In this second part of our FXG look at Machine Learning in VFX, we focus on the work of Pinscreen that will be shown at the Real Time Live event, next week at SIGGRAPH. Hao Li is CEO/Co-Founder of Pinscreen, Assistant Professor of Computer Science at the University of Southern California, and the director of the Vision and Graphics Lab at the USC ICT. Hao’s team will be showing an incredible new advance in what is possible using a number of new technologies, many of which use Machine Learning (ML). One aspect, in particular, is remarkable. The team breaks the traditional pipeline of model, texture, light and render. In so doing, they apply machine learning in a way that is revolutionary.
Importantly, Pinscreen’s research work is both high end (PC based) and mobile friendly (Phone/mobile based). By working at both levels the team provides immediate applications while also working on important long term fundamental research, that will eventually be common place. This dual approach is key to understand their demo material as some clips and examples below take iPhone input but process it off the mobile platform, while other work is fully available (as of next week @ SIGGRAPH) to experience as a working App on your phone.
 Hao Li’s career in computer graphics and computer vision focuses on digitizing humans and capturing their performances for immersive communication. He took over at USC ICT from Paul Debevec when Paul moved to Google. Hao’s aim is a little different than Paul’s, as he seeks to bring facial capture and simulation to the widest possible audience.
Hao Li’s career in computer graphics and computer vision focuses on digitizing humans and capturing their performances for immersive communication. He took over at USC ICT from Paul Debevec when Paul moved to Google. Hao’s aim is a little different than Paul’s, as he seeks to bring facial capture and simulation to the widest possible audience.
Li’s research involves the development of novel geometry processing, data-driven, and deep learning algorithms. He is known for his seminal work in non-rigid shape alignment, real-time facial performance capture, hair digitization, and dynamic full body capture. He was previously a visiting professor at Weta Digital, a research lead at ILM / Lucasfilm and he was named top 35 innovator under 35 by MIT Technology Review in 2013.
The Pinscreen team has used our own Mike Seymour for some tests and models, but this is not the same application or data as last year’s MEET MIKE project or UE4.20 MIKE. Li’s team did however have access to the Wikihuman/USC ICT scan of Mike, as a ground truth reference. Pinscreen works from normal phone quality input data, and NOT the rich data the USC-ICT lab can provide with the USC Light Stage. In this article, the face of MIKE was made from Pinscreen’s own Jpeg conversions of fxguide’s (ageing Aussie) real Mike Seymour and not from a Light Stage Scan.
No data has ever actually been fabricated or reused in any of Pinscreen’s published papers or Real Time Live demos. All their experiments and research results are conducted with an eye to scientific best practices and academic publishing. The company is very keen to give back to the Academic and professional research community. All their research is at senior University level for verified and double blind review. Which, of course, reflects Li’s senior role inside USC.
Photo Real (Highest level)
Below is a video of fxguide’s Mike Seymour. On the left is the source video which was shot on an Apple iPhone. On the right is the realtime rendered CGI , 3D digital face (hockey mask) of Mike digitally composed over the same source video. There was only a tiny amount of adjustment to the blend edges, otherwise this is an automated process.
https://vimeo.com/283234517
If you look carefully some of the wrinkles in Mike’s head are smoothed out, but the match is extremely good, (and it is all automatic).
1. Single Jpeg -> to build the face
The team at Pinscreen are building their 3D face models using a single Jpeg image. It does this by ‘guessing’ (using ML) what face 3D shape would best match the input image. There are several companies doing this with a variety of ML approaches in addition to Pinscreen, Many companies have base their business models on just this level of innovation. Pinscreen goes much further. It aims to provide an end to end solution.
This first step of identifying a face and making a plausible 3D mesh is difficult, but it is what Pinscreen does with this mesh that is truely innovative.
