Performance driven facial animation is an increasingly important tool. One can aim to map based on direct point correlation or via a system that relies on an intermediate blendshape and matching system, with tracking leading to similar blendshapes in source and target models. This is conceptually simple and becoming available widely as a tool to help animators. Coupled with markerless capture via depth sensing with inexpensive cameras, animators today can move from just a mirror to explore an expression at their desk to a 3D real-time digital puppet, inexpensively and with almost no lag.
Faceshift is a product that allows realtime facial animation input or digital puppeteering via input from a number of different depth cameras onto a rigged face. There have been several versions of Faceshift, and this is an area with an active research community, with several recent SIGGRAPH papers, but Faceshift is one of the most popular commercial solutions on the market today.
Watch a demo of Faceshift by the author, including the training phase with FACS-like poses and the real-time tracking stage with different animated characters. Note, there is no sound in this video.
Faceshift core technology goes back to the papers Face/Off: Live Facial Puppetry (Weise et al, 2009) and Realtime Performance-Based Facial Animation (Weise et al, 2011), these were both lead by Dr Thibaut Weise, today CEO of FaceShift.
The idea of a digital mirror that mimics one’s face was used recently by the team at ILM with their nicknamed ‘monster mirror’, to allow Mark Ruffalo to see his performance in real time in his trailer as he prepared for the latest Avengers. While the ILM system is not using Faceshift, they share some conceptual overlap. Actually, Hao Li, now at USC, was a researcher at ILM and helped develop an earlier system than the one Ruffalo used, and he was also one of the researchers in the genesis of Faceshift, working with the team before they formed the company . Today Li contributes to research in this area and is presenting several key papers at SIGGRAPH (see below). The main difference between the newer research and the product Faceshift is the issue of calibration and vertex tracking (see below).
Faceshift has published on Calibration Free Tracking (Siggraph 2014, Sofien Bouaziz). But for Faceshift’s CTO Dr Brian Amberg points out from their point of view “calibration free tracking is not as accurate as tracking with calibration, because the resulting muscle signal is much cleaner, there is less crosstalk between muscle detections and the range of the activations can also be determined”. Faceshift’s professional product line therefore calibrates, though one can also simply scan based on a neutral expression, which will result in pretty good tracking results as is and they claim “already on par with the ILM method”. A second difference between the system from Hao Li (see below) and our Faceshift is that they offer both an online as well as offline solution. This allows for a “refine” mode, which creates “higher quality animations offline, by taking the past and future into account. That is an important feature of Faceshift, that makes a difference for the studios”, Amberg explains.
These two research streams work are not an island, others have successfully shown systems at SIGGRAPH that respond to any face and learn as one uses it, and some of this research accesses huge online facial databases to help solve calibration, and other approaches such as Bouaziz, Et Al. 2013 use a dynamic expression model or DEM.
The Faceshift approach has a more deliberate calibration stage, but the results are remarkably good, and like nearly all of these types of system, they use a completely markerless approach. With the cost of cameras that include depth (RGBD) now so low, it is hard to imagine a host of companies not all wanting systems for their animators.
We test drove the system with two RGBD cameras, – the new Intel depth scanner, the Intel RealSense, on a PC and the Structured scanner, PrimeSense Carmine 1.09, on the Mac. The Kinect also works but not quite as well. Faceshift works equally well with both RGBD cameras we tested and on both platforms.
Stages
There are 3 main stages after a facial animation rig is made and set up for driving the rig.
1. Calibration (setup)
The setup only needs to be done once per camera and is saved. This stage lets you modify the depth volume and other key aspects.
Here you can see what the sensor is seeing as a depth map, a surface, a textured surface or as just a video camera, (some camera sensors also have infrared such as the intel RealSense and one can view that here too). The primary thing to get right here is the depth cutoff and make sure the color data is aligned correctly.
