fxguide covered the incredible live demo done by the team at Epic, Ninja theory, 3Lateral, Cubic Motion and others at this year’s GDC. Audiences were stunned at the real time performance and we were keen to explore here a more in depth piece expanding upon the actual pipeline of making Senua.
This piece is also a primer for fxguide readers attending the FMX conference in Germany this week, where the key members of the EPIC Senua team will be speaking. Fxguide’s own Mike Seymour is hosting the Thursday sessions on Digital Humans featuring the EPIC Senua pipeline as well as talks by leading artists from Disney Zurich, MPC, Pixar and the latest work from the Digital Human League Research group.

Ninja Theory’s CCO Tameem Antoniades and EPIC Game’s CTO Kim Libreri presented the one of the most realistic real time motion captured and rendered humans at GDC 2016 last month, pulling together global specialists in both body and facial animation. This remarkable project came together in just 8 weeks. To achieve this the team used the most cutting edge facial rigs, latest advances in eye modeling, rendering and deep learning algorithms.

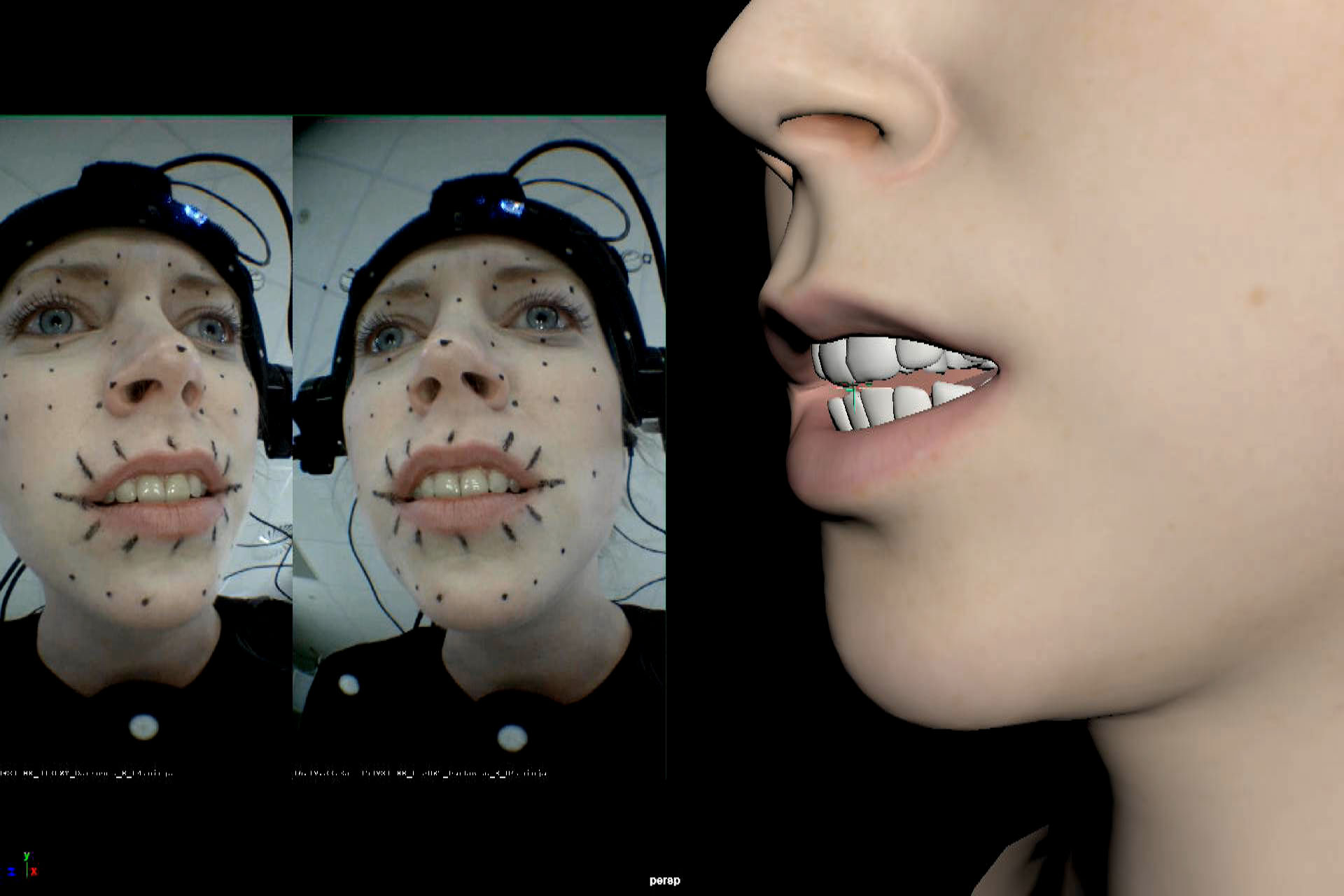
Melina Juergens, Ninja Theory’s video editor, was the model for Senua and the performance artist who drove the rig at GDC. To summarise the process, her face was filmed with a mono head camera, and her body tracked via an Xsens rig. The face data fed the 3Lateral rig via the Cubic Motion’s solver. The Body data fed the IKinema body IK system. The face and the body solutions were then combined and rendered in real time in the Unreal Engine with some custom modifications.
Input
The body data was input via an Xsens rig, feeding an IKinema solution directly into Epic’s UE4. Most of the technology for the body capture is off the shelf and takes very little time to set up.
The body solution was combined with a face that was solved by Cubic Motion’s algorithms into a complex 3Lateral Rig. The Rig had already been built before EPIC’s Kim Libreri came looking for a demo to showcase the power of UE4. The face animation is really the core of the demo, and while the body was also important in the demo, – it was the ability to have Juergen’s acting be interpreted with such fidelity that posed the greatest challenge to the team. In the end, the combined solution was very successfully rendered interactively in front of a vast GDC 2016 crowd.
Senua is a real game asset for Ninja Theory for their upcoming game Hellblade. The original pipeline was not focused on real time rendering, thus much of the demo was an adaptation of the studio ‘offline’ pipeline into a real time interactive context. Physically, the hardware of the studio/offline system was very similar to the live version except the offline pipeline uses a stereo camera head rig and it processes the data with the luxury of not needing to run in real time.

The Face:
The real challenge of the demo was in getting such a high quality face captured, integrated and rendered in real time.
Cubic Motion: the solver
Cubic Motion was a key company in making this year’s live demo facial pipeline. The company’s computer vision technology is able to track more than 200 facial features at over 90 frames per second and automatically maps this data to extremely high-quality digital characters in real-time. (Although at GDC the system was running at 30fps for the demos). Cubic Motion’s contribution was to manage the live capture and apply advanced analysis of the spatio-temporal data to drive the 3Lateral rig.

The live GDC solution was filmed with a mono camera, whereas the offline animation was captured with a stereo set of cameras. “I think there is a lot of difference between stereo and mono (for facial performance capture)” says Vladimir Mastilovic, Founder and CEO of 3Lateral. “Certain things like jaw position are much better… Cubic Motion have some very nice predictive algorithms”.
The key aspect of the Cubic Motion solver is that it has a deep learning component. The Solver learned from the stereo rig and then this informed the solutions for the mono rig. In other words, due to having a lot of offline information, the solver could understand better what Melina Juergens face was capable of doing and be more accurate in the live presentation. While one can always manually refine a rig or model, this process was more than just that. The system ‘learnt’ from one data set and then ran with greater accuracy when live, without manual adjusting or changing the face model.
The offline stereo pipeline allows artistic contributions including calibration. The first stage of learning uses more detailed data that only the stereo cameras can provide. It is then both better informed and more able to be correct if there are any problems during the live session. The live version can have no artistic interpretation or manual assistance as it has to run unaided in real time.
The key to deep learning algorithms is to have an accurate ‘correct’ or ‘solved’ data training set. To achieve this, the Stereo data was converted or interpreted into a simulated mono camera. The stereo converted virtual mono camera becomes the ground truth for the learning mono rig. This ‘virtual’ correct mono camera and its matching facial solver was then able to be compared 1:1 to the actual live mono data.
The stereo data can constrain the mono camera to sensible solves that are more accurate than they would have been without the learning. This combination of FACS and deep learning produces a highly articulated lip sync and facial animation solution. Cubic Motion uses its own non-linear solving methods to output an accurate 2D moving map, correlated into FACS space and outputting the data needed to feed to the 3Lateral rig engine.
This is significant in many respects. As we will flag in an upcoming Art of Deep Learning Story here at fxguide, this approach opens various doors in the future. For example, Cubic Motion could use this approach to address flesh sims via deep learning. Flesh sims are very expensive and tagging data sets takes effort, but at run time the computer is really just evaluating Decision Trees (or Decision Forests) and that can be done fast enough that it could be used in real time. It is also a very GPU friendly approach.

