The Max Planck Institute for Informatics (Max-Planck-Institut für Informatik) in Germany has been producing remarkable face research in the last few years. This year at Siggraph they will again present a major advance in their cg face research. This extraordinary R&D, built on the last few years of research papers, offers a major new approach to realistic digital face work.

The Max-Planck Institute(TMPI) is devoted to cutting-edge research with a focus on imaging algorithms and their applications. Their work ranges from foundations (algorithms and programming) to a variety of application areas such as “computer graphics, geometric computation, constraint solving, program verification, databases, information systems, and computational biology/bioinformatics”, according to the Institute web site. But it is their work in face replacement or reenactment that has been gaining international recognition with it’s seemingly incredible results from mono video.
The new 2016 paper “Reconstruction of Personalized 3D Face Rigs from Monocular Video” allows a normal video to be processed from a standard camera or library clip and produce a:
- performance capture of the subject,
- an automatic 3D face and personalised rig and
- facial reenactment.
This means the system can take a video input of Arnold Schwarzenegger and drive a digital face replacement on a clip of President Obama. One can also re-track back, onto the same actor, their own face de-aged or with a few years added. The system is not designed for realtime live puppeting but it is extensively automated. To find out more we connected with the team in Europe headed by Christian Theobalt. We spoke to Pablo Garrido and Michael Zollhöfer, two of the lead researchers. They, along with Dan Casas, Levi Valgaerts, Kiran Varanasi and Patrick Perez were authors on this year’s paper. All but two of the team are at TMPI (Varanasi and Perez are at Technicolor).
See the original source video of Arnold here.
As their paper outlines, the standard approach to this problem is to have an artist design a facial animation rig with custom-made control parameters that drives the expressions, the face shape, and possibly the soft tissue deformation. The de facto standard in parametrizing expression control, is normally to use FACS and to have a blendshape model that linearly combines a set of these Action Unit (AU) basis expressions. This has been the common approach used around the world. In any major studio, rigs often feature hundreds of controls, and it often takes many weeks of work to create such a rig for a specific actor. The model alone involves a complex sampling process before it is even rigged. Then face rig is often animated or driven from face motion capture data, a step itself that can require frequent manual intervention for data clean up.
Given the huge amount of time and the resources required, various attempts have been made to automate the process. These attempts can involve vast multi-camera lighting rigs, or special UV paint and sometimes specialist RGBD cameras. While this has lead to some of the process being able to be partially automated, there is still no approach that fully and automatically combines both the steps of reconstructing a detailed personalized face rig (including its modelling), and its animation, from a single mono RGB camera.
The TMPI approach does all of this. It takes as input video of an actor filmed under general conditions with a normal camera and then builds a rigged face model. “The purpose is to reconstruct a person specific face, with a rig, from just this mono video. We are aiming to get all the nuances and details such as wrinkles and very personally specific idiosyncrasies,” commented Garrido. The process has to go further than just modeling and rigging. When the team uses the rig, to say provide artificial digital make up back on to a source face, they have to also match the lighting for render to work. “We have to calculate and use the albedo, the lighting and the details have to be put back together again to re-render,” he adds.
At the end of the day the team hopes to provide a tool for animation artists to perform a variety of tasks, such as:
- reanimate a performance, adding perhaps an expression not in the original video, or correct a problem,
- providing a rig that has all the correct controls for emotional expressions the artist needs,
- providing a way of helping with digital makeup or de-aging,
- producing a rigged face with fine detail that is still in a form that an artist can polish further for high end work,
- democratizing face capture technology for everyday artists with a single inexpensive video camera.