This first face tracking stage makes a very good model, but this model is not then just refined and passed on and into a traditional pipeline. This model helps the later stages ‘render’ using a whole new approach. This is unlike our previous fxguide story on AI for VFX Part 1. In that article we told the story of making a better model with better textures, so the face could go into any traditional pipeline. Pinscreen’s approach is different.
2. 1000 frames per second face tracking
Mike Seymour’s face above can be tracked immediately at up to 1000 fps. Why so fast, given the cameras run typically only 30 or 60 fps? “It allows us enough time to track multiple faces in the same frame” explained Li.
The tracker is called VGPT which stands for Veli Goodo Pace Tracka and was lead by Pinscreen developer Shunsuke Saito. On a PC with a 1080P GPU NVIDIA Graphics card VGPT runs at 1000 fps. On the iPhoneX it runs closer to 60 to 90 fps. “The other huge advantage of our solution is that it takes so little memory, the core without I/O is just 5 Megabytes, and it is completely based on deep learning” explains Li. The solution is based on direct inference, it is not tracking features or marks as a traditional tracker would. An older tracker would use AAM model based facial landmark detector and be a lot slower. This solution provides an “exact head model in 3D, relative to the camera, and FACS expressions and all that important stuff” says Li.
The tracker is using a set of ML tools to do very fast markerless tracking. Not only does the face track well, but it is very forgiving. If one moves across the frame, partly blocking the camera, the program will reacquire the face very quickly and keep working. The robustness and speed make this a very powerful tool. The tracked and solved face is then handed to the next stage.
The VGPT is not the only tracker Pinscreen has, but it is the most powerful and a late addition into their SIGGRAPH Real Time Live Demo fro next week.
Above, Pinscreen took a single input photograph of LA Times reporter, David Pierson, and made a photoreal 3D avatar of him. This generated face (right) and is then animated through the performance of Pinscreen’s Hao Li, (it is therefore Hao’s voice). Note this video above, is now 6 months old and already surpassed internally by the team.
3. paGAN
paGAN stands for Photoreal Avatar Generative Adversarial Network. It is the ‘Renderer’ of the Pinscreen system.
Up until now, traditional ways of modelling, texturing, lighting and rendering avatars or digital people all required building very high quality assets. This typically starts with multiple images to build a photogrammetry style solution, with very high quality scanning. On to this mesh is placed “high quality textures, bump maps, specularity maps etc, and in addition to the shaders, -you also needed a very high quality rendering algorithm”, explains Li. “Everything has to work hand in hand and be perfect so that you can pass the Uncanny Valley”. In addition, a pipeline needed very experienced staff and artists to control and moderate the technology. “We thought that this is incredibly hard,… if you put sufficient effort and resources you can create great results – such as at ILM with Digital Princess Leia, and MPC’s Rachel in Blade Runner 2049” he adds. But what Pinscreen seeks to do is produce high quality digital humans without expensive scans and without the need for dedicated high end expertise. They aim to allow “ordinary people to create avatars of themselves”.
To solve this, Li and the Pinscreen team skip the traditional pipeline approach. “If you take a video of yourself and send it to me, it is completely believable, it just isn’t 3D. What if whatever you captured is what you see, but with the traditional degrees of freedom of computer graphics” he ask. While it sounds like science fiction, the approach is to ‘film’ someone – even just one frame, and then be able to look at that ‘video’ from any angle or animate it as if it was normal 3D. This is in stark contrast to simulating a face with the normal 3D pipeline.
“Sample with ML” not “simulate with CGI”
The Pinscreen team aims to take this to the point that the sampled face can be relight, reanimated, rotated and placed in a simulated 3D environment just like a 3D CGI head. But without the use the normal pipeline of modelling/texturing/lighting and rendering. Traditional Photogrammetry with a recovered stitched texture, can be thought of as a step in this direction, but that approach fails as the head cant be relit properly nor fully animated. The results look real, as it is really just a picture projected on top of matching geometry, but it only works when static.