Interestingly, Melina was nervous during the actual live event and so she started singing a small song. This was never in the data training set from the stereo pipeline. Ninja Theory’s Tameem Antoniades was really surprised as to how well the renders still matched Melina. As a deep learning approach is not specific to a script but more generalised, to process did not break down.
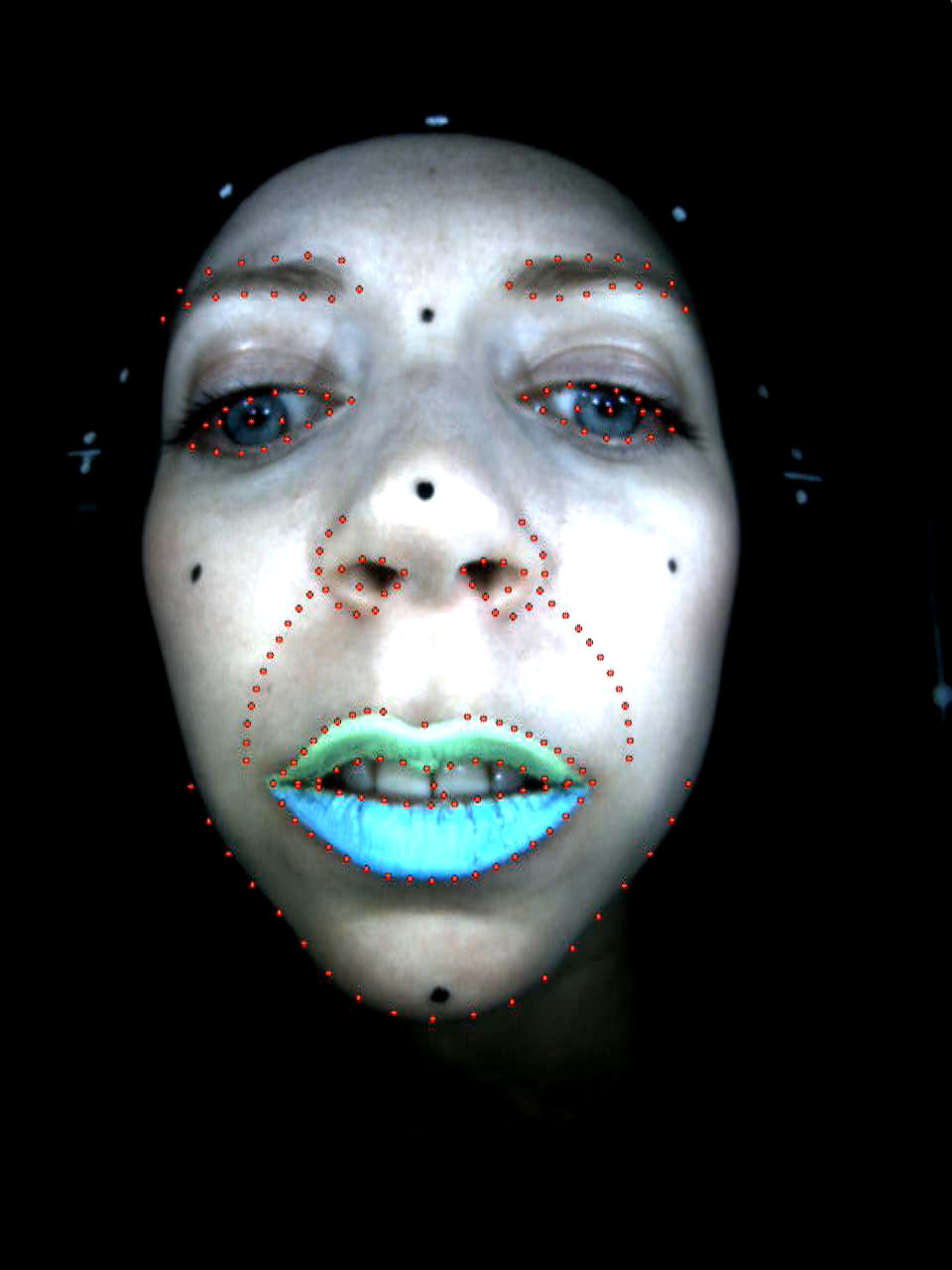
For the live performance Melina had a single head mounted camera but wore different colored lipstick to help the tracker accurate get lip sync. She also had six tracking dots on her face. In reality, the tracking dots were not really required, but more of a ‘safety net’.

Training Data : Deep Learning
Key to the process is the tracker that Cubic Motion uses. Here again training data and deep learning were used. As mentioned Deep Learning is not script dependent to only rehearsed lines of dialogue or facial expressions. However, training data defines the training space and in this regard most of the training data was around Melina’s face giving a more serious, less lyrical performance.
The training data did not seek to cover the full range of emotional performances that Ninja Theory would use in the final game, since the demo was only a few minutes long. Computationally, the solver can still extend outside a strict notion of the training space (as defined by the training data), as it is a hybrid of deep learning and a traditional facial rig. But once Melina moves away from the range of expressions in the training data, you potentially lose the same level of fidelity and confidence that one has when she expresses emotions inside the data that defines the ‘training space’. This is an important point, as a strict Deep Learning only system can only solve inside the training space.
In this project, Cubic Motion and 3Lateral inform rather that dictate the digital performance with Deep Learning approaches.

