revert to a previously uploaded version of a snapshot sent to ORC.
Moving forward, OctaneRender 3.1 is targeted for a summer release and aims to include the following:
- Native plugin ecosystem: OctaneRender will enable easy loading of plugins through ORBX modules that continuously update the host application with new features. New plugins will also enable support of different shader languages beyond OpenSL, including support for Nvidia’s Material Definition Language (MDL).
- Native support for bone and skin animation: New functionality in OctaneRender 3.1 adds native bone and skinned mesh support for fast character animation and glTF support in ORBX scenes.
- CPU support: For those systems that don’t have an Nvidia GPU, Octane Render 3.1 will include fallback support for CPU rendering.
The CPU support is the first use of OTOY’s new CUDA-cross compiler for non-GPU based systems. It won’t be fast, as Urbach noted that a 20 core Xeon system will be slower than NVIDA’s GK104 chip.
Moving forward, Urbach revealed plans for Octane after 3.1, with the main bullet points as follows:
- OctaneEngine, a new way to enjoy the latest Octane technology: In addition to the OctaneRender standalone application and OctaneRender Cloud, OTOY will introduce OctaneEngine, a new subscription-based offering that provides new flexibility and functionality in content creation. Features include:
- Network rendering: OctaneEngine will enable users to use other GPUs on the network to complete rendering tasks.
- Octane as a service: OctaneEngine can be run on any system in a network and deliver functionality to Octane plugins without requiring a GPU on the local machine. For example, a workstation without a GPU could run the Octane plugin for Autodesk Maya and complete renders using the GPU of the workstation that hosts OctaneEngine.
- Asynchronous rendering: OctaneEngine will enable the ability to set multiple renders in the background that can be cued for use as needed.
- Web API for new Octane-based services: OTOY will be exposing a Web API around OctaneEngine enabling new types of web services and applications to be created using standards such as WebGL.
OctaneEngine will be priced at $19.99/month, with the same features as the standalone Octane or render slave. There will also be a $9.99/month price point, which limits Octane to 2 CPUs. OctaneEngine plugins will be priced at $9.99/month, with bundles or suites of 2, 3, or more plugins priced at $19.99/month.
Additional future plans include:
- Brigade’s high-speed real-time path tracing will be coming to OctaneRender: OTOY is listening to the community and integrating Brigade’s revolutionary real-time path tracing technology into OctaneEngine. Using the OctaneEngine API, content creators will be able to produce completely interactive, photorealistic 3rd party game engines.
- OctaneImager, a powerful post-processing and compositing application: OTOY is responding to the community’s requests to do even more with Octane with the creation of OctaneImager, a new post-processing and compositing application designed for exceptional quality and speed for use on its own or paired with OctaneEngine. Features include:
- Standalone ecosystem: Just as OctaneRender and OctaneEngine will continue to have plugins that enable new features and functionality, OctaneImager will support its own plugin ecosystem for effects such as toon shading or other advanced post-processing techniques.
- Bringing the best of OctaneRender into OctaneImager: Elements of OctaneRender such as light field rendering and high-speed decoding will be exposed in OctaneImager enabling broad support for VR workloads, foveated rendering, and content that will support new kinds of displays.
- New compositing tool chains when combined with OctaneEngine: By combining OctaneEngine and OctaneImager, artists will be able to build entirely new compositing tool chains that enable layers powered by OctaneEngine and composited by OctaneImager on the fly.
- Broad cross-platform support: Using OTOY’s CUDA cross-compiler, OctaneEngine and OctaneImager is expected to support all possible CPU and GPU devices and platforms, including support for Mac platforms, and AMD GPUs.
NVIDIA VR Ready Program

Anyone who has looked into the HTC Vive or Oculus Rift understands that using a VR headset requires a certain level of hardware investment. To that end, NVIDIA has introduced their “VR Ready Program”, which aims to ensure that a PC comes equipped with hardware to handle VR with adequate performance.
Running VR on mobile platforms has been problematic, due to the heavy requirements on the GPU. To this end, NVIDIA’s Quadro M5550 GPU, which has 8 GB of GDDR5 and 2,048 CUDA cores with a memory bandwidth of 211GB/sec was announced. It makes it the world’s fastest mobile Quadro GPU, with performance similar to the GTX980. The previous high end mobile GPU, the Quadro M5000M, has 1536 cores and bandwidth of 160GB/sec.
The MSI WT72 is the first NVIDIA VR Ready professional laptop, utilizing the new M5500 GPU. The laptop is being used throughout the VR Village here at GTC and the performance for gaming and other VR content is at a level that hasn’t previously been seen in a laptop.
Redshift
Last year at GTC, we were introduced to Redshift, makers of a new final frame GPU-based renderer. This year, Robert Slater VP Engineering, and Panagiotis Zompolas CTO & Co-founder, were back to provide updates on what to expect moving forward. What is interesting about the team is that their background is in games, with the realtime GPU rendering requirements inherent in the medium. Instead of approaching the problem of GPU rendering from a production CPU renderer perspective, they come at it from the GPU at the start.
The aim is to create a final frame production ready renderer that Slater says “brings the flexibility of biased CPU rendering to the power of the GPU.” They have a flexible material system, multiple biased global illumination modes for diffuse bounces and caustics, and have full sampling controls for cleanup of noise.
We’ll be posting an in-depth technical article covering Redshift and its features in the coming weeks, but here are some of the features included in Redshift 2.0, which aims to close CPU-GPU feature gap:
- Multiple Dome Lights
- Baking light-maps
- Improved model for sub-surface scattering
- New shading technology
- Introducing a new, improved, Redshift Material
- GGX & Cook-Torrance BRDFs
- Physically-correct Fresnel
- ‘alSurface’ (Arnold) shader emulation
- Ray marched volumetrics (Open VDB, etc)
- Automatic VRAM management
- Custom AOVs
- Per-light AOVs
- Ray-traced sub-surface scattering
Moving forward past 2.0, the team is looking to the following new features and improvements. A key goal is to bring Redshift to more applications. Their 3ds Max plugin is almost completed, with a Houdini alpha imminent and a Cinema 4D alpha coming out in a few months. They are currently evaluating support for MODO and Katana, noting that Katana support has been requested by many large facilities around the world.
In addition, some bullet points of what they are working on:
- A shader SDK
- Toon shader
- Distributed/remote rendering
- Optimized particle rendering
- Custom per-object shading properties
- Trace sets
- Barndoor lighting
- XGen instances
- Maya curve support