What Pinscreen are trying to do is see if they can use state of the art, deep generative models to make a general solution. “A very specific type of deep learning network, that encompasses Generative Adversarial Networks. These have the capability to generate photorealistic 2D images. We know GANs can produce believable 2D images, a lot of other researchers have show that” explains Li. Building on the work of “the seminal work by Ian Goodfellow and lots of great work by NVIDIA, it has been shown that you can train a neural network to synthesise high quality facial images” he adds. Li and his team wondered if they could turn this new technology into a facial render engine, that skips the modelling, texturing and lighting pipeline. Instead it just ‘renders’ the face from the right angle, but using GAN ML.
paGAN is a ML GAN network that renders a photoreal face based on input of a simple model (with a small amount of texture), that simple model comes from their VGPT.
SIDEBAR: GAN: Generative Adversarial Networks
GANs are one of the hottest topics in Machine Learning. Research in this area has exploded since 2014.
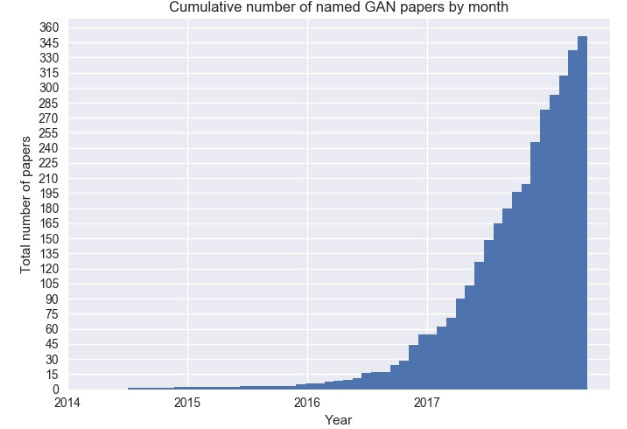
A GAN is a ML model that is capable of generating data rather than an estimate of the density function. But the most impactful way to think of a GAN is imagining two ‘AI’ or neural networks trained end-to-end against each other. There is a Generator (G) and Discriminator (D). The idea being the Generator wants to beat the Discriminator. We saw a version of this in Part 1 of this series. It was invented and first published by a team at Google Brain lead by Ian Goofellow in mid 2014. Deep learning pioneer and Facebook AI director Yann Lecun called GANs “the coolest idea in deep learning in the last 20 years.” Wired Magazine described GANs as “Google’s Duelling Neural Networks Spar to Get Smarter, No Humans Required”.
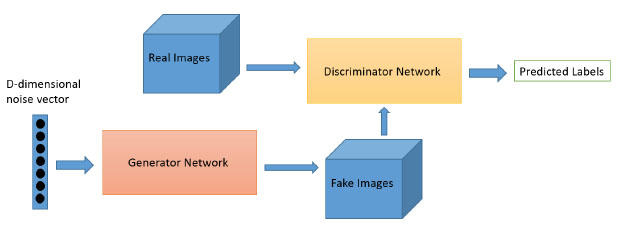
In simple terms: think of corrupted policemen and corrupted counterfeiters. The corrupt police keep telling the counterfeiters what they need to do to make their forgeries better until the corrupt police can’t tell the difference between the real ‘forgeries’ and the real thing.
The generator G takes as input random stuff/fake images and attempts to generate new data intended to resemble real data. The discriminator network D tries to discern real data from generated data. As the discriminator network improves its ability to correctly classify the data, metadata is sent back (or “back-propagated”) to the generator network to help it do a better job of trying to fool the discriminator network.
paGAN excels with eyes and mouths.
The problem with a GAN when used for faces is that output is 2D and ‘vanilla GANs’ are very hard to control. “You can get arbitrary blobs with GANs and they are very hard to control. What we have been doing with paGAN is making sure that the output looks photoreal, specifically in the mouth and eye regions” says Li. Earlier work did a similar job, but did not include the eyes or the mouths. These were just blank holes.
“The mouth, and the way the tongue moves in the mouth is one of the things that paGAN does very well” says Li.
