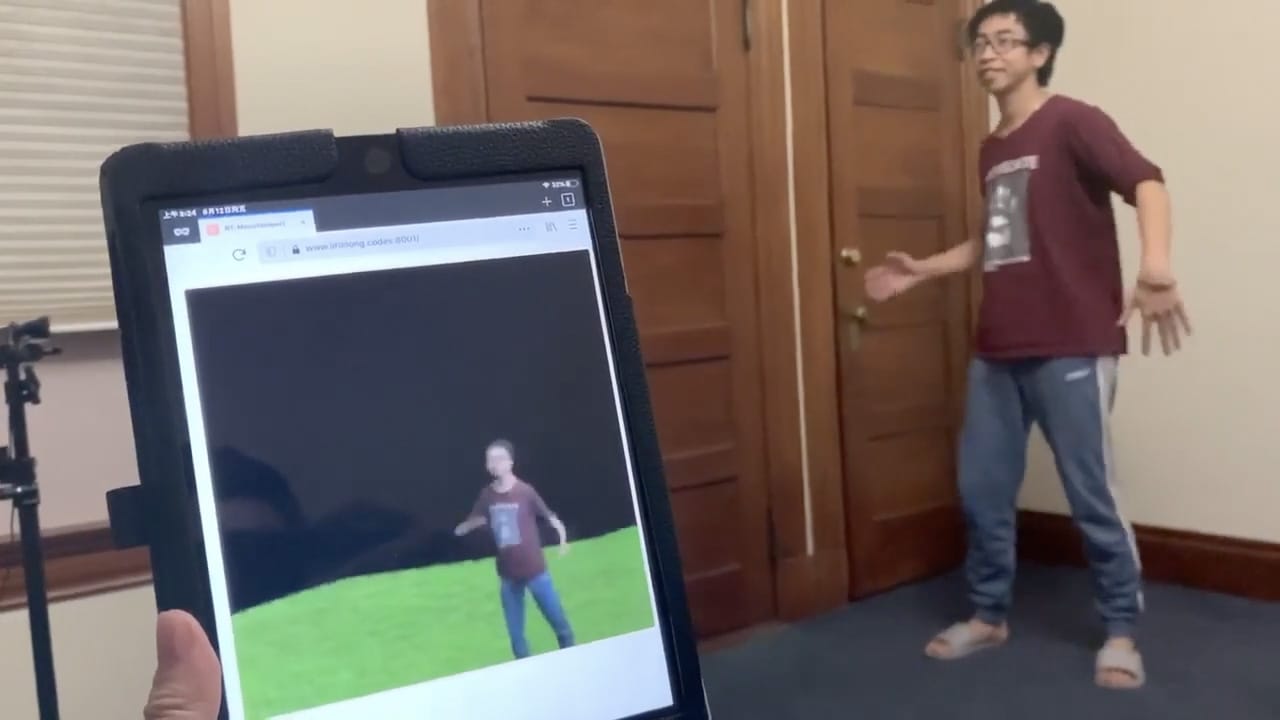
 This week at SIGGRAPH’s Real Time Live (RTL), Volumetric Human Teleportation or ‘monoport’ won ‘Best in Show’ Jury Award. (Two-way tie with Interactive Style Transfer to Live Video Streams). The Monoport team consisted of USC members Ruilong Li, Zeng Huang, Kyle Olszewski, Yuliang Xiu, and Shunsuke Saito and former USC Prof. Hao Li, now full time at Pinscreen, a company he formed to develop digital characters. Pinscreen not only was part of this winning presentation, but they had an entire second entry in RTL focused on real-time digital humans.
This week at SIGGRAPH’s Real Time Live (RTL), Volumetric Human Teleportation or ‘monoport’ won ‘Best in Show’ Jury Award. (Two-way tie with Interactive Style Transfer to Live Video Streams). The Monoport team consisted of USC members Ruilong Li, Zeng Huang, Kyle Olszewski, Yuliang Xiu, and Shunsuke Saito and former USC Prof. Hao Li, now full time at Pinscreen, a company he formed to develop digital characters. Pinscreen not only was part of this winning presentation, but they had an entire second entry in RTL focused on real-time digital humans.