2. Training
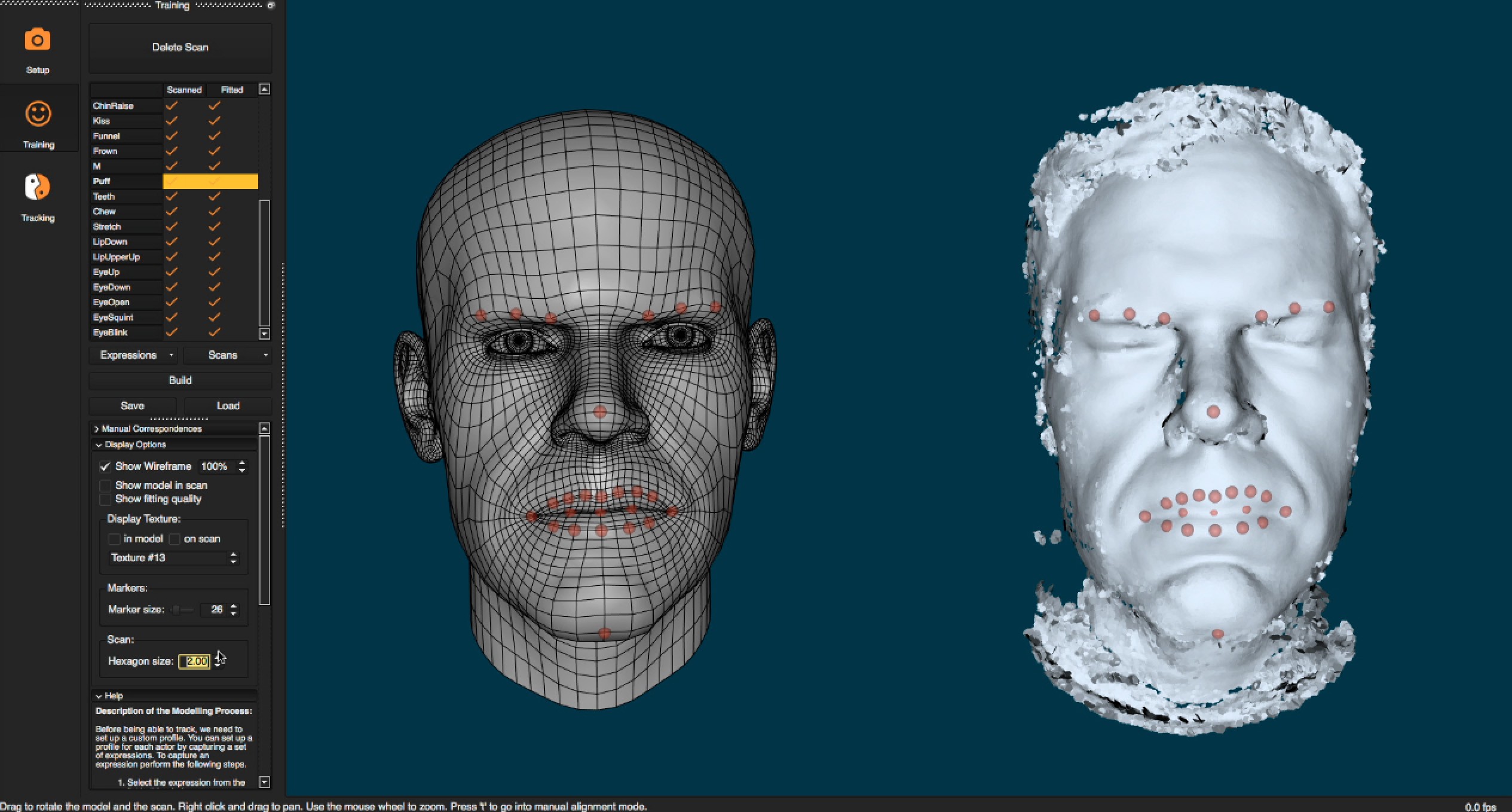
The user sits in front of the camera and runs through a series of FACS style poses rotating one’s head left and right for a good 3D capture. There are about 29 poses, such as eyebrows up, jaw right, jaw left etc. In each case the system is building a point cloud of your face in this key pose.
This needs to be done just once per actor, and their custom profile can be stored. Assuming the camera is setup correctly, this second stage tries to help the performance solve by understanding the key poses on this particular actor’s face.
While the training is running, system is helpfully showing you a guide head doing each pose so it is easy to understand what to do, and each pose does not take long to perform. At the end of the example poses you BUILD the custom profile. Once you are done this generic head is bent and modified to better match your head. If your jawline is more prominent or your forehead more rounded then the base mesh is modified to match an aggregate version of you based on the 29 x 3D scans.
