The Alita: Battle Angel project was adapted from Yukito Kishiro’s manga series Gunnm and was directed by Robert Rodriguez. James Cameron had been slated to make the film himself, but after many years of the project not commencing principle production, Cameron handed the Alita reins, along with 600 pages of notes and access to team of artists and technicians, to Rodriguez, according to the LA Times. Rodriguez shot the film in 57 days combining performance capture with live-action filming on set.

Alita was never intended to look completely human, as she is a deactivated female cyborg who is revived, but beyond the film, Alita is a brilliant test bed for the next four Avatar films Weta Digital is now working on for Director James Cameron.
Alita: Battle Angel is actually one of the first times Weta Digital has done a human-like CG character. Weta has vast experience with digital characters such as Apes and Gollum but, with the major exception of the face replacement work on Furious 7, most of their work has not been targeted at a person, or in this case, someone close to human form. Eric Saindon was the visual effects supervisor on Alita, and with his long history with the company, from 2001’s LOTR: Fellowship of the Ring to Avatar and The Hobbit, he is no stranger to digital characters.
https://www.youtube.com/watch?v=kwWH3x9EBJg
Alita is important on its own as a major film, but also as a sand box for James Cameron, who was both a Writer and Producer on Alita. He has commented in the press that the film has been a test bed for the technology that will be used in the upcoming Avatar films. Saindon comments that, “Jim’s said that in interviews that Alita is the perfect environment for us (Weta) to start working on technology for Avatar. Everyone knows we’re working on Avatar now and everyone knows that’s where our technology’s going.” Currently Avatar 2, Avatar 3 and parts of Avatar 4 have completed ‘principal capture’, with live-action filming set to take place in New Zealand for about four months, starting in May. Unlike Alita, Cameron has said that the live action is a relatively small part of the new Avatar films, telling the NZ Herald last month, “there are several live action characters that go through a lot of the CG scenes so it’s about integrating the live characters into the CG scenes. Kind of the opposite to Alita where we had a few CG characters mostly integrated into live action settings.” He also added that in the new Avatar films, “I’ve got a couple of human characters integrated into the Na’vi rainforest, oceans, mountains, that sort of thing. We’ll shoot that 3D, so everything is going to look spectacular. That sets the bar for the CG guys at Weta.”
All of which makes this the perfect time to examine the face pipeline of Weta Digital.

The Face Pipeline at Weta Digital
Alita is the first time Weta has had to do a fully CG humanoid. The character has bigger eyes and a slightly smaller mouth, to reflect her origins from the manga world. Saindon explains, “for our pipeline, we really did something slightly different on this film – actually we did a lot of things different!”

One of the many new approaches that the team went about doing performance capture included moving to using two cameras on actress Rosa Salazar’s helmet cam unit (HMC) in addition to her full body and hand capture suit. The two camera solution provided depth information, although the cameras were standard HD cameras. The team also decided to use dots on the actress’s face. “We use the dots to work with our deep learning tools on her face,” commented Saindon. Weta now has several key deep learning tools as part of their facial pipeline (see below)
Next the team built a digital Rosa Salazar double before re-targeting to the Alita character. “Before we did anything with Alita, we actually took the motion from Rosa and put it on a Rosa digital double that looks just like Rosa,” explains Saindon. This digital copy of the actress is fully textured and renderable. The team do this so they can study the motion data on the Rosa digital double and compare the motions to the live action directly. This allows them to see if their capture data and their interpretation of that data is accurate into how all the muscles are moving on the real actress’s face. “We compare the interpolation of that data to Rosa, as a one-to-one comparison,” says Saindon. “The different ways the muscles are pulling to move her mouth for example or her nose and how they all work on top of one another. We make sure all of that information comes across correctly to the digital world.”