Part 1
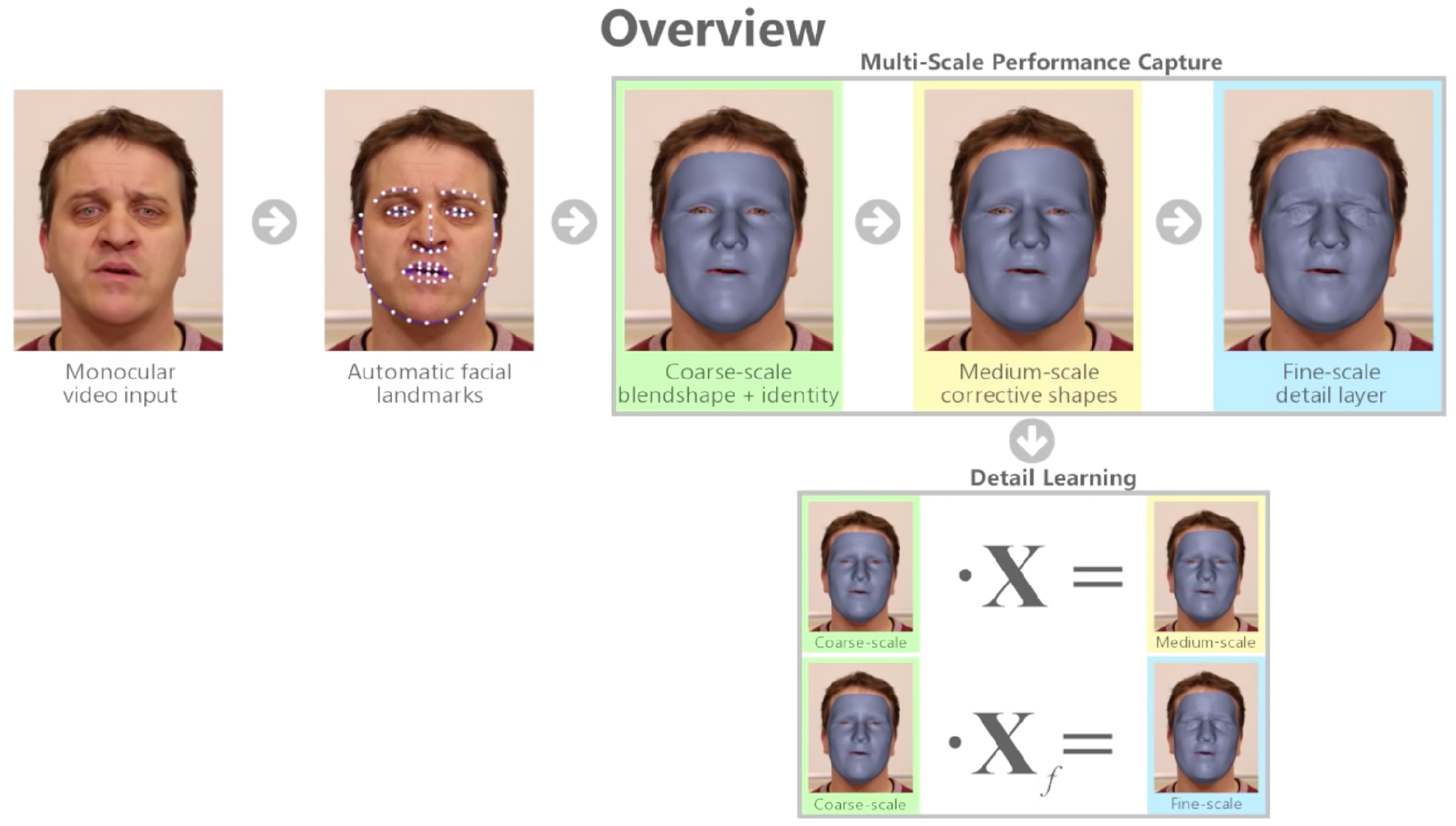
Starting with the input video (which is just RGB), the first stage is an automatic facial tracker. This tracks common facial landmarks such as eyes and eyebrows. This is an ‘off the shelf’ algorithm for standard feature tracking. Once this is done, it is improved using an optical flow approach that Garrido had previously published. At Siggraph Asia 2013, Garrido and a different team at TMPI published Reconstructing Detailed Dynamic Face Geometry from Monocular Video. Prior to this work, computer vision methods that captured face models from mono video, captured models that were extremely coarse and usually only contained sparse collections of 2D or 3D facial landmarks rather than a detailed 3D shape. The alternative was to use a stereo camera rig or entire arrays of cameras.
 The two outputs from the initial processing are the colour of the face and the tracking of the facial landmarks. The data from the tracking markers alone is sparse, but using the tracking with the colour provides critically more data. The team has a generic face with generic positions for the eyes, mouth and other landmarks. It also has a generic albedo for the face. The first step is a coarse scale blendshape & identity mapping. The program has a default blendshape model with some 75 blend shapes. This rigged face lacks fine detail and is, of course, nothing like our hero actor yet, but it is a rigged face that can move between the various 75 blendshapes.
The two outputs from the initial processing are the colour of the face and the tracking of the facial landmarks. The data from the tracking markers alone is sparse, but using the tracking with the colour provides critically more data. The team has a generic face with generic positions for the eyes, mouth and other landmarks. It also has a generic albedo for the face. The first step is a coarse scale blendshape & identity mapping. The program has a default blendshape model with some 75 blend shapes. This rigged face lacks fine detail and is, of course, nothing like our hero actor yet, but it is a rigged face that can move between the various 75 blendshapes.