The animation was running at 16ms per frame, without post-processing.
The eye tracker is one of the key technologies of a believable facial system. The Cubic Motion team has applied Deep Learning to their eye tracker as well. For Melina’s custom eye tracker, the team took training examples of her eyes, with accurately marked positions and used this to train the tracker that was deployed in the live performance. Interestingly, this somewhat mitigates issues such as mild refraction etc, since if the training data has these properties, then the system learns to track eyes with these problems and thus they are effectively factored into the solution.
While specular highlights can interfere with eye tracking, the optics of the eye are rarely an issue. “Part of the solution is that our trackers work in the same way as our solver does with training data, so to make a tracker of Melina we would take 100 to 150 training examples of her eyes and edit the training data to make sure it was accurate” explains Steve Caulkin, Cubic Motion’s CTO “And some of that then compensates for things like specular, variation in illumination, different positions of the eyelid, and all the other interactions with the eyeball – these can all be dealt with in the training phase. You can just say ‘here is a bunch of examples of her eyes doing various things – learn to deal with that’ “.
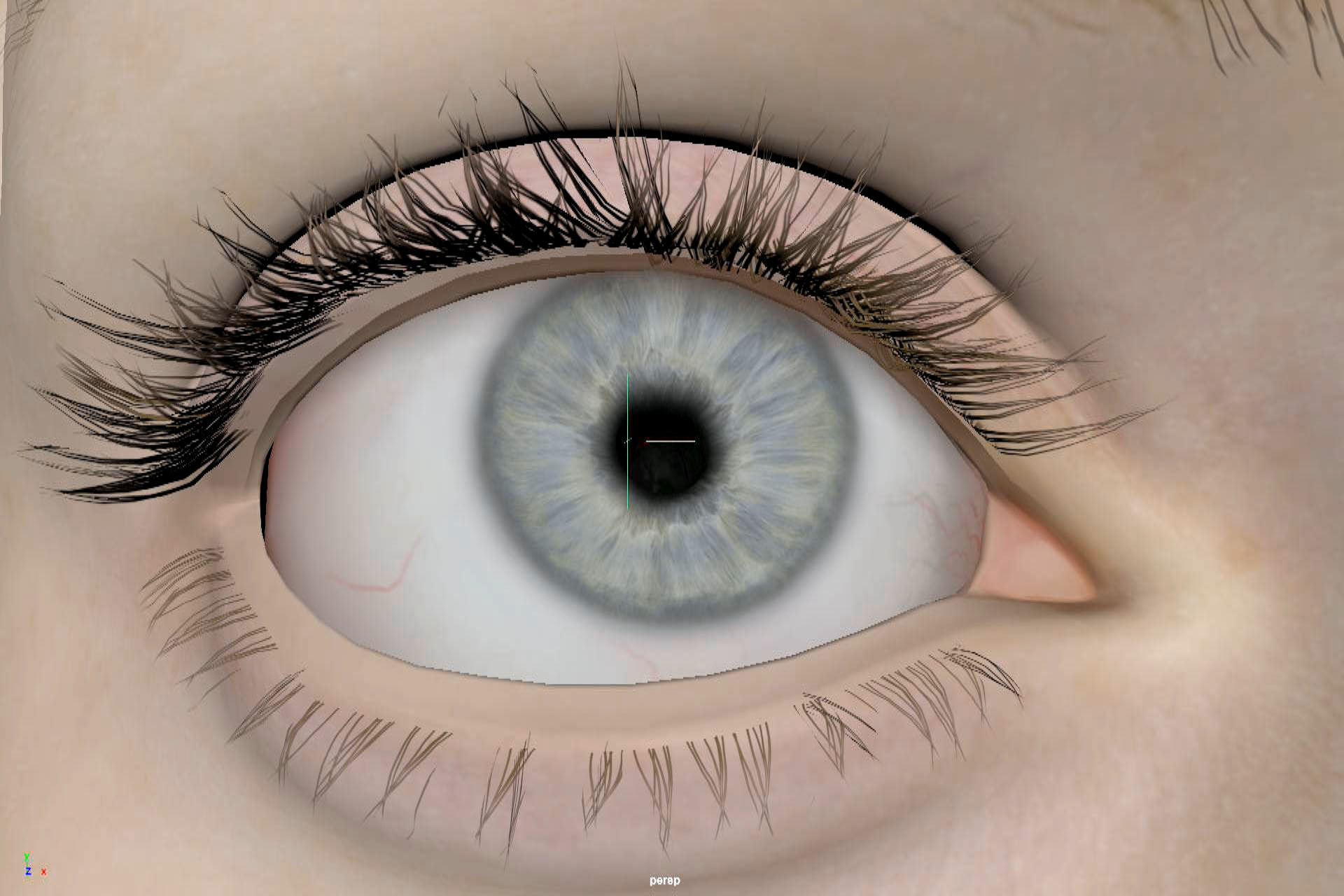
Eye tracking is standard to the Cubic Motion solution, for the GDC demo, the tracker was both modified. “We did a lot of optimization to squeeze as much out of that (eye) tracker as we could in the time available” comments Steve Caulkin. The eye tracking is key to the performance but eyes can move much faster than any other part of the face, which means one needs to be careful to not filter the data in an attempt to remove jitter, and thereby dull a performance and remove valuable high frequency data. “Ultimately, what you need is a high quality and accurate fast tracer. That is basically what we have developed. Part of our bread and butter work is analysing huge amount of video capture data and it is fundamental to the quality of the work, the analysis and ultimately the animation we produce. If your eye tracer is poor, or jitters,.. you are in trouble” he adds.
If eyelids blinking can cause problems by having the eye obscured, then tracking teeth is even hard to do as lips cover by teeth much of the time. In the offline stereo tracking work done before GDC, Cubic Motion tracked Melina’s teeth to help build an accurate jaw motion model during dialogue and performance. While the team can image process to filter out specular highlights on her teeth, – her lips cover her teeth so much it poses a very complex tracking problem for positional spatial reconstruction. Fortuitously, Cubic Motion’s Dr Gareth Edwards co-invented in 1998: Active Appearance Model, (AAM) which is one of the most widely used and cited methods in the analysis of video and medical images (used for example in the Microsoft Kinect face tracker). AAM is a computer vision algorithm for matching a statistical model of object shape and appearance to a new image. They are built during a training phase. The algorithm uses the difference between the current estimate of appearance and the target image to drive an optimization process and it can match images very quickly.
“In an offline stereo situation, if you track the teeth you have a great understanding of where the jaw is,” explains Caulkin. “In the live session you have to say we don’t have quite the same fidelity and rely on the wider track of rest of the face a bit more, – especially the jaw line”.
For this project the actresses teeth were scanned. Previously, 3Lateral used a dental case, but they have since developed a new mouth and teeth scanning system. Not only is the new photogrammetry method more detailed but it “is much less uncomfortable for the model” says Mastilovic. The new system involves a model with the real texture projected back over the geometry.
Why use a Mono Camera when Live?
All of which begs the question – why didn’t Cubic Motion aim for a Stereo pair of cameras in the GDC demo. “I think we were a little worried about making sure we could hit the real time frame rate – if we had to do a stereo solve as well,.. – we basically picked a pretty much low risk option that would allow us to build a robust system in the time we had”, says Caulkin. The team had to make a live system to work in a context of the GDC demo in only 8 weeks. The mono camera offered a lower risk solution in the trade off between higher fidelity and rock solid real time performance. In talking to the team, one gets the impression that this demo, while impressive, is far from a final solution and that over the coming year there will be even more that can be implemented to work inside the constraints of a real time system. “With GDC we have drawn a line in the sand, in terms of quality of live presentation, and it opens up a lot of possibilities … realtime previz, high throughput pipelines and I think it is already a lot better than a lot of video game animation (mid-level or background animation), … but we are really looking to push it much further into things like virtual enviornments, more persistent worlds, VR and places where the pre-canning of animation is a constraint” explains Caulkin.
3 lateral: The Rig