Once the team is happy, they retarget this data to the Alita model. “We now go through extra steps that we’ve never done before, to ensure that things are working well,” he adds. This extra stage lets the team find out where any problem is being caused. Without this intermediate step it is hard to know if the interpretation of data is wrong, or if the motion just looks wrong on a different character. Only by verifying the motion can they proceed with confidence.
The Weta pipeline is still a FACS pipeline building on the years of experience the team has developed since Weta helped pioneer the adoption of FACS into the VFX industry. Saindon explains that the new tools at Weta often build on the old. “We still do a whole FACS capture session with Rosa. We get her to sit down and she goes through, oh God, it’s a ridiculous amount of FACS poses. It’s a whole system we use to cover a range of emotions and facial poses – and all that data we use as training data for the deep learning.”

A FACS rig is built on key FACS expressions but as Animation Supervisor Mike Cozens explains, those poses are extreme poses. “If we think of a FACS expression as a range from zero to one, where zero is the muscle not fired and one were it is at its extreme, then the puppet can do that full range of motion,” he explained. For Alita, Weta needed to refine it’s FACS as they had the extreme facial shapes, and their corresponding extreme muscle responses. They understood how muscles were behaving in any extreme. They also knew how the muscles ramped into those FACS poses, “but we hadn’t done all the work we needed to do to understand all the detail work that happens in a very low range around phonemes and dialogue”. Weta wanted to increase their sensitivity, to facial movements to really capture subtle aspects of Rosa’s performance. The actual performance behaviour is happening in just a very small part of any major ‘zero to one’ FACS range, “if a 100% is a full FACS combinatorial extreme range, then we found that we are talking about a percentage change of 0.1% to 0.5% or 0.3%”.
In addition, the team wanted to focus on the correct combinatorial ways multi FACS interacted together. The team put in a lot of work to refining the rig and modelling, in addition to new research into Alita’s face to allow these very subtle controls. This included the team consulting plastic surgeons, “in order to break down how all the little connective tissue and muscles layered into the face that, quite frankly, we weren’t even aware of being there until a couple of years ago,” adds Cozens. These aspects, while small in the overall effect, play a large role in adjusting the subtle range of muscle movements the team were aiming at and providing the sensitivity the team wanted to be able to provide to Alita.
Cozens pointed out that the animators did not consider Rosa to have just one constant base neutral pose to work from, but rather each day the team calibrated a new base neural expression. This is because an actor’s facial micro expressions can be affected by how much sleep they had, how much hydrated they are, the day’s weather, humidity and a range of daily changing issues, making it “a constantly moving target and you even get into what the actor’s stress level is, what they are feelings on any given day, what’s going on inside their head.”

Weta Digital did not use a Light Stage or Medusa rig for Alita, instead the team has their own camera capture system. Weta do not do a polar based separate Specular and Diffuse capture approach. “The reality is we could do it for more of an ICT style set up (i.e. the Light Stage X approach),” Saindon adds. “But it’s more of a photogrammetry solution as we are focused on being able to define and recreate those shapes once we get it back into the digital replication stage.” The Weta rig is a robust in house 60 camera system that cover 180 degrees around the actor or actress. The system does capture 4D data, so for key lines and sequences the team would get Rose to re-deliver her lines sitting in the Weta capture rig, but importantly, this is designed to be used as both reference and additional data to the deep learning process.
The team did get Rosa to deliver a set of dialogue that covers the full range of mouth expressions when talking. “We got her to do a ‘Harvard line set’ that covers a wide range of phonetical arrangements in dialogue,” comments Cozens. This is used to refine her digital lip sync even further.
As producer Jon Landau has said, the team want to avoid FDR. “Because the second you start to do facial performance away from the body, they start to separate,” points out Saindon. While Weta could mix a later facial capture with an earlier body capture on set, the team strongly believes this can undermine the integrity of a performance. “Your face is driving your performance, while your head is doing something at the same time, along with your neck, which in turn moves your shoulders and all those things. Once you break any one of them away from what is actually happening on set, you start to get just a completely different performance.” Weta therefore tries to keep the performance as one emotional performance capture whenever possible. However, there is one major exception – action sequences.