By matching and effectively morphing our generic face to match the feature set of the hero actor’s tracked landmarks, one ends up with a ‘personalized’ blend shape set or model. The face still lacks fine details but it looks like our hero actor (roughly speaking). The optical flow is needed so all the feature tracking lines up – it effectively ‘connects the dots’ over time and removes jitter. (It is one thing to feature track say the eyes per frame, it is another to smoothly match up all those features over time in a series of frames of a video).
Once the system has a set of blendshapes for our actor the system can infer a set of blendshape weights to make the rig animate to match the actual performance. After all, someone acting is never just moving from one FACS AU pose to another. There needs to be a solve of the performance to a weight set of blendshapes animating over time.
While the model contains the albedo, it does not contain the lighting. To make the face able to be rendered it needs an estimate of the lighting. The next stage in the process is “some kind of inverse rendering,'” explains Garrido. Using some mathematical assumptions such as a lambertian assumption that the lighting is reflected equally in all directions, the lighting is parameterised using spherical harmonics. “In this synthesis approach, (or inverse rendering ) – what we are trying to do is combine the lighting and the albedo with the normals of the mesh to get the right lighting and hence colouring on the rendered image of the face” he explains.
This produces a good match for the rendering a face but the model is still without high frequency detail, as can be seen below.
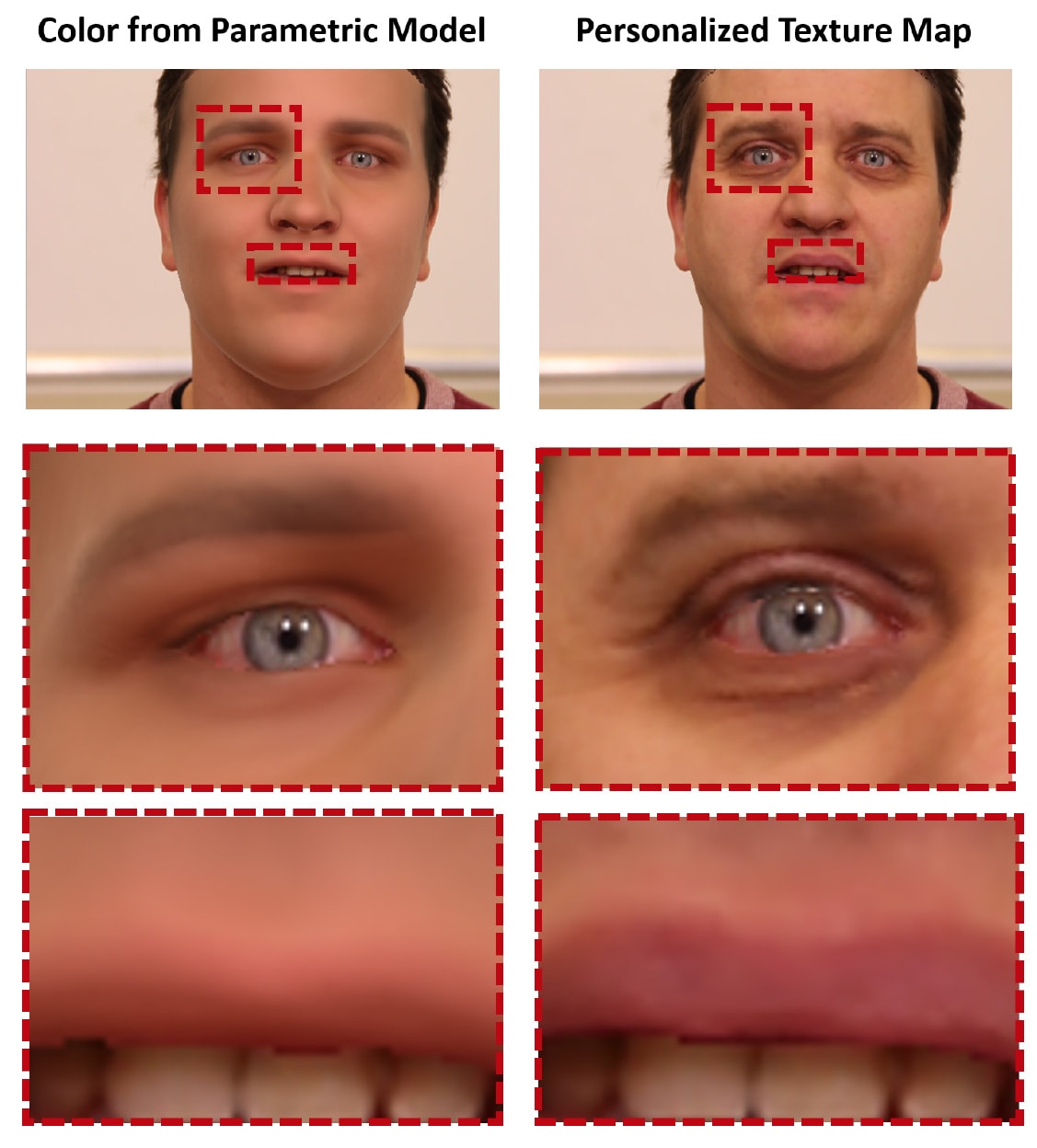
At the end of this stage the team has,
- a coarse geometry with the right identity (top left above)
- the albedo of the face
- a lighting estimation on the scene
- a face rig – connected to 75 FACS AU blendshapes
But the face, if used at this stage, would look very flat or plastic due to the lack of wrinkles and high frequency detail. (see the zoomed detail on the eyes and mouth above).