Volumetric Human Teleportation SIGGRAPH 2020 RTL
The winning presentation allows the real-time volume capture and display of people. The system isolates the person, samples their texture and using machine learning (ML), produces a 3D person. This digital version can be viewed from any angle, even from the back which was never seen by the program. It does this by using deep learning and builds on the team’s earier work entitled PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization, (see below), which was first shown at ICCV 2019 but is now running in real-time.
The program does not key the target person from the background, nor does it use traditional voxel representations or require multiple cameras, as it does not use photogrammetry. It uses ML to segment the individual, even in loose and detailed clothing, and then infer a result. As the name indicates, it does a pixel-aligned Implicit function to align the 2D image into the corresponding 3D object. It is an end to end deep learning method that can handle highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations and digitize them in one unified way. The system was shown using only a standard webcam, a domestic RGB USB camera, but there is nothing stopping future work being done with much higher quality and using a higher resolution camera. Similarly, the background wall shown in the video was a flat colour but this is not a key aspect of the solution, the background is not significant. Even the lighting does not need to be professional or special. There is no use of polarized light sources or special filters.
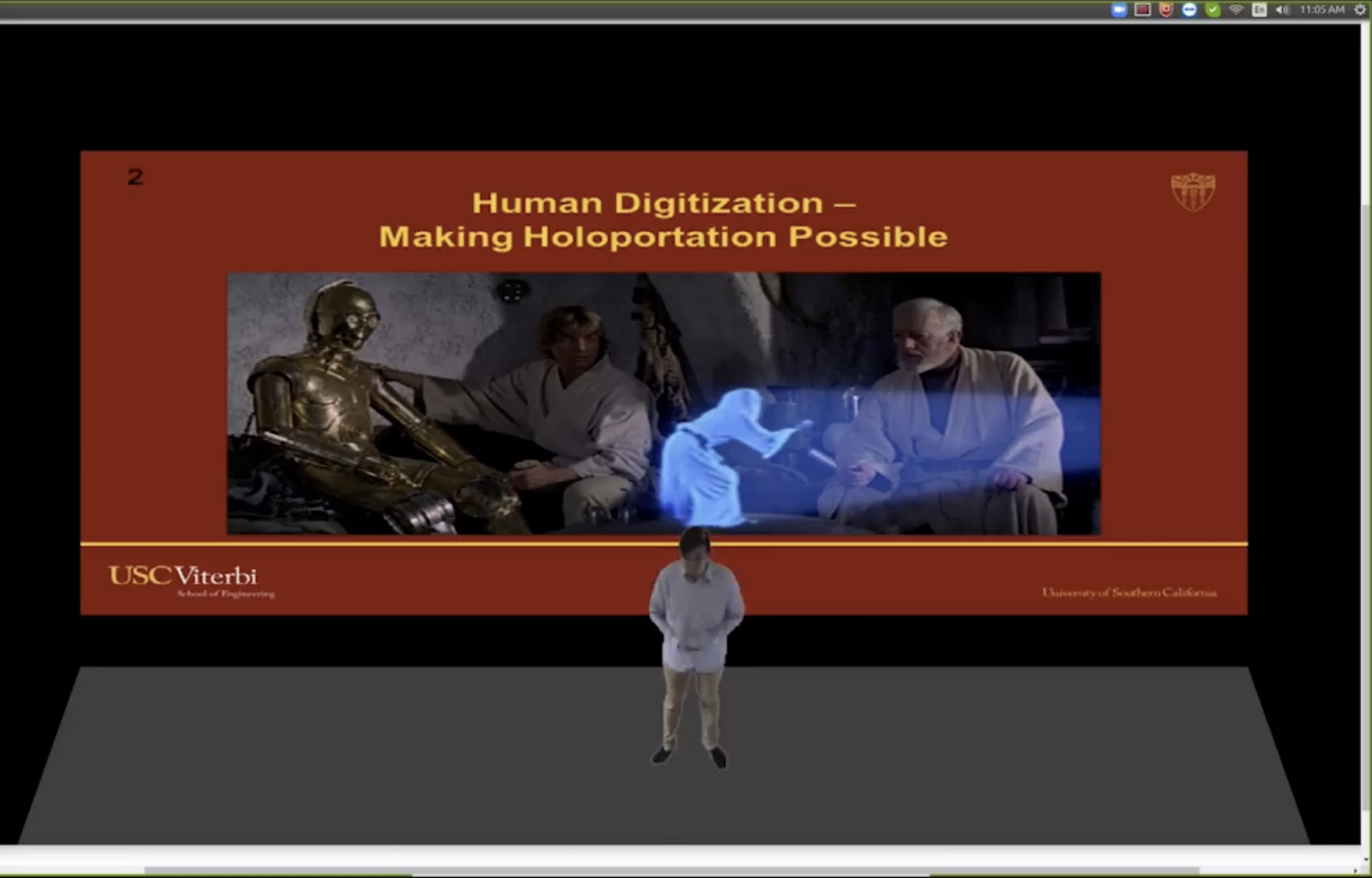
In an era where immersive technologies and sensor-packed systems are becoming increasingly prevalent, and in a COVID-19 world which is rushing to Zoom and video conferencing, this virtual 3D presence caught the imagination of the SIGGRAPH Jury. Monoport was a central part of Zeng Huang’s Ph.D. defense. Instead of presenting his final submission to his advisors and assessors as a normal Zoom session, Huang ‘Holoported’ himself into his own Powerpoint slide deck and presented to USC as a live volumetric monoport digital human.