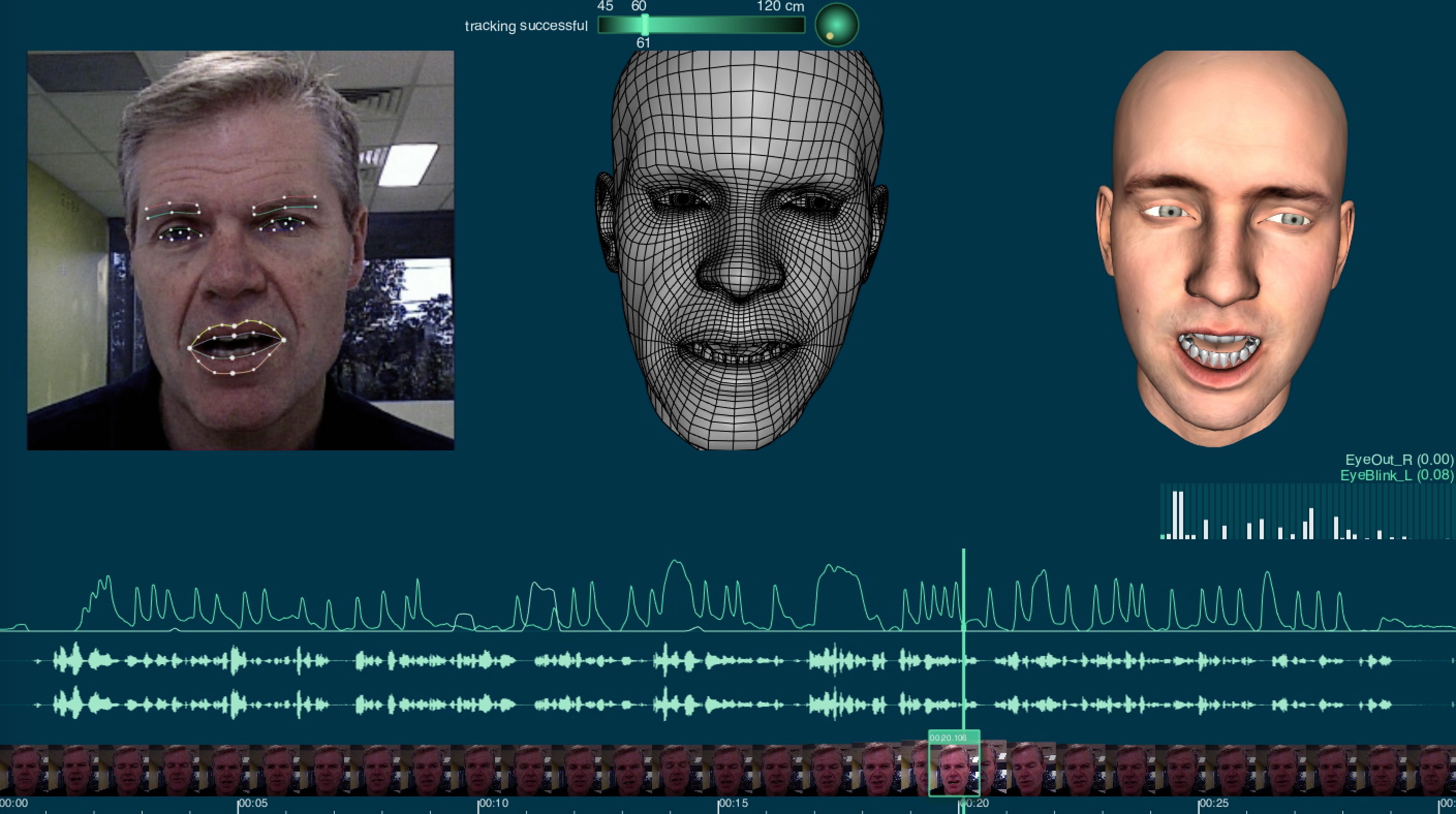
3. Tracking
Once you have completed the first two stages you are ready to be tracked in real time and for a target 3D version of you to be rendered as you watch. Clips can be recorded, but the system works in real time with little lag and can retarget your performance to any 3D rigged face imported into the system (that conforms to the spec) and if you don’t have one, a few are provided free to get started.
Once you are done capturing the performance, you can export the animation, the modified generic head or tweak the values and refine the re-targeting.
Faceshift solves, calculates and exports:
- head pose (position and rotation of the head)
- gaze direction (how the eyes are rotated)
- blendshape activations (weights between 0 and 1 that describe how strongly each of a large number of basis expressions, eye shapes and mouth shapes is activated)
- marker positions (the 3D location of arbitrarily chosen virtual markers on the face)
- a custom Avatar (the modified generic head)
- recorded video / audio clips
The data can be exported live if you wish to feed it into a more advanced motion capture display system, and Faceshift have shown mobile rigs mounted on chest and head rigs using stripped down camera sensors.