There are two reasons why the facial data captured from just the head cams of the HMC, may not be ideal. The first is if the HMC itself is causing issues in action sequences, and the second is if the action in the script far exceeds what Rosa could do. Even though the team has gone to great lengths to now better balance the electrons of the HMC to avoid neck strain from an unbalanced HMC, the very presence of the helmet can affect the upper face range of motion that an actor has, just from the presence of the helmet itself. The second reflects that the face may need to respond to extreme jumps and hits in a way the actress neither experiences or could safely do. In these cases a secondary capture off the set may allow the animators to more faithfully deliver a believable performance. This was true of the MotorBall sequence, where clearly the actress is not leaping from building to building on turbo powered roller skates. In these cases, flesh simulation and hand animation come much more strongly into play to get the right facial dynamics. “We can add that simulation on top of Rosa’s performance,” says Saindon. As Weta is solving her face with a muscle system, that includes the fascia through to the muscles, “we can actually do a simulation on those elements below the surface of her skin, which actually helped pull around her face slightly and just get that extra bit of motion when you’re moving at high speed or hitting the ground, as your face gets smacked by someone throwing a motor ball for example,” he adds.

For this approach to work, the ribbon muscles unique to the actress Rosa needs to be estimated. Each face is different, but without an autopsy, this is really done based on the modelling artists’ years of experience. Weta starts with a generic skull. This is then fitted and adjust to the profile of the real actor or actress. In the past Weta has had some x-ray data to help with this, but generally the skull fitting is an artistic interpretation. Based then on the FACS data, they try and “recreate the muscle system as best we can for each character. We do try and recreate the muscles based on how much fat is in their face, their muscle tone, and things like that, but it does have to be slightly generic because most actors don’t let us cut open their face and see how their muscles were created!” Saindon jokes.
Beyond the skull, the team use dental impressions to build accurate teeth and make an accurate estimate of the tongue. At Weta, one of the first things animated for a detailed character is their tongue, as it affects both animation and lighting. “Your tongue actually bounces more light than you’d expect into your mouth. And if your tongue is not in the right place, you end up getting a very dark inner mouth,” Saindon explains. While the FACS expressions help, there is a strong element of experience combined with artistry to get the tongue animated correctly for the character’s dialogue.
The Eyes Have It