Vladimir Mastilovic, was responsible for principal design of the facial rigging pipeline. 3Lateral was already working on Senua for the Hellblade game before Epic’s CTO Kim Libreri approached the team with the idea of a GDC demo.
3Lateral scanned Ninja Theory’s Melina Juergens and provided both a high resolution face and Senua’s rig.
The scanning process involved proprietary techniques built over a long period of time. While 3Lateral could build a rig from externally sourced scanning data, in this case they did both the scanning and Rig implementation. Producing a point cloud photogrammetric solution of a face is not uncommon, but the 3Lateral’s software goes further to produce very accurate cohersion between frames.
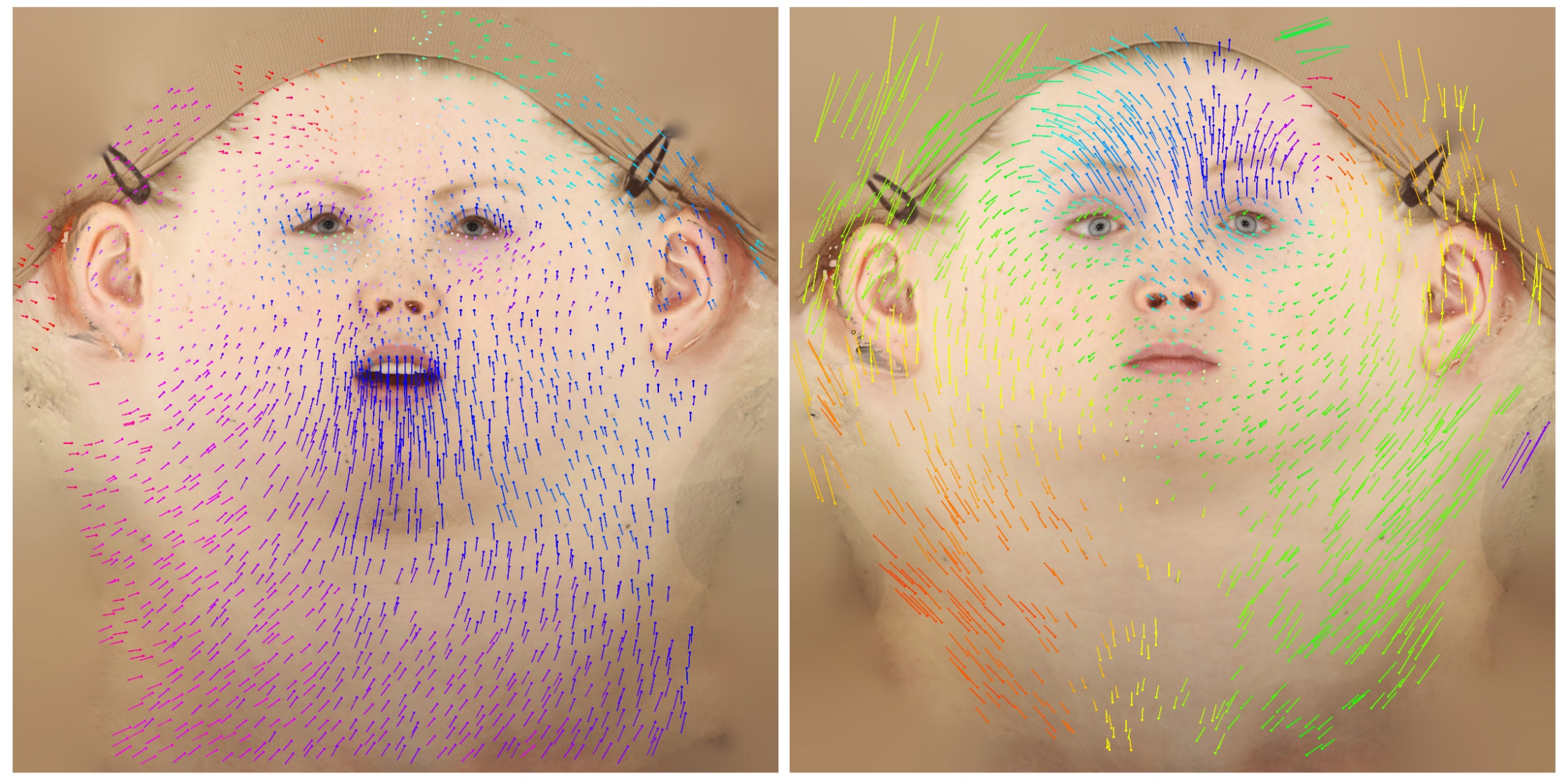
“The data is first captured. We have written software that will then help establish correspondence between individual frames”, explained Mastilovic. While the image above appears to be an optical flow, that is only part of the solution. The team also has feature metrics, such pair matching which is not uncommon in advanced facial recognition algorithms but this implementation is quite an impressive refinement and a key aspect of the 3Lateral solution. This helps with larger gaps between frames that would otherwise fail in an optical flow analysis.
The temporal consistency at the analysis and the later ‘Rig Logic’ algorithms are two critical technologies that 3lateral highlighted in their GDC presentation. The scanning technology that 3Lateral deploys has not publicly been disclosed yet but it is the third key area that leads to the quality of their work. The scanner is a 90 camera rig which produces extremely high resolution and accurate facial data. When Ninja Theory’s Juergens was scanned the team at 3Lateral had only just gotten their version 3 scanner working. Even in the short time since GDC they have added a lot to it. “It is somewhere between standard photogrammetry and a specialized system” says Mastilovic. It uses a combination of special lights and high speed (10,000 fps) photography with special machine vision cameras. Agisoft is used as a mid point in the data processing for basic reconstruction, as “we did not want to reinvent the wheel – they do a good job, – but then we have also written a number of algorithms that will extract even more information from the data that we gather” he explains.
Blood flow.
Facial blood flow was modelled on Senua, the model for the hemoglobin redistribution is a deformation sampling method. As Senua forms a new expression, the pressure from that changes the blood flow mapping. While 3lateral is aware of all the different types of blood flows – (flushed, blushing, pressure and expression) at the moment for the real time / game level implementation, the team uses a simplified model. “When you include blood flow the three dimensionality of the face is further enhanced, because there are some visual markers – around the eyebrows for example, where the blood flow tells us what areas are bulged”, explained Mastilovic.
According to Tameem Antoniades, Ninja Theory’s attitude is that character comes first and so anything they can do to make her more expressive is important. The team got the blood flow working fairly late in the demo schedule. In the actual game, if they needed to have an emotional response that would not automatically be triggered, then the team would manually keyframe it in.
Interestingly, the team also added pupil dilation fairly late in the schedule “which added quite a lot when she is looking directly at the camera” Antoniades explained. People have postulated that pupil dilation and emotional blood flow are facial aspects that people are slow to explicitly name when they are seeing them on a face. Nevertheless they are strongly registered subconscious traits and part of our evolved facial decoding of human emotional awareness brain system). Antoniades says one really notices such things when you do a side by side comparison, “it makes a massive difference and something we’d like to push”.
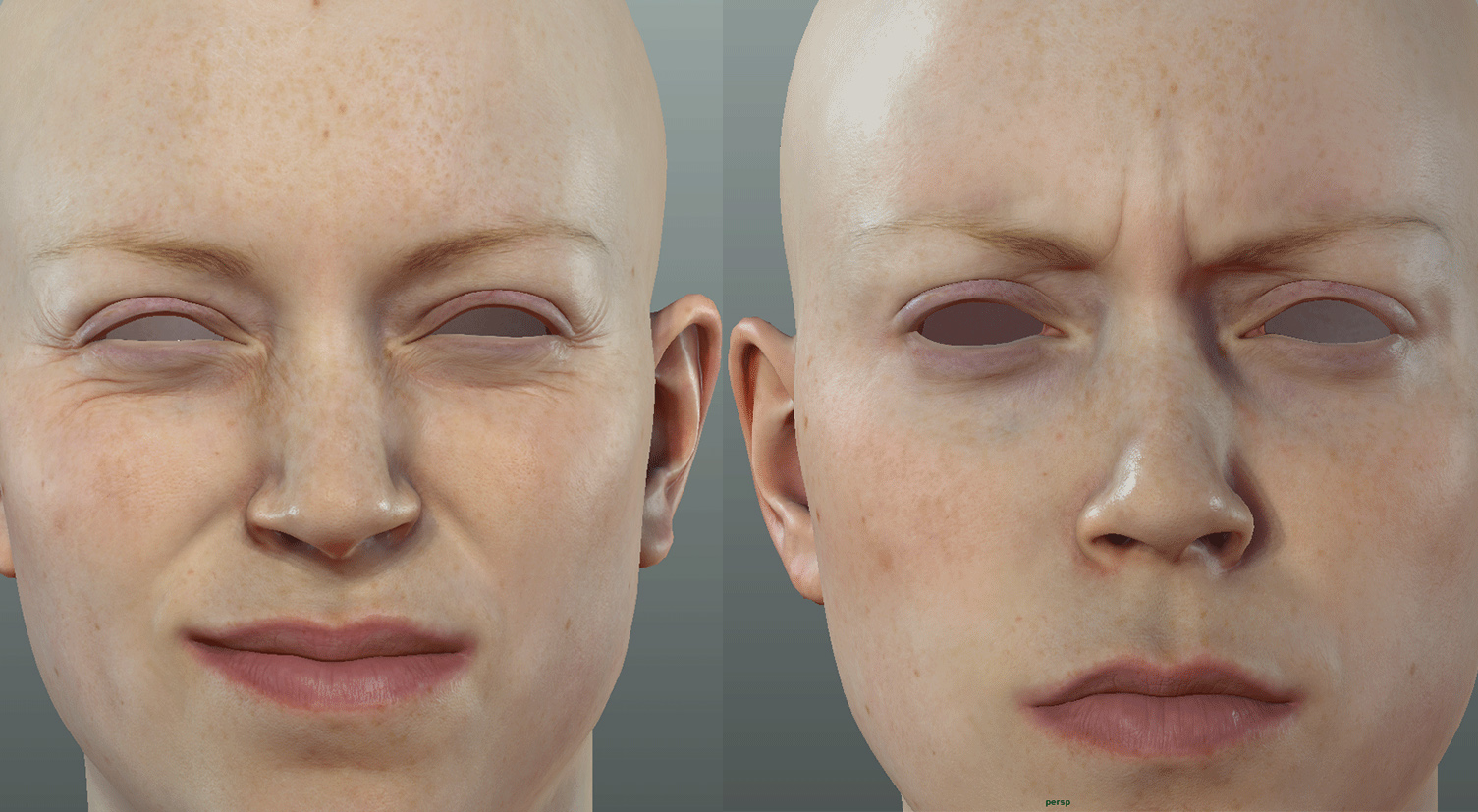
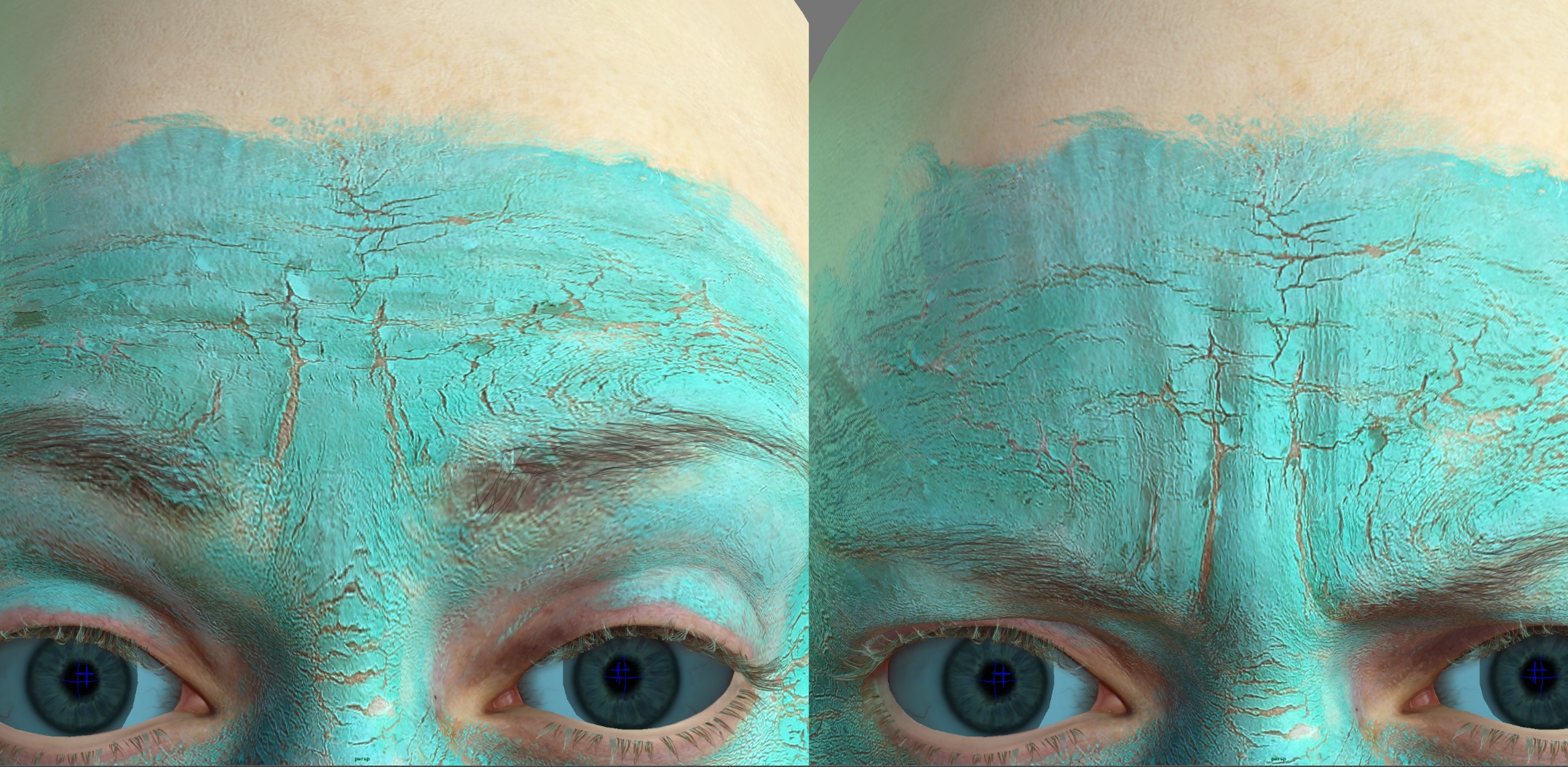
In the GDC demo the forehead is covered by paint, so the blood flow is registered on the cheeks and around the mouth. Interestingly, great effort was made to correctly get the paint cracking on her forehead, and yet even with the paint, the wrinkles are are quite evident and her expressions are not dampened. “In actual fact, the tension of the paint stretched things quite a lot more, and you see even more wrinkles in the painted area than you would on normal skin in similar lighting”, Antoniades points out. “This is something we want to continue lookdev-ing”.
As discussed above in the body capture section, the neck was something that became a key aspect that the team wanted to get right. Having improved the solve solution from the IKinema solver, 3Lateral stepped in to help address making her neck look more realistic. “The neck was looking horrible at one stage, (rubbery) and so Vlad (Vladimir Mastilovic ) did quite a lot of work getting the neck twists to look realistic” explained Antoniades. Along with the team at EPIC, the solution was a set of 3 corrective shapes for when Senua turns and looks up. And a new corrective twist node was added along with a another neck bone which can be seen in the images below:


Contextual Shape Modelling is a tool 3Lateral developed to be able to see the various face proses driven in context of other FACS (Facial Action Coding System) driven shapes. The tool that was developed for the artists allows them to nodally control and combine expressions and more particularly the muscles that are triggered for each expression or AU (Action Unit). While the scanning helps in making the movement consistent, the combinatorial expressions can differ from the isolated expression poses that are captured. A contextual combinatorial graphical UI is invaluable to keep the combined expressions believable. It allows easy adjustments for any combination or range of motions. This allows the artist to check that the semantic content of the performance is valid. In other words, is the meaning of a combination of AUs what is wanted or does the face appear to communicating something else – something other than what the sum of the parts should communicate. “By playing back the range of motion animations on the rig and tweaking the setup as you are seeing it play out on the rig,- in real time, – we think that this is really important for both production efficiency and for the end result” says Mastilovic.
Rig Logic
3Lateral have a key tool called Rig Logic. This drives the face and is running directly inside UE4. Moving this from Maya to inside UE4 facilitated the real time, low latency demo shown at GDC.

During the testing phase for HellBlade, Ninja Theory made an interesting discovery. According to Tameem Antoniades, they put Melina Juergens face on a fitness instructor’s body. This was easy as the face is separately dealt with from the body in the pipeline. Antoniades found the resulting performance much less satisfying, so much so that now he would insist on separate actors for all leads and (except in the case of re-targeting for exoitic creatures), he believes the integrity of the entire performance needs to come from the same person – and not a hybrid of various people. “In the end it is nice to have visual flaws as well as character flaws – that’s what makes it work. Heroes have to be flawed”
The fitness instructor was ‘technically’ better proportioned, with longer limbs with more visible muscle, but for Antoniades the very imperfect nature of any one person is what gives them their humanity. From his directorial point of view – only when all of Senua was coming from Melina Juergens was the character truly believable. “Never mind the uncanny face – we had an uncanny body – so we scrapped that approach right away”. He would go further and also get accurate costumes made for motion capture sessions, to inform the actors and their movement even further. He believes the best approach is a 1:1 face and a 1:1 body, -“once all the other problems are solved then maybe we can retarget more – but for now, I would avoid it.. and even when we can I would have to ask – why ? Why not use the right actor for the role?” he asks. “I think it is the flaws in the face – the flaws in the model, that make them human and I think when you see CG characters that are perfectly symmetrical – perfectly made – I think that is part of the uncanny problem -no one looks that amazing !”
EPIC Games: Unreal Engine 4
The EPIC games team build the Senua GDC demo on top of a lot of work that had recently been done for Paragon. “We started from their assets from a texture, modelling and rig perspective and we also took the work we had done – in particular Twinblast and the Paragon’s Sparrow – and ported it over – and made it better!”, explained EPIC’s Kim Libreri.
Much of what was needed to produce the GDC demo was already in Epic’s Unreal Engine 4 (UE4), but there was still some customisation.
Firstly, the team needed to have the data streaming into the UE4. The streams are those mentioned above, the IKinema data for the body and the 3Lateral data for the facial data.
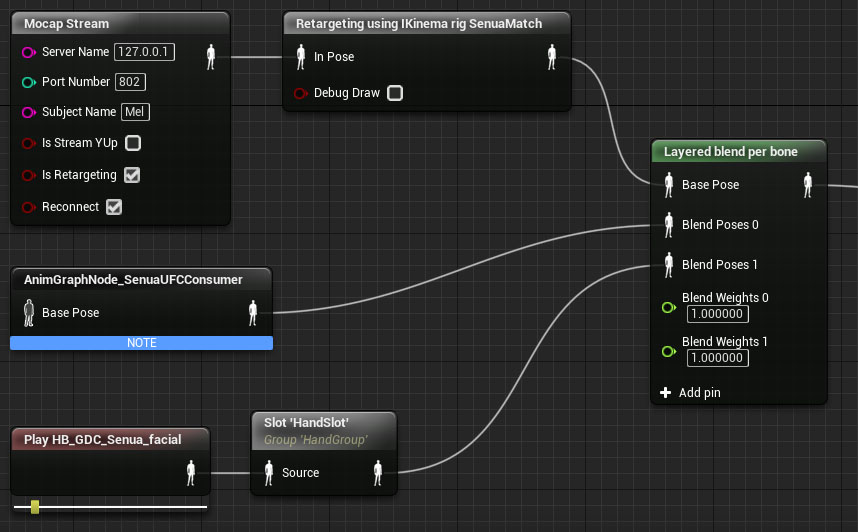
Secondly, the previously the UE4 system on faces blended morph targets normals, so the results were not as consistent in portraying the fidelity of the 3Lateral rig. With the GDC version of UE4 there is an option to actually compute the normals and the tangents in the GPU – which produces results much more like a traditional vfx or animation pipeline. “It gets a lot more of the expression out of the face than our previous system” commented Senior Graphics Programmer Brian Karis, who worked with, amongst others, Haarm-Pieter Duiker (formerly of ESC, ICT and known for his ACEScg work with the Academy).