How it works
The way the system works is matching your facial position, identifying key facial aspects, mouth eyebrows etc, and then matching those to the trained modified generic head. As the system solves what you are doing it can then immediately feed the animation blendshape instructions to the rigged animated character face. In a sense it knows how to map anything the generic face does to the target model, so what it needs to do is the start of the process…it needs to understand and track your face to the generic modified face.
As the input is not a 2D web cam but an actual depth mapped face and a color video feed, the software does a remarkable job in tracking the face. This use of an RGBD sensor camera is key to the process, and vital to the whole system operating at a level above typical off the shelf video-only face tracking solutions. As the sensor cameras are now around $100 the cost of having one is no longer prohibitive, and exceptionally worthwhile. Faceshift supports a range of camera sensors but the two we tested are two of the most recommended models.
One great advantage of the Faceshift system is that it also has eye tracking built in. Eye positions are detected in the start of the posing (in the neutral position) and then works automatically. The Faceshift team recommend against over training the system in the eyes unless you have a problem as the standard quick approach seems to work best. But if there is a problem you can manually adjust it in the training stage and rebuild the face.
As the sensor-cameras are using structured light and infrared, the system works well in less than perfect lighting, even in lower light or contrasty situations you can get great results, but the video for then editing your performance may be hard to use as an accurate tool for tweaking. The main thing to avoid is strong direct sunlight as it will trip up the infrared sensors. Of course normally you would seek uniform even lighting without strong hot spots from close lights.
Ideally the actor should be about 30 to 60 cm from the sensor – closer is better but the guides on screen make this clear.
When you match say a sneer or a jaw movement it is best to match to the example one as best as you can, later it is possible to go off model and manually enter values greater or less than the zero to one range, but at the time of training, sensible matching works best.
Editing the data
There are a couple of key ways to edit the data, it is possible to improve or adjust a tracked point, this would be perhaps a misalignment between where you can see a point is and where it should be – just for that part of the track. This can be easily edited on screen.
One can also adjust how the tracked data relates to the face itself, here the adjustments will have broader affect. If the lips on your digital character are not closed when your live action lips are closed, this adjustment will fix it for all closed mouths by better matching your expression to what is seen on the model. This is done by editing manually the correspondences.
You can also adjust the alignment of the scan to the total head, The alignment tool works well, but an actor will be tilting leaning and rotating their head and so sometimes you can drag the whole scan to better align it with the modified generic head the system is trying to align with.
When reviewing the animation there are lots of options for locking the head, locking the neck or rotating for a different or closer view. You can watch the input, the input with overlaid tracking points, the modified generic head, the scanner point cloud or depth map and of course the final animation output. The UI is simple but flexible and shows a healthy dose of user input and refinement as one would expect from a product that has been in the field now for a couple of years.
The system works as a stand alone or as a plugin to Maya or Motion Builder and there is also a Unity3D plugin.
Making a face
The process above is easy and while the editing to tune a performance can involve some work, thanks to various off model limiters in the software and dampening filters – most sessions work immediately and without fuss.