Perhaps the most important part of the face is the eyes, and this was particularly the case with Alita. Interestingly, Alita’s eyes changed between the trailer and the final film. What makes this intriguing is not that the eyes changed, but what those changes were and how it affected a viewer’s perception of Alita’s face. Saindon recalls being on a conference call after the trailer had been released and the internet exploded with discussion around the validity of Alita’s eyes. “In the next call we had with Robert (Rodriguez) and Jim (Cameron), no one wanted to say anything. Finally I just said, ‘hey, so are we doing anything about the eyes?’ There was a lot of discussion. We asked if they (Rodriguez & Cameron) wanted us to try something? And, Jim pretty much just said, (and excuse the swearing)… but Jim said, ‘fuck the haters’. And he said, ‘we’re going to go bigger with the eyes – that’s what’s going to fix it.’” Cameron was right. What he wanted was not to make the eyes themselves bigger, but to enlarge both the pupils and the iris. It is a very subtle adjustment. Saindon estimates that, “it’s probably another 10% on top of what it was from the first trailer,” but when the the irises are actually bigger, and then the pupils inside of the irises are at a default size relative to each other, then they actually filled the scalera a little bit more and so the eyes exhibited less white scalera. “So you saw less white around the eyes and he was right because it was actually the whites around the eyes that was making the eyes feel not quite right,” adds Saindon. It was hard for even the Weta professionals to define what was the issue and he adds what complicated the process further was that, “when you saw still frames, then the bigger eyes didn’t really make a difference. But once you actually started seeing in motion and started seeing less of the whites around her eyes, it just made a big difference.”
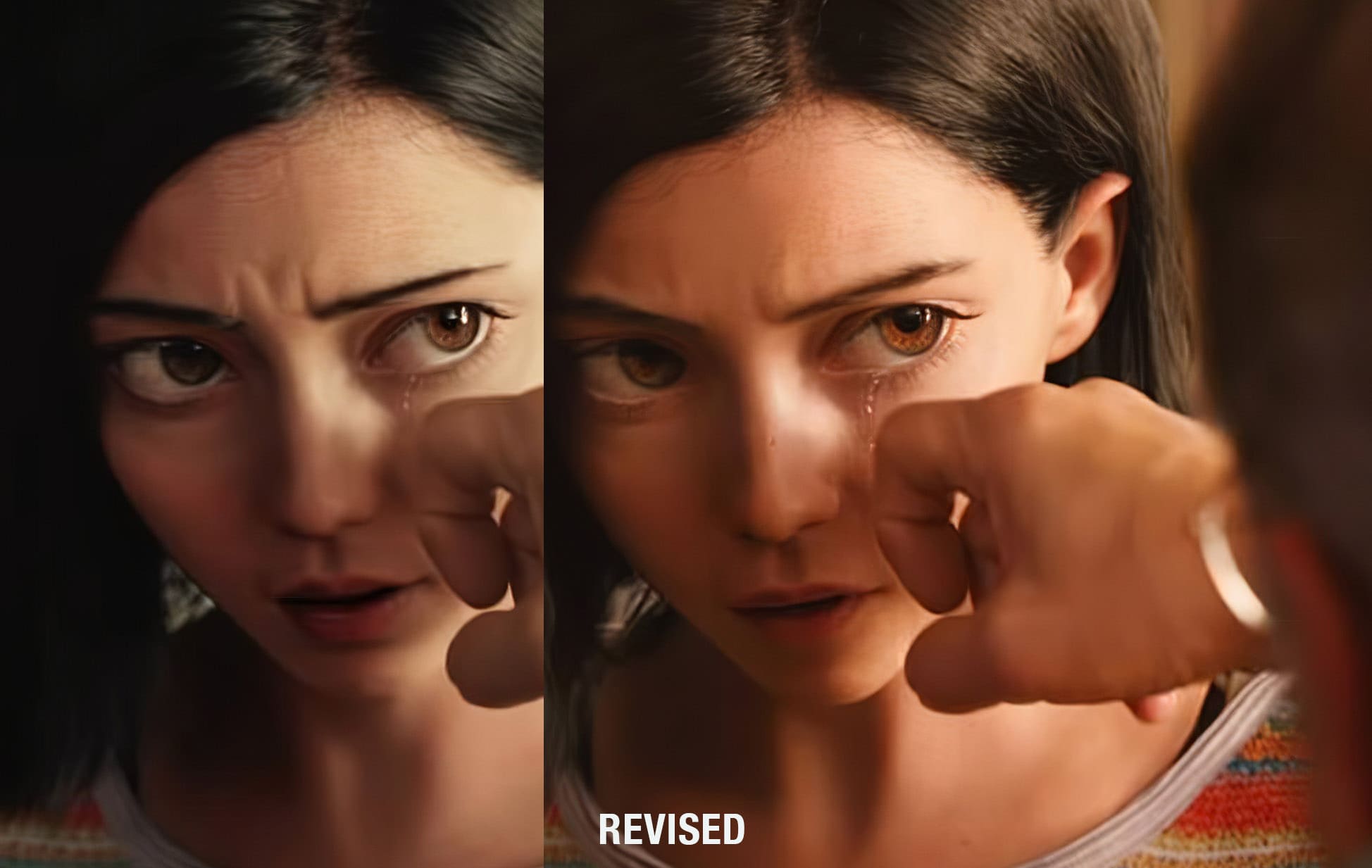
The face of Alita is different from a normal human not only only in eye size. Weta explored moving the eyes around on the face, changing interocular distances and their placement. “It was all about getting the proportions of the face right. As soon as something is a little bit off you notice it’s not right, but you can’t quite figure out what it is,” says Saindon. Additionally, her mouth was made a slightly different shape, as was her her chin. Weta also positioned Alita’s eyes the same proportionate distance to the edge of her head as a normal person, this resulted in Alita being more triangular in head shape than Rosa. Alita was designed to maintain various key characteristics of Rosa. “If we hadn’t, then Rosa’s performance would never look quite right. We ended up taking Rosa’s eye scan and putting Rose’s eyes into Alita scaled up, so that we could always match 1:1 with Rosa’s eyes.” Alita also shares her mouth with Rosa, right down to lip textures and even imperfections on her lips. Saindon explains that, “she even has a little scar that is on her lip, that no one will ever see. But it’s because we did all of this, her performance comes across much better. And you, you just completely believe her performance is by Rosa.”
 The eye model for Alia was much more detailed than Weta had ever done before. Normally characters have a single plane for the iris, with displacement, under the cornea and lens, but for Alita, the eye was actually modelled with a fibrous iris. By comparison, Gollum had 50,000 polygons for his eyes and Alita has eight and a half million polygons for one iris. “We actually want you to be able to see their rounding below the fibres in the iris itself.” The team did a Houdini simulation, of the fibrovascular pupillary strands in the iris, (or the strands that connect to the pupil and to the outside of the iris). As these stands pull and open or close the pupil, the stands break and move over time, which gives an iris depth and a unique look to every person’s iris. “We ended up with very high resolution geometry for the artists that we could do refraction and simulation of…with very high levels of detail,” he comments.
