Last week the internet was abuzz with links to a new modeling approach shown in a YouTube video. The technique called ‘3-Sweep – Extracting Editable Objects from a Single Photo’ is to be presented in Hong Kong in November as part of SIGGRAPH Asia 2013. fxguide is again the official podcast of the SIGGRAPH Asia conference, and we spoke to one of the authors Tao Chen about 3-Sweep and his previous SIGGRAPH paper on automatic photo comps based on rough sketches.
Motivated in great part by the difficulty in sharing models and even making models, a group of researchers including Tao Chen realized that if a user could direct the computer, and if the solution used a combination of edge detection with some fairly reasonable assumptions – coupled with some texture projections it would be possible to make 3D models very quickly and simply of a whole range of objects – especially man made objects. The technique succeeds by not trying to solve being able to model everything, but just doing certain things very, very easily.
Many objects, especially man-made objects, are straight or have sensible curves and handles which themselves can be seen as extrusions. A cup is a cylinder which is just an extruded circle but then its handle is also likely to be able to be modeled also with a curved extruded oval. And once these shapes are defined the original texture projected onto the shapes is likely to give the appearance of quite a complex model. As most effects artist know, when you project a texture over a simple shape, the result can be quite appealing, even if the lighting is “baked in” and the back of the object is just a mirror of the front.
It is not that this 3-Sweep process produces the best models ever, it is that it produces a passable model very, very easily. While it is possible to immediately fault the model on close inspection, usually due to texture artifacts or non-responsive highlights or shading on rotation – the model is still quite passable for a number of great uses and it wins due to the sheer speed and simplicity of the process. It is easy sometimes to only focus on the high end – but for many mobile or game applications and even previs – close enough done fast is often more than good enough.
It is also easy to find examples that won’t work with this approach but to do this is only really useful in understanding how the technique works and the assumptions that are exploited. For example, a classic tapering tube of toothpaste starts as an extrusion of a circle and ends as a collapsed line. This will defeat the process. So too would images shot with large amounts of lens distortion – anything like a fisheye would confuse the assumptions of parallel lines. Hidden objects or obscured parts are nearly impossible to define. But if one avoids such things and focuses on household objects, there is a huge range of complex models that this approach really solves quickly, from lamps to taps, from candle sticks to telescopes, they can all be modeled edited and textured with ease.
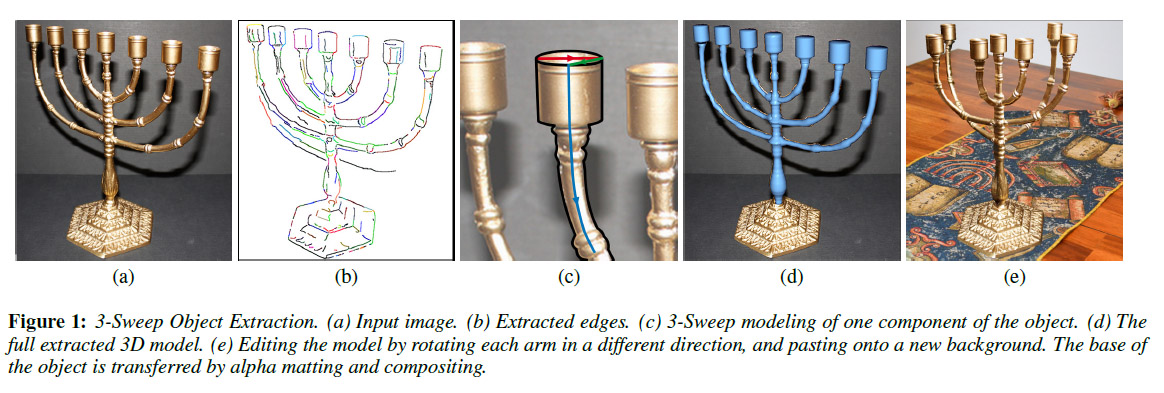
The process works on producing a base shape a box or circle and then extruding it. The extrusion does not need to be uniform or in a straight line – the assumptions are a valid cross sectional shape – related to the starting shape and a reasonable edge detection.
As seen above there are several stages. The program first takes an image and does edge object extraction. Then the user starts defining a shape and showing the sweep direction along which the program monitors edges to determine width and direction. This then produces a 3D model. Finally, textures are projected over and any sections of the model can be edited or replicated to produce variations or new objects, thus the object on the left produces a new objection on the right. Of course while the model is lightweight and yet appears complex, if the new object, say a candle holder, is rotated the highlights will not move and the shading will be baked in. Tao Chen identified this as an interesting area for further research – one that might attempt to produce a more neutral model in terms of texture and therefore one that could respond better to relighting and animation later.
The program uses a single image so it is hard for the program to sweep along complex three-dimensional curves, it is impossible without stereo or secondary images to interpret some shapes as receding and twisting or just say tapering. But surprisingly a huge range of objects do work inside the programs assumptions and they work surprisingly quickly.
Since the user helps define the original shape and pulls the sweep in the relevant direction the program can produce say a wine glass from a simple line drawing better than previous fully automated attempts, so the input does not even need to be a photography (although in this case texture extraction is skipped).
The paper will be presented at SIGGRAPH Asia on Tuesday, November 19th at 4.15pm. But already there is interest from a number of companies and programming teams. The most complex part of the process is actually the texture extraction and projection and any in-fill that is required to remove the object from the scene and provide a clean background plate.
Tao Chen actually presented once before at SIGGRAPH Asia – a couple of years ago in 2009. He and Ming-Ming Cheng, Ping Tan, Ariel Shamir and Shi-Min Hu presented a similarly “auto-magic” graphical application that would make you a comped image from a simple, rough or crude drawing with a few key words.

In this earlier paper the computer would search the net for image groups that matched the names and poses, then sort to eliminate exceptions, match image sharpness, grain/noise and quality – extract the items you wanted and blend them fairly seamlessly into a new still image. Want a guy throwing a Frisbee at a dog leaping in mid air on a hill? Just draw the super rough shapes and positions, label two or three things like ‘dog’ and the program does everything else – automagically presenting almost exactly that shot faked up.
Take a look at the video explaining the research below.
And you can find out more details about SIGGRAPH Asia 2013 in Hong Kong at http://sa2013.siggraph.org. Stay tuned to fxguide for more coverage of presenters, talks and events from the conference.