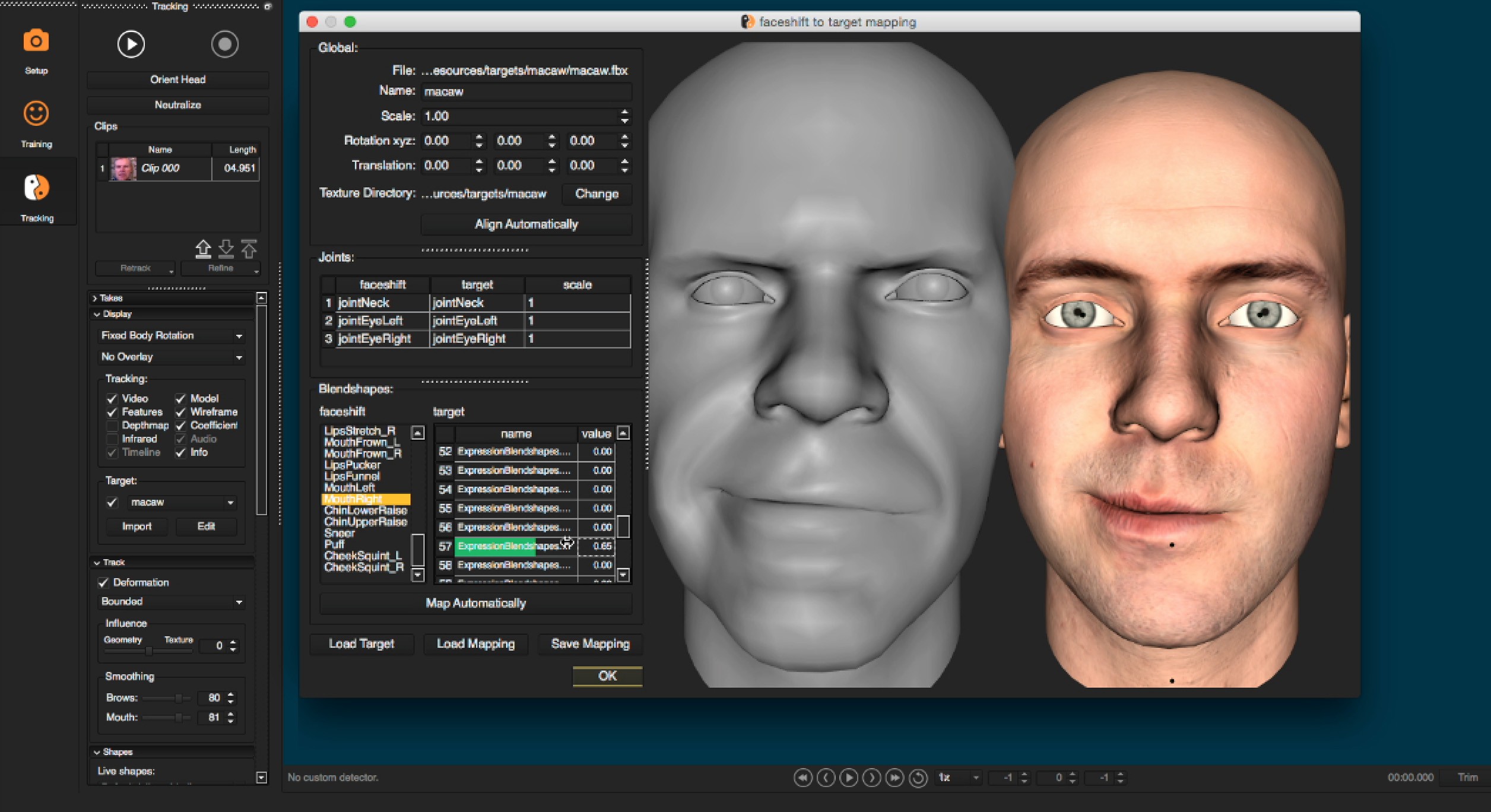
To get the system to work with your model you need to make sure it conforms to the SDK requirements of Faceshift. The company offers an open source rigging toolkit for Maya, which makes it relatively easy for a 3D modeler to turn a face model into a Faceshift compatible rig.
For a character you already have you will need to create a mapping from the Faceshift studio actor face to your character. The mapping can be saved, and Faceshift studio will automatically list all imported target characters where the created mapping file resides in the target directory of the workspace.
Start by loading the FBX file of your character. The system is driven by blendshapes but head poses and eye gaze are defined by joints in the actor’s face. In order to map these to your own target character, your rig also needs to have the corresponding joints. If you don’t map say a neck joint, then head pose will not be mapped onto your target character.
For each of the blendshapes of Faceshift’s system, you select and activate the corresponding blendshapes on your target character. One blendshape in Faceshift may be mapped to multiple blendshapes in your target character and vice versa.
If the blendshape names of your character match the ones used by Faceshift studio, the button Map Automatically will automatically assign them.
You can use any Maya file (ma, mb or fbx) as a template reference as long as it contains a blendshape node. You have the choice to use the default Faceshift template or reference your own custom blendshape to use as a template. Using a template provides you with useful comparison information with your blendshape allowing you to see easily what shapes are missing of misnamed.
Having modified your rigged face you can now open it in Faceshift with a profile and drive it in real time.
Conclusion
The only problem area for getting your Faceshift rig working is the process of modifying your existing characters to the requirements required by Faceshift. It is possible to rename all the blendshapes so that Faceshift can just load the character fairly automatically but for pre-made characters you will need to have a TD or yourself invest some times getting a rig prepped.