The eye model for Alia was much more detailed than Weta had ever done before. Normally characters have a single plane for the iris, with displacement, under the cornea and lens, but for Alita, the eye was actually modelled with a fibrous iris. By comparison, Gollum had 50,000 polygons for his eyes and Alita has eight and a half million polygons for one iris. “We actually want you to be able to see their rounding below the fibres in the iris itself.” The team did a Houdini simulation, of the fibrovascular pupillary strands in the iris, (or the strands that connect to the pupil and to the outside of the iris). As these stands pull and open or close the pupil, the stands break and move over time, which gives an iris depth and a unique look to every person’s iris. “We ended up with very high resolution geometry for the artists that we could do refraction and simulation of…with very high levels of detail,” he comments.
Interestingly the iris’s are not Rosa’s iris, as the director wanted Alita to have slightly different eyes, not just in colour, but he wanted Alita’s eyes to be younger. In the film Alita is first presented as a teenager, Rosa is a woman in her mid early thirties. To get the right eyes, the team started with Rosa’s eyes but then cycled through 50 or 60 people at Weta doing high resolution closeup photography of their eye balls with a flash ring on an SLR. “We then put these in front of Robert and said, ‘hey, which of these work for you?’ ” recalls Saindon. Adding that, “it’s crazy how different everyone’s eyes look when you look at an 8k image of someone’s eyeball.”
New Deep Learning Tools.
Face Muscle Hallucination
Deep Learning may seem like a buzz word – the new ‘VR’ or ‘Stereo TV set’ – but the reality of its multiple deployments at Weta are much more significant. Deep learning is in multiple tools at Weta, and it is not hailed as one solution or a silver bullet. For example, above it was mentioned that the face tracker uses deep learning. “We can plug in the information (as training data) for the movement of her face. The dots then help us with the deep learning to allow the computer to learn what muscles are being fired as those different dots move in different locations,” explains Saindon. The deep learning is not being used here as a tracking tool, but rather to get to a plausible expression space. The system can extrapolate or ‘hallucinate’ a viable set of markers, even when part of the face is occluded or when perhaps the camera boom arm has to be removed from the HMC, when another actor is touching her face. The deep learning feeds the expression space with a plausible solution when Rose was lying down on the bed and part of her face is in her pillow. “It is not there to produce her expressions for her. It’s really to achieve her expressions. It’s actually just breaking down what each part of the faces is doing, so the right muscles are activated and fired to drive the facial model itself,” explains Saindon. “So, we use the deep learning to actually interpret all the movement of her face and find out what muscles are actually being fired so we can recreate that digitally.”