The body of Senua benefited from a new addition to the bone driver controller. This new option drives a curve parameter based on joint angle and was used to fold or add creases in her dress when she bends.

Camera
The live demo worked with a camera move that was predetermined, but while the framing from the camera onto the virtual world was set in pre-production, the actress was moving in real time. This presented some interesting problems. Firstly, if the actress moved a bit off her mark, the team would still want to frame up to correct for this. Secondly, as the camera modelled depth of field, it would be possible for the actress to move on the day and be out of focus during the demo. To solve these two problems the team added a smart camera to track her head position and add corrective x,y,z adjustments overlaid on the primary move.
This head tracking also drove the focus adjustments on the virtual lens, keeping her face in focus no matter how she moved. The focus was so shallow at the end of the demo only her eyes and nose were fully in focus. This was feathered in so it is more influenced by her head bone at the end as the camera move.

LookDev.
Senua was tested without makeup. Below is a video test rendered in engine as a test without her Hellblade makeup.
3Lateral provided high resolution maps, normals and diffuse albedo, but there was not a separate specular highlight and diffuse sampled map as you might get from say a Lightstage scan. The team based their specular reflectance and roughness from published papers. The team did have very useful lighting and skin reference photography that allowed them to do side by side comparisons to get not only the detail right but the colour of her skin correct.

To get the small scale details the team added micro level of detail using tilting normal/roughness texture maps. There is also a cavity map to darken specular in pores and in the cracks of the makeup/war paint.
 The Sub Surface Scattering (SSS) needed to separate the diffuse from the specular, as the specular is a surface property and inherently not scattered. The SSS has been in the engine for some time, but for GDC there was a refinement. Previously, the system worked by storing RGB and a diffusion map in the Alpha channel. The new system used a checkerboard solution. The diffuse and specular are stored a checkerboard, thus at half resolution for each. The diffuse can then be scatter (softened) and then recombined by undoing the checkerboard and applying the BaseColor. Of course, all captured photo reference includes scattering so it was a matter of refining and tweaking the engine to match the reference.
The Sub Surface Scattering (SSS) needed to separate the diffuse from the specular, as the specular is a surface property and inherently not scattered. The SSS has been in the engine for some time, but for GDC there was a refinement. Previously, the system worked by storing RGB and a diffusion map in the Alpha channel. The new system used a checkerboard solution. The diffuse and specular are stored a checkerboard, thus at half resolution for each. The diffuse can then be scatter (softened) and then recombined by undoing the checkerboard and applying the BaseColor. Of course, all captured photo reference includes scattering so it was a matter of refining and tweaking the engine to match the reference.
Eyes.
The level of eyes is remarkable in Senua. Her eyes are extremely complex for realtime game engine assets. The eyeball is modelled with a corneal bulge in geometry, – they are not perfect spheres. A new EPIC eye tool allowed for control over every aspect of the characters eyes, from size and colour to specific controls for the sclera, iris, pupil, limbal ring and wetness. Parameters can be animated and driven, allowing her eyes to accurately react to the light changes in the scene.
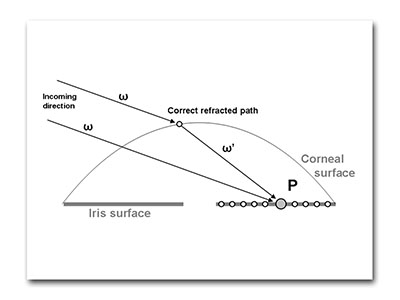 For the refraction of the eye, the texture stores the height of the front of the eyeball geometry to the center of the eye or the iris surface. This captures the refraction as a ray hits any point on the eye through the cornea. Without this the iris would appear to be on the front of the eyeball.
For the refraction of the eye, the texture stores the height of the front of the eyeball geometry to the center of the eye or the iris surface. This captures the refraction as a ray hits any point on the eye through the cornea. Without this the iris would appear to be on the front of the eyeball.
The caustics caused by the lens are actually faked. The earlier SSS approach (mentioned above) was found to not work on the eyes as the sub-sampling fights the requirement to have sharp specular detail on the surface of the eye. The checkerboard solution was rejected in preference of an energy conserving wrapped Lambert shader.

The team worked hard to connect the actual eyeballs to the face, this includes a tear line. This additional element is an extra piece of geometry which is translucent. There are no shadow maps implemented, her eyes have screen space ray traced shadows. There was also an eye ‘shell’ that sits over eye ball but remains in place as the eye moves. This provides shadowing and a small blurring as the eyeball connects with the upper and lower eyelids, without this the eyes seem mechanical (as can be seen below). The Shell had a depth offset to avoid clipping from the non uniform ‘eye bulge’ as the eye looked up or down.

Another piece of geometry was provided to be a blending between the tear duct and the eyeball. It blends both colour and the normals to connect the eye at the tear duct region of the eye.

In the end the results for real time eyes are incredible. Many people have commented that virtual avatars or agents are ‘dead in their eyes’ and yet in the live setting of GDC, the EPIC team produced remarkable results, (even if judged by non-realtime standards).