But once you import your face (or open a free sample) – this system is so much fun to use. The results are great and the ease of using it to explore animation ideas is incredible. For a project of any size I cant imagine not wanting to have rigs available to animators. There are limitations, one Faceshift will not magically carry you all the way across the uncanny valley, but it made the amount of work to get a character to come to life dramatically less, and it captures the timing of performances with great fidelity. We have tested a few systems and Faceshift seems like a ‘no-brainer’ winning tool.
Hao Li
Hao Li is currently Assistant Professor of Computer Science at USC. He has been working on faces for over five years. Prior to USC, Li was at ILM and before that in Switzerland at ETH Zurich, but he has consulted to Weta, Columbia University, Princeton, Oculus VR, Adobe and even toured giving face lectures in Sydney at the VIVID arts festival.
With 3D sensing being democratized, Li believes that we are moving towards more and more unobtrusive yet believable 3D digitization and analysis of humans, and faces in particular. His current research focuses on data-driven methods for dynamic shape reconstruction, real-time facial and body performance capture, 3D hair acquisition, and garment digitization.
He was named one of the world’s top 35 innovators under 35 by MIT Technology Review in 2013 and won the Google Faculty Research Award in 2015, the Swiss National Science Foundation fellowship for prospective researchers in 2011, and the best paper award at SCA 2009. In short, he is one of the world’s leading researchers on performance driven facial animation.
Hao Li’s work is different from that of Faceshift, as it is research not commercial software – although he is first to point out that Faceshift is “wonderful technology for creating content”. His research work forked from Faceshift before his time at ILM, and whereas Faceshift’s work is based almost entirely on blendshapes, his work today is more in line with some of the Disney Zurich Research and newer ILM R&D which tries to track the face as accurately as possible and not just use blendshapes, while “also trying to solve for the position of every vertex, using an Laplacian deformation algorithm that runs in real time which gives you the additional ‘juice’ to make the face look fleshy,” he comments.
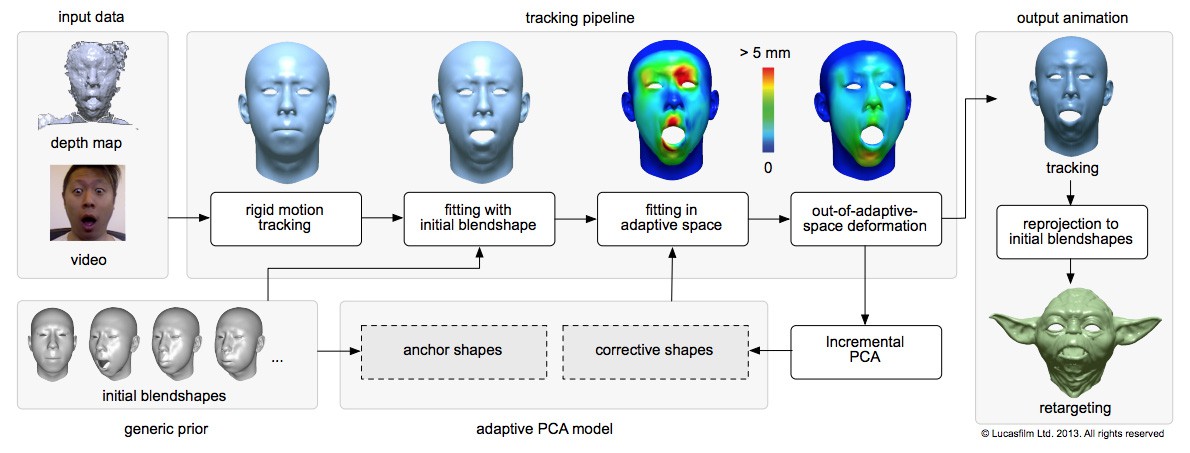
Li’s normal face pipeline is calibration free and uses an adaptive Principal Component Analysis (PCA) model with shape correctives that adjust on-the-fly to the actor’s expressions through incremental PCA-based learning. (Or in lay terms it uses some maths called PCA to help align the video ‘face’ to the model: so it’s special alignment maths + blendshapes). The ILM 2013 system required only a static neutral pose to start a session. Since the fitting of the adaptive model progressively improves during the performance, they did not require any extra calibration. The theory being that other systems are more confined to the ‘learned calibration poses’ and while they generate plausible results they are not as accurate in their tracking.