At the heart of the research is a new multi-layer parametric shape model that jointly makes a plausible facial identity with person-specific expression variation and dynamics, and fine-scale skin wrinkles. To get to the final result two more layers of work need to be added to the base coarse scale blendshapes.
PCA is the simplest(!) of the eigenvector-based multivariate analyses. Often its operation can be thought of as revealing the internal structure of the data in a way that best explains the variance in the data.
The whole process never needs the video footage to contain any deliberate FACS poses, nor does the process need the subject to do provide set of FACS poses from some other separate session. It is therefore possible that an actual person is more expressive or expressive in a way that is not well covered by the 75 FACS generic poses. For this reason the next stage is a medium scale corrective shape stage. This builds on the coarse scale blendshapes. The maths here is complex but it is a Principal Component Analysis (PCA), statistical procedure using Manifold Harmonics. The eigenvectors are efficiently computed using a band-by-band shift invert spectral transform. “The eigenvectors are obtained after we have obtained the identity of the person, we get them from a neutral expression of the identity that we have estimated, and we compute them directly from that estimate” (so even if the subject doesn’t have a neutral pose – one is estimated).
In lay terms, it works out ways of robustly estimating from the RGB video a set of deformations (as a deformation field) on the vertex level of the face to make it handle a wider range of expressions. It does this with statistics – things like averages (means) and best fits of the data based on variance. The key is it learns or estimates from the video and converts that into more accurate expressions. This process also uses the ‘inverse rendering approach’ and the estimated lighting from above. In a sense, once you have a good likeness of the person, and you know the lighting fairly well – plus their head position and expression – then the shading on the video face informs the algorithm that there must be wrinkles on say the forehead..or how else can one explain the differences between predicted shading and the actual shading seen in the video on the subject’s forehead?
Starting with the work in 2013, what has been an important part of this body of research has been adding the fine, higher frequency detail to the face. Thus the third level is a fine scale detail level to add the wrinkles. The system starts with a generic blendshape model modified to the hero actor + the medium scale corrective shapes and then adds fine detail. To move from this Coarse scale blend shape to a rig and model with both medium corrective shapes and fine-detail requires a third stage.
The 2013 TMPI Siggraph Asia paper added the optical flow component and allowed capture to work under a range of lighting conditions. But it stopped after producing the first rigged model (with high frequency detail). It did allow for example, tracked textures such as face tattoos to be added to the source video. The 2013 directly informed the new 2016 paper but “SigAsia 2013 work we used 78 blendshapes, now in the current work we employ 75 blendshapes.” commented Garrido. This new paper goes much further than any of the previous research from the team. While the medium stage above added new expressions and then deformed the vertexes, that approach couldn’t represent fine surface detail like wrinkles. To solve this, the program once again learns from the video an additional per vertex displacement. These are encoded into the gradient domain in terms of scaling, skewing and thus there are actually 9 parameters per triangle that gives the vector displacement or high frequency wrinkles.
[clickToTweet tweet=”fxguide.com The TMPI team: single clip from youtube to a 3D custom face rig, automatically. #nevertrustyoutubeagain” quote=”The technology really is: a single clip from YouTube to a professional face rig, automatically.”]