Facing the Future

One of the interesting aspects of a real time system is how it can inform the actor. With the low lag and latency in this pipeline, Melina Juergens was able to not only review her performance but use the system not unlike an actor rehearsing in front of a mirror. Without makeup she was able to rehearse and see herself in costume with full digital hair and makeup. “I’d like to go further – I’d like to build a cave – like the ILM cave (ILM-XLab) so she can go further and look around the room/cave and see the virtual fire or landscape around her,” explained Antoniades. “Such as system could use the motion capture markers on her head to adjust the real time projection of images around her, – corrected in perspective”.
VR
Since GDC, Ninja Theory have gotten the Senua Demo running in VR in an Oculus Rift head tracking system. “When she is looking at the camera – at you.. her eyes track slightly differently from her head, – and her eyes focus on where she thinks you are. “And if you go in really close to her face – her pupils dilate – it is really effective” says Antoniades. “I am all for keeping the original performance but I think there is real scope for adapting that performance with procedurals”. For example, Senua would walk beside you based on motion capture, but match your pace, and pause looking at you if you stopped to talk to her, for example”.
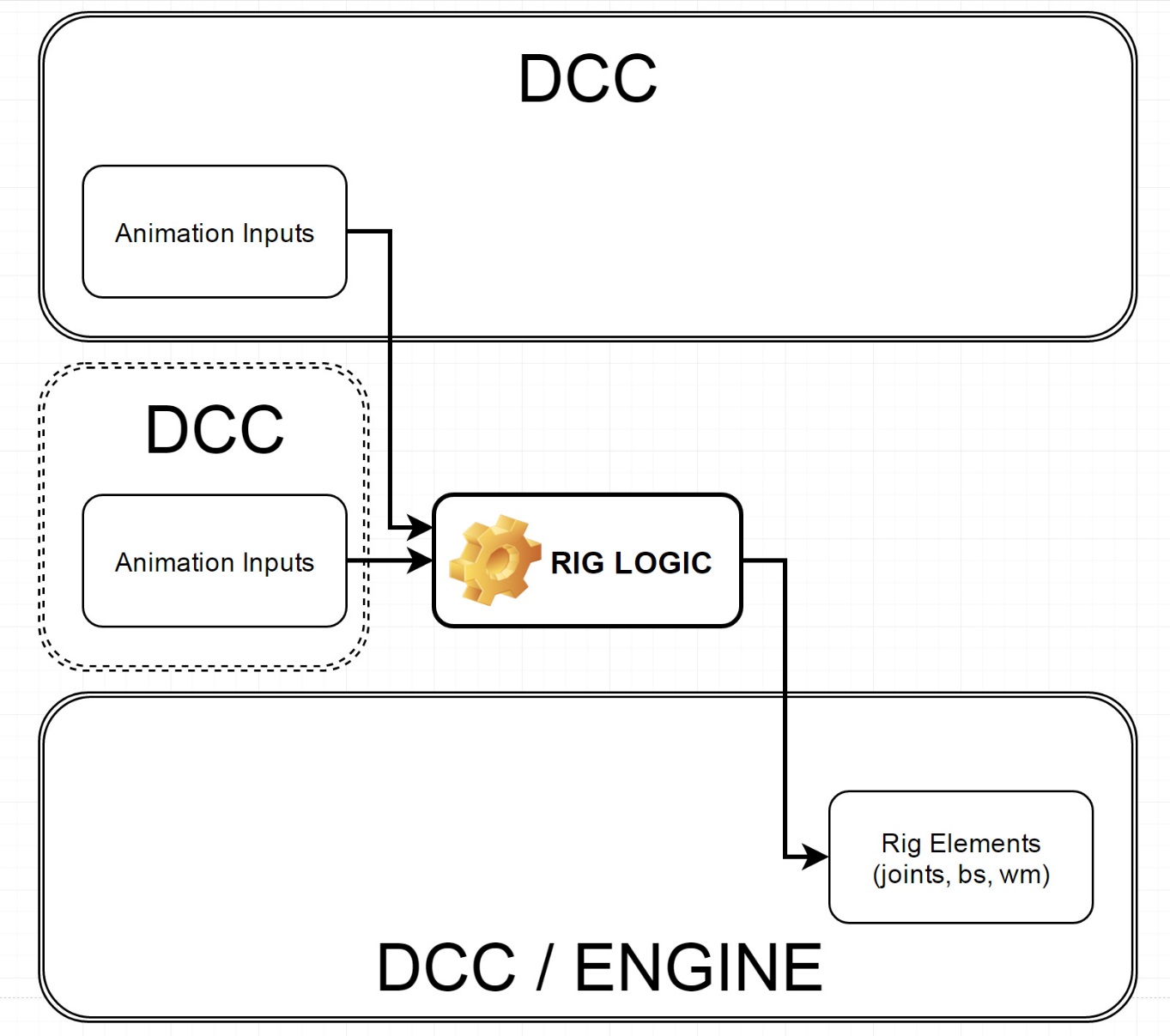
The Rig Logic tool
The Rig Logic tool has evolved at 3Lateral from something that sat inside Maya to something that stands apart and takes direct animation motion capture input and delivers them to the rig elements inside UE4.
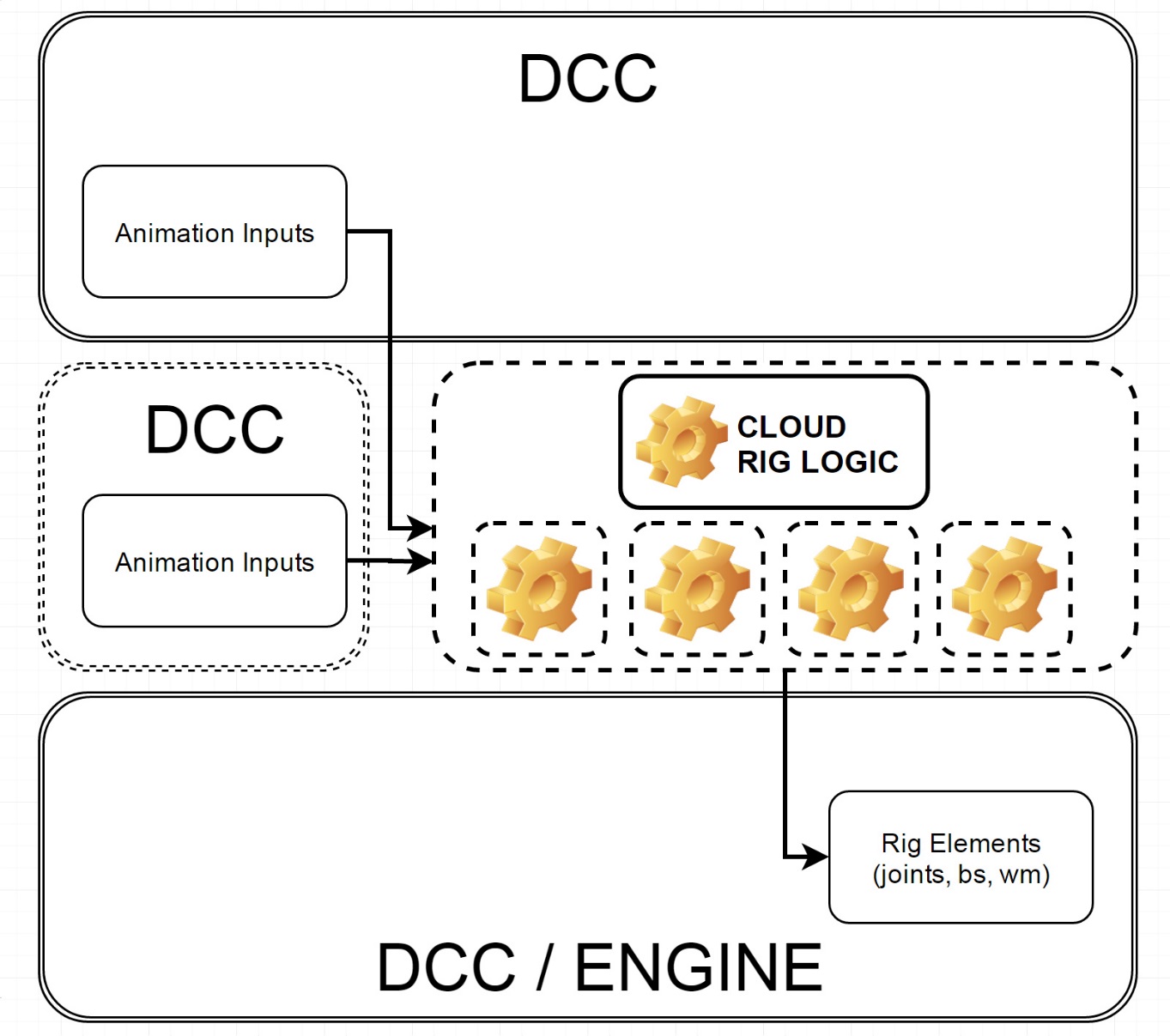
The next stage in this evolution is to have the Rig Logic run in the cloud and not locally. Such technology would allow mobile devices or VR headsets to just get a series of streamed commands, with the real computation done elsewhere. It would stream the data for the face in a very efficient (small) data stream, directly to the engine. “It is a bit of a new concept but I think it will be very powerful, especially in conjunction with some other things we are developing such as character population generation systems, which will turn the entire rig – the neutral expression, – all the facial expressions – everything .. (into a new highly efficient data format) that is very small compact and yet will define the entire character “says Mastilovic. “This could be able to generate tens of thousands of people on the street, for example. This is something we are preparing for in the very near future”.
Blendshapes vs. Joints.
Historically, but not exclusively, games designers have used Joint facial rigs and film teams have used Blendshapes. While 3Lateral were very glad to have the new Blendshapes approach in RE4 for this demo, Mastilovic still believes that the company has new technology and approaches that will make the face even better. “This version of UE4 now handles Blendshapes very easily and that’s fantastic, but still Joints are more efficient for the Engine, in 95% of cases. With the VT and AR requirements to achieve enormous frame rates, we have created some new technologies that will compile blendshapes into bones, – into an arbitrary number of joints. It will then pack this into the code for the Rig Logic – which means we get the fidelity of Blendshapes but with the efficiency of Joints”.
There are many factors in weighing up Blendshapes vs. Joints. Doing a Joint based system can be beneficial – Blendshapes can be spatially linear and movement around the lips with Blendshapes can look wrong due to these linear transitions. The mouth moves more via arcs than straight lines, which is arguably better handled by Joints. In the past it was thought to be tough to get the look of muscle sliding under the skin, and to get a nice skin weighting in an game engine with a finite number of joint influences per vertex. The suggested 3Lateral solution would address many of these issues.
Secondary Motion
While the live performance at GDC was driven by just the motion capture data streams, it is possible to add additional inputs as part of a live performance. This secondary motion added into the rigs would allow a tear to swell up on command, or an eye to exhibit ‘lazy eye’ or be injured in some way. This is exactly what happens in offline pipelines.
This also allows a version of flesh sims to be added. Flesh sims are incredibly computationally expensive but in much the same way flesh sims are added on top of motion capture solved performances in an offline film pipeline, 3Lateral can ‘plus’ a performance with additional input – even during a live performance.
“You could have a slider on an iphone that could affect the performance in real time” says Mastilovic. 3Lateral has a demo piece that they show (not with this data set) of an actress looking sad, “as that performance is happening I mix in a smile”. While these may seem competing emotions, the Rig Logic system resolves this to a performance which is even more powerful “it is even more intense… I guess due to the contrast of trying to ‘smile through the tears‘” he explains.
In essence, “we can decompose our rigs to lattice of joints, calculate skinning and preserve 99% of the deformations we get through Blendshapes. In areas where we would like to apply joint based secondary motion we can create a dynamic child joint and control the dampening through calculating skin tension for each facial expression” explains Mastilovic. For any facial expression Rig Logic can dynamically feed dampening values to the joints of any facial expression to give a more realistic effect.
“We appreciate there are more exotic approaches but this is an approach that gives very good results and is compatible with game engines today”.