In the 2013 paper Li and the then other ILM team showed that the combination of dense depth maps and texture features around eyes and lips was particularly important in capturing natural dialogues and nuanced actor-specific emotions. They contended that using an adaptive PCA model not only improved the accuracy for tracking but also increased the expressiveness of the retargeted character.
“Even though video-based tracking can be used to drive 3D facial animations convincingly these methods only extract features around prominent regions (lips, nose, eyes, etc.) for a limited set of facial expressions” Hao Li, Et al 2013 Siggraph Realtime animation with On-the-Fly correctives.
The end result of all of this is that a system like the ILM 2013 system is based on just a neutral face (with no need to do FACS style expressions vs the calibration process of Faceshift), and the second thing is that “we are going beyond blendshapes and solving for vertex deformation – with a focus on eye and mouth regions because they are most important for conveying emotion or if you want to have dialogue … those are the parts that the audience cares most about,” explains Li.
This work was then updated again this year with an even more robust system that handles things crossing the face during the performance – such as a hand etc. And a newer version presented at CVPR also no longer required even the starting neutral face.
If you’re not, however, at ILM or in the research team of USC’s computer graphics department, Li points out that Faceshift is a great way to get high quality input.
At SIGGRAPH Li is publishing a set of new research on a related but unexpected front. Even through his primary research has been removing calibration in facial capture, for this first unusual application Li has had to re-introduce a calibration stage. The new paper is focused on doing facial capture – while wearing a VR display! This may seem impossible but the benefits of success could be huge. With current VR one is very isolated. Ideally a system would be developed that allows friends to join you in your VR virtual space, but for that to work one would want to see their faces.
A 3D version of your friend could be rendered today – but it would need to be either expressionless or at best a guess based on voice or some other input. Li and his collaborating researchers have worked out a way to estimate your total facial expression when only part of your face is visible to a sensor such as an RGBD camera and strain sensors in the headset.

There are currently no solutions for enabling direct face-to-face interaction between two VR users wearing head-mounted displays (HMDs). The main challenge of course is that the headset obstructs a significant portion of a user’s face, preventing effective facial capture with traditional techniques.
Li and his team have developed a new HMD modification that enables 3D facial performance-driven animation in real-time. The new system does require an initial calibration stage with the head set off but then it uses an ultra-thin flexible electronic materials that are mounted on the foam liner of the headset to measure surface strain signals corresponding to upper face / forehead expressions. These strain signals are combined with a head-mounted RGBD camera input to enhance the tracking in the mouth region and to account for inaccurate HMD placement.
To map these signals to a 3D face model, they perform a single offline training session for each person before you start. For reusable and accurate online operation, they also propose a short calibration step to readjust the system before each use. The resulting animations seem completely visually on par with cutting-edge depth sensor-driven facial performance capture systems and hence, are suitable for providing a virtual you – with facial accurate facial expression in virtual environments.
The research came about from a chat after a lecture two years ago when Oculus VR’s Chief Scientist Michael Abrash gave a talk at USC. Li asked him how Oculus would solve the face tracking problem when people have headgear on. Abrash was impressed with Li’s initial ideas on the project and together they decided to research the problem.
The key is the strain gauges which can feed into the calibration stage data, those gauges give an indication of skin stretching which then is solved with the original calibration. Clearly with the face blocked during VR operation, the system cant “learn as you go”.
Oculus is owned by Facebook, and central to Facebook is the social side of social media, yet the great majority of VR projects are either filmed or of environments where you the viewer stand apart of the actions of other VR uses. Unlike films or television we currently enjoy VR experiences by ourselves removed from the collective experience, unable to even turn to a friend and smile at a joke. This research could fundamentally change that isolation.
While the system works well, it is still very much a research project, for example one of the principal issues with any main stream VR head gear is its weight and the imbalance it places on the neck from prolonged use. Placing additional weight on say an Oculus VR head gear and sticking out at a distance for the face are all not desirable, but prior to this work the possibility of face tracking while wearing VR gear was thought impossible. It is also to be noted that this is part of Li’s ongoing research and building as it does on the brilliant work his team has done in unconstrained markerless and sensor free tracking, even with partial occlusion – this work once again advances the art of visualized presences.