Videoconferencing using a single camera is still the most common approach face-to-face communication over long distances, despite recent advances in virtual and augmented reality and 3D displays that allow for far more immersive and compelling interaction. While monoport could have easily been presented at RTL as a VR implementation, the team decided to use a mobile device to show the interactivity and ability to move the camera in real-time, instead of using a VR headset. Both approaches are valid, but the non-VR solution underscores the convenience, and ease of use of the main monoport system.

Successful reconstruction of not only the geometry but also the texture of a person from a single camera viewpoint poses a significant challenge due to depth ambiguity, changing topology, and severe occlusions. To address these challenges, the team adopted a data-driven approach using high-capacity deep neural networks. The approach is so successful it allows for two people to be capture from the same live-action feed, as was demonstrated during RTL. Central to the success of the process is the nature of Deep Learning where training may take some time, but the software is very fast when running. The training data the team used was a combination of a library of photogrammetry captured figures, and synthetic data that the team built from this base. As some of the library figures were rigged, the team could produce additional figures by both varying the original poses and applying different lighting to them.
One of the most impressive aspects of the system is seeing how well it handles people wearing additional things, such as backpacks or removing clothing such as jackets or hoodies without the system falling over. “The nice thing about deep learning is that it implicitly defines what it is, based on what you feed it with,” explains Li. “For example, a traditional computer vision method or model base approach you basically define what the human body is, – usually via a parametric template body, which is a naked body without clothing.” The monoport does not work with a base human model and thus it is both faster, more accurate, and involves less of a memory footprint.
Below is the original PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization (ICCV 2019) video.
High-Res version: PIFuHD
A higher resolution (non-real-time) version of PIFuHD: High-Resolution was also researched as part of an internship at Facebook Reality Labs/Facebook AI and presented by Shunsuke Saito recently at CVPR2020. But this higher resolution version is not only a non-real-time solution, but it is focused just on the geometry and it does not provide the aligned textures.
Digital Humans:
AI-synthesized Avatars: From Real-time Deepfakes to Photoreal AI Virtual Assistant
The other presentation Pinscreen had at RTL showed real-time ‘deep fakes’ and the work that Pinscreen has made in producing an end to end digital human. This includes the fundamental AI engine that drives the character, in this case, a digital Frances based on Li’s own wife. Pinscreen engineered the entire digital agent pipeline, “the only component that we’re using from a third party is the voice recognition, which uses Google’s API and the voice synthesis that uses Amazon Polly,” explains Li.
All of the processing of Digital Frances was done on the cloud and it was completely live. During the actual RTL presentation, Hao Li spoke to his digital wife. As the digital agent is not scripted, her interaction and responses are never the same twice, hence unlike any of the rehearsals, Digital Frances suggested that her real-world husband might need to get a regular job! “During the rehearsals, she always asked something different but during the show it was really different'” Li comments, “It was the weirdest set of questions that she gave. She asked things like, ‘Oh you should look for a job, what’s your age?’ And I was like, ‘man, why is she asking me these things?’, But then I thought, you know, it was kind of good because if it was perfect, it may not have seemed real or unscripted”.