The Body:
The simpler part of the process was Senua body which was fairly straight forward and relied on clean data from Xsens and the latest realtime in engine body Solver from IKinema. The Xsens rig had 17 sensors on it, with only one of those on her head. Most of the body rig was off the shelf software and hardware, that is now fully released.
The Xsens body rig worn by Ninja Theory’s Melina Juergens is typically used wirelessly, but at GDC the suit was hard wired due to the risk of ‘trade show interference’. This was not a restriction for the actress as most of her performance was from a near standing position and without much in the way of wild action.
From the Xsens sensors the data was streamed via IKinema into Epic’s Unreal Engine 4(UE4). Xsens’ entertainment product manager Hein Beute told fxguide that once you have the data it still needs to be retargeted to the CG rig, “which is why we love IKinema – because they do a very good job at re-targeting the data onto the final character”.
IKinema had previously developed the U4 plugin with Xsens streaming so in a sense both Xsens and IKinema were adding a body to the relative new technology of the face rig as part of the real-time render. This meant combining the data stream from Juergens’ Technoprops head rig and the second data stream that was coming from the Xsens sensors, which was all done in UE4.
IKinema CEO Alexandre Pechev explains that the company coincided the release of version 2 of their software for GDC 2016. “This new version allows setup and design directly in Unreal, previously to build a pipeline you needed Maya or Motionbuilder to set up the solving for the body, and then pass this as a rig to Unreal, but now we have a new version which ports all of this directly into Unreal”.
The pipeline is now streamlined: from one side there is the data capturing sensor hardware, and on the other is the game engine and the rendering. This direct mapping is new and allows for a simpler and faster pipeline.

While the body retargeting the data is done by IKinema, from the raw Xsens data. IKinema has an advanced option to drive the character disregarding any FK or body data coming from the hardware. The raw data then “drives the eigenvectors, but then we use our solver to use produce a more natural response on the spine and neck”. As the character’s neck and upper body was fairly unhidden by clothing, the team agreed that Senua neck motion would be critical. Given there was only sensor on the head, there was not a lot of data to base the characters spinal position on. What is remarkable then is how the Ikinema system still manages to interpret the data and solve for not only the spline but the should blades and skull base position.
So while Xsens 17 sensors can provide their own body solver, IKinema solves the body by just focusing on the raw skeletal data from the
- Hand position
- Feet position
- Hat (one head tracker only)
- Chest
- hip position
The rest of the solving work is done by the IKinema motion capture rig. The Xsens data is converted to a run time rig with the IKinema solver, which drives the full body rig. After the basic retargeting, there is another solver which has nodes to help with polishing the inertial capture data. “We have a number of nodes that are part of the solution that improves the data, for example we used a filter which removes all the noise and any instantaneous glitches that might come from the MoCap data” commented Pechev. In the pipeline, IKinema produce the full body of the character without the face. The face is added separately in the UE4 game engine.
Xsens were first contacted to be involved two months before GDC, and from Xsens point of view this was a fairly standard and well understood production process, as Xsens is designed for realtime motion capture, “the implementation of our system was pretty simple – after all we have done this type of stuff quite often”, Beute joked. As we have covered before at fxguide the Xsens rig takes only minutes to setup – and this exact rig is available for anyone to use today, without the need for customisation or modification.
The new aspect for the Xsens team was connecting to relatively new IKinema plugin and getting this whole system to work seamlessly and in sync, according to Xsens’ Hein Beute. IKinema worked on the project remotely before GDC. They initially received the test motion capture files from Ninja Theory, some weeks earlier and the IKinema team then set up a rig and fired it back to Ninja Theory almost immediately (the rig only takes 10 mins to build). Ninja theory reviewed the rig and provided feedback, for example about how the shoulders were looking. A review was done, and then the final file was sent back which is just a single UR4 file. “After that the body was just sort of working… from our point of view it was a straightforward job… you know any artist could get something like this set up in minutes in Unreal if they had the live data coming in”.
Conclusion.
While the GDC demo was extremely impressive, it came together in just 8 weeks without a major software breakthrough from any one player – but rather a series of incremental improvements and a dedication to quality – from all the players. This is significant as it means this quality of work shown here is within the grasp of many major productions. While current on set pipelines of real time feedback are rarely even close to this advanced, this collaboration surely points to the future and much wider real world adoption within the next short couple of years of this style of approach.
what are the name s of equitments. where can i buy them?
it is amazing mocap. good luck.
this is the way how avatar made.isn’t it?