From the ILM work to today, most of Hao Li’s research work relies on the newer RGBD cameras. He believes so strongly in depth sensing cameras (RGBD cameras) that he believes they will become an integral part of every computer, mobile device, and living room, all “streaming terabytes of data about us and our friends every second over the Internet. I want to build algorithms for collecting and analyzing this data, and learn how to use them to improve our everyday lives. 3D sensors give machines a human-scale understanding of space and motion. Our world is 3D, and I want machines to be able to see it like we do.”
But while Li’s work relies on RGBD, he firmly believes that with time there will be new algorithms that will allow most of his research to be replicated with just a normal RGB camera. Algorithms have certainly improved a lot in the last five years, but for now RGBD is extremely useful for 3D modeling and sampling and used extensively in performance driven facial animation.
Unfortunately most RGBD cameras have a very limited depth range. They are ideal for faces but the scanning volume does not extend to a whole room or larger. If and when the algorithms work with just RGB imagery, that would open up a whole world blind to today’s RGBD cameras. If there was a breakthrough in RGBD camera depths there would be other enormous other advantages to VR applications, such as room reconstruction and environment sensing.
While Hao Li is not explicitly part of USC’s ICT group, he also contributed to this year’s Koki Nagano et al Skin Microstructure Deformation with Displacement Map Convolution Siggraph paper, which looks at modeling stretched skin on the skin on the face, and which fxguide will be profiling as part of our Siggraph 2015 coverage.
Hao Li’s other 2015 Siggraph paper is on producing 3D hair from a single image with just some simple guide brush strokes. While not directly aimed at the VR area, clearly building a virtual avatar of a friend will require solving their hairstyle. Quick and valid hair will be a key in many applications, and Li’s research team are not just focused on any hair, but matching specific hair styles very easily and simply.
This research work is in conjunction with Adobe and Princeton University and it is a multi-year project. One of the hardest challenges that most people are not examining is accurate 3d hair matching from “as little as a random internet picture,” explains Li.
Human hair presents highly complex structures and spans an extraordinarily wide range of styles, which is essential for the digitization of compelling virtual avatars. It is also one of the most challenging part of the head to create. Most normal cutting-edge hair modeling techniques rely on expensive capture devices and significant manual labor. In this new paper the team introduces a new data-driven framework that can digitize highly complex 3D hairstyles from a single-view photograph. The system works using a large database of manually crafted hair models from several online databases. Given a reference photo of the target hairstyle and a few user strokes as guidance, the team’s software can automatically search for multiple best matching examples and combine them into a single hairstyle. It then synthesizes the final hair strands by jointly optimizing for the projected 2D similarity to the reference photo, the physical plausibility of each strand, as well as the local orientation between strands. At Siggraph during their paper they will demonstrate their method on a variety of hairstyles and challenging images, and compare their system with normal state-of-the-art hair modeling approaches.
Hao Li’s team at USC is very focused with just three PhDs and one post doc, also check out the team’s work in our fxguide story on the team’s 3d-selfies from Siggraph Asia using an Xbox Kinect.
Their paper on VR face performance capture is being presented at Face Reality. Monday, 10 August 3:45 PM – 5:35 PM, Los Angeles Convention Center, Room 150/151
There is also another relevant talk Monday 10 August 10:30am: Blendshapes From Commodity RGB-D Sensor. This talk will also demonstrate a near-automatic technique for generating a set of photorealistic blendshapes from facial scans using commodity RGB-D cameras, such as the Microsoft Kinect or Intel RealSense.
– Dan Casas, Oleg Alexander, Andrew Feng, Graham Fyffe, Ryosuke Ichikari, Paul Debevec, Evan Suma, Ari Shapiro (all from USC Institute for Creative Technologies) and Ruizhe Wang, USC.
 For more on the vertex mapping but without the need for an RGBD camera see also the paper presented on the same session as Hao Li’s called Driving High-Resolution Facial Scans With Video Performance Capture.
For more on the vertex mapping but without the need for an RGBD camera see also the paper presented on the same session as Hao Li’s called Driving High-Resolution Facial Scans With Video Performance Capture.
Graham Fyffe, Andrew Jones, Oleg Alexander and Paul Debevec (all from USC- ICT) and Ryosuke Ichikari
from the National Institute of Advanced Industrial Science and Technology.
This paper does use a set of static scans based on 30 or so FACS poses, but can work well using an off the shelf normal HD video camera. Geometry is obtained from the set of static face scans are combined with the normal HD video frames to recover an animated high resolution geometry that can be relit.