Real World Applications of Deep Learning to Skin
Weta used a new skin tool for Alita’s skin generation which again uses deep learning. Weta has been developing a new deep learning methodology for painting and hallucinating the areas of skin, to plausibly produce skin and pores of the correct size and orientation. “We actually use deep learning to paint the pores on a face. So rather than having to clone detail from one area to another, we’re actually painting in detail using a new deep learning technique to place pours on the face properly and in a way that allow the skin pores to flow properly on your face.” While it is possible to algorithmically paint pores on with a procedural model based on surface normals etc, the deep learning produces pores that it believes are accurate based on what it has learnt from training data. This elevates the approach over a traditional but clever procedural approach.
This was the first time that Weta has used this particular approach, although they have used similar approaches with things such as their forest growth tools, and further back, a simpler version of today’s A.I. programming was used in the Massive for crowd agent simulation. Today, Weta uses machine learning in a host of areas, including in effects simulations and advanced vegetation tools.

Alita (Avatar) Under Water Flesh Sims
One of the very first things the effects community learned about the Avatar sequels, before it was even confirmed that Weta would do a series of sequels, was that Cameron would be going underwater on Pandora. James Cameron is a master of underwater photography and exploration from his work on The Abyss (1989) to his real world journey to the the deepest part of the Mariana Trench, at the bottom of the ocean.
While it is understood new technology has been developed for the Avatar sequels, in Alita there was a taste of the brilliant work Weta has been developing. At one point, Alita jumps in a lake and walks underwater, emerging inside a crashed ship. The shot of her breaking the water and exiting into the ship was remarkable, but in many ways the fully underwater shots were a window into an entire new way of doing underwater animation. Senior Visual Effects Supervisor on the film and the head of Weta Digital, Joe Letteri, has a long well earned reputation for pushing to create technology that accurately models the real world and solves problems based on physics and not cheats. Alita‘s underwater walk represents several problems and innovative solutions.

If someone is motion capture on land acted out the process of walking underwater, the process will always suffer as a person under water has buoyancy. This effectively moderates the effects of gravity so that, even on a wire rig, the way a person’s limbs are supported and float could not be replicated on dry land. The next issue is resistance. If you wish to walk forward, the water’s resistance naturally changes how the body leans into the walk. Finally, everything is connected by the forces of the fluid dynamics, in very different ways than the air does on dry land. Combining these, if one thinks conceptually about a person’s face underwater, the skin has less downward forces from the buoyancy, and if you move your hand near your face, the fluid pressure would impact your face, and the water itself would push back much like strong wind resistance.
Weta’s solution is to do a combined simulation that seeks to combine fluid sims, flesh sims, hair sims, and cloth sims, and produce one complete solution to the person and their volume in one complex but holistic approach. It is a remarkable attempt at a unified solution. “That’s the ultimate goal,” explains Saindon. “To have all of the elements interacting together, not have to solve one element at a time, but to be able to solve them all as one thing.” This is a huge challenge as not only are all the simulations solved at the same time but they all have to be interacting together. “It’s not the typical process of solve the skin than solve the cloth on top of it, then hair, then the water. The problem with that is that then maybe we have to go back and move or adjust something. This new approach is taking her motion, dropping it onto her (digital) skeleton, and then hitting go and letting everything be solved at once.”

Images © 2018 Twentieth Century Fox Film Corporation. All rights reserved.