In an upcoming fxguide story we will ‘talk’ to Frances directly.
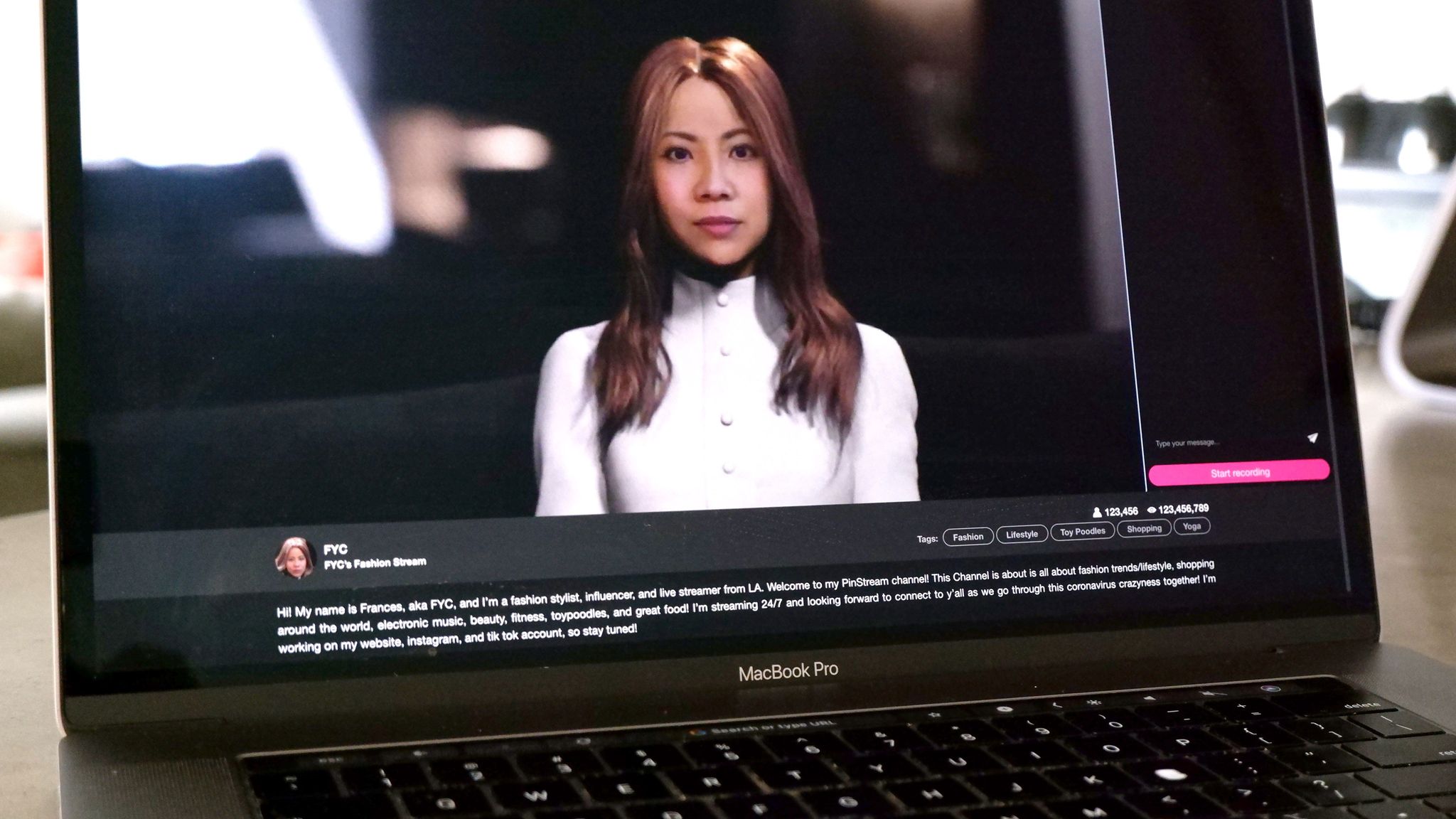
This other part of the demo was a real-time, deep learning-based facial synthesis technology for photoreal AI avatars. This technology allows a user to create their own 3D face model and transform into the face of an actor, athlete, politician, musician, or anyone. (Fxguide previously covered this tech).