The output is the personalized face model with blendshape expression controls, as well as a detailed face albedo map and an incident lighting estimate. New face expressions of the rig (with proper fine-scale detail) can be created by simply modifying the blendshapes, which fit nicely into an animator’s standard workflow. This method captures detailed, personalized face rigs from arbitrary mono video of actors, vintage footage, or Youtube clips which would be impossible to automatically create and animate from, by any other means.
It is important to note that the second and third stages described here of adding detail are not themselves yet parameterised. The sliders are only functioning on the coarse model, the other aspects are just laid on top – so to speak. The coarse scale has 75 controls but we need to connect the 75 parameters to those other layers. This last stage connects all three together. This coupling of the coarse to the fine scale layer to make one unified rig that an animator can use is perhaps one of the most significant contributions of this year’s Siggraph Paper from the team.
“For the course layer you can think of these parameters as having semantic meaning, so for example if you move a slider the mouth opens, if you modify another the eyebrows move… and this is how an artist can work with the sliders and modify the face as they want,” explains Zollhöfer. By contrast, without additional work the other two layers have no semantic controls. “For the medium scale layer – they are just an abstract representation – these laplacian basis (difference/divergence of the gradient), and for the fine layer it is just per-vertex displacement..in short we don’t yet know (at this stage in the process) ‘how’ to produce a wrinkle,” he adds. This is where the new key detail learning component comes into play.
What the detail learning does is learn the relationship between the wrinkles and the expressions. “So it knows for example if you pull up the eyebrows you get wrinkles at certain spots around the eyes. It learns the relationships” Zollhöfer explains. This is why in the end an artist only has to use the 75 sliders and it controls all of the expressions and micro detail relevant to that expression – “you get the wrinkles for free” he jokes.

Part 2
At the end of Part 1 above, the output is a complete solution, and one could stop there and just adjust sliders and see the face react, but the next step couples this rig with a new source performance.
The next major step is to effectively repeat what was just done, but on the new ‘driving’ face. This is the new face that will drive our model. The new face is tracked, it is mapped to the 75 FACS expressions and solved to a weighted set of blendshapes animating over time. This second face having been fully solved, now drives the original Stage 1 rig and thus the original face can now speak or match the second ‘driving’ face.
All that is left to do is to composite the face back on top of the first subject and that person now is effectively puppeted by a different person. Of course, in this application there is still the issue of their voice. If an actor was driving a mask composited onto President Obama’s head and body, there would be a sound issue. One would still need to have the actor sound like the president, but his digital president’s lips and expressions would all match the actor seamlessly.

As the lighting has already been estimated, when the new performance is rendered it is done with the correct lighting.
Applications
There have been applications shown by the team of using this technology for face replacement, such as one might want to do with a stunt performer. In the reenactment example, the face is lit by the person who provided the source face, but with face replacement, the lighting of the digital face inherits the other person’s lighting ie. the stunt performers lighting solution. It is different, but in both cases the same lighting estimation algorithms can be used.
Sound is not an issue if one uses this technology to de-age the President, to continue to use this example. Here the face process works as before but the 3D rigged face is modified to look younger or older in any creatively valid way. De aging when done with compositing is extremely complex, this opens up a whole new approach to this problem, but the team is quick to point out that for major feature film work, more rendering subtly would most likely be desired. For example, there is no explicit SSS aspect to the shading model. Sound may also not be a problem if one was to edit a video of say the President. This technology could be used to bridge the gap if words or sentences were cut and removed. One could use the technology to believable connect the edited sequences or just change their expression while the President spoke, perhaps mocking their own remarks somehow.
Earlier research by the group looked at just changing the mouth of an actor to help with lip sync on dubbing foreign dialogue. This was subjectively less successful as just a mouth replacement often appeared slightly wrong, as the expression of the face comes both from the mouth and the eyes. Also the seam line seemed more noticeable on a partial solution.
This type of convincing facial reenactment clearly has ethical implications. The quality of the digital reenactment solution that the team has demonstrated makes a mockery of saying “but I saw them say it with my own eyes”.
Leaving aside the ethical or moral aspects, the approach the team has taken in making an artist friendly tool, combined with the large time saving from a virtually completely automated solution – makes this one of the most interesting papers to see at this year’s SIGGRAPH. It will be extremely interesting to see if a major studio tries to use this approach in a high end feature film, certainly the algorithms are designed to be scaled up and be used by artists in a production environment. It is safe to say it is as if this tech was made for a Forest Gump 2 type of film using archival footage modified for a modern story.
The TMPI team is presenting their work in the Capturing Humans session. Wednesday, 27 July, 3:45 pm – 5:55 pm, Anaheim Convention Center, Ballroom D. Session Chair: Richard Szeliski.