4. Retargeting
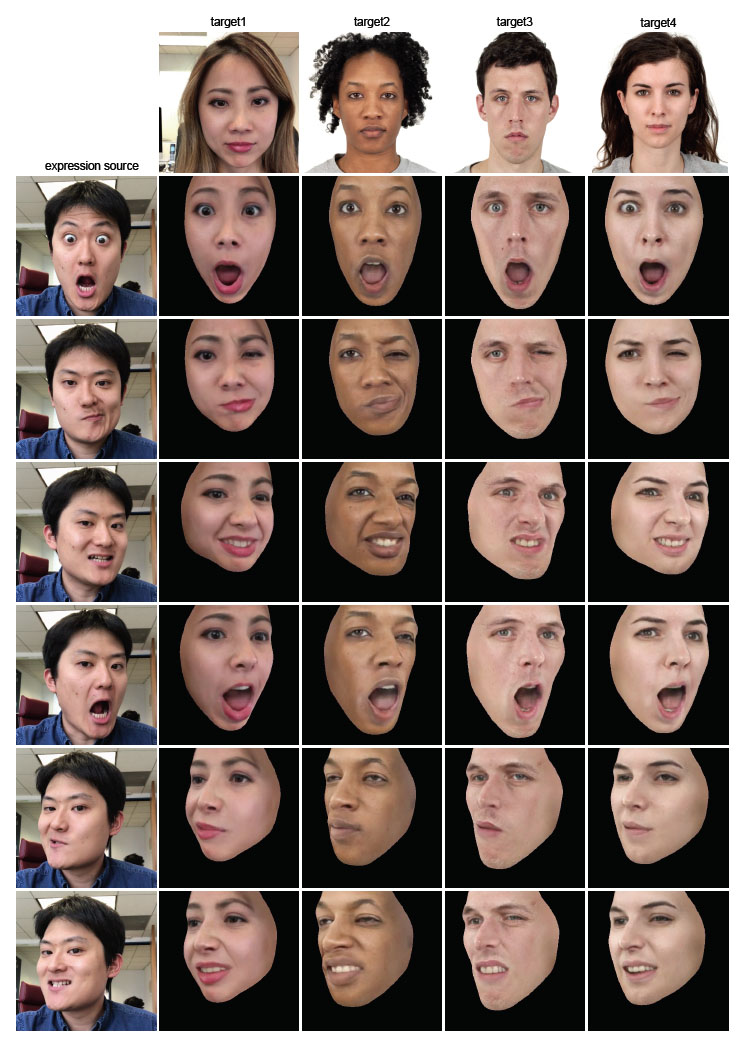 As a face can be made from a single Jpeg and then all the expressions derived from the new expression source, this technology is perfect for animating someone else’s face in a believable and plausible way.
As a face can be made from a single Jpeg and then all the expressions derived from the new expression source, this technology is perfect for animating someone else’s face in a believable and plausible way.
Again it is important to remember when looking at these results that the manipulated faces (right) are made from just one still jpeg image (top) and no other FACS inputs or special scans. All the expressive faces are a transfer from the expression source onto the targeted people.
Hybrid and Lighting
Given Hao Li’s background and experiences with companies such as ILM and Weta Digital, he knows that his face tools need to work in a pipeline that may have a V-Ray, Manuka or RenderMan renderer. “Right now our solution is a hybrid solution that works pretty well. One of the demo solutions we will be showing at Real Time Live at SIGGRAPH is exactly that”, he says. “A photoreal face is a good technical demo, but at Pinscreen we want to make it useful for people to use… if you have a 3D face or avatar, you need an environment otherwise there is no point” he adds.
For this reason, a paGAN face is not only able to be ‘rendered’ from any angle but also in any lighting model required to sit the face in the scene. “Being in an environment means a face can be rendered from any arbitrary direction and with the lighting conditions of that environment”.
Pinscreen currently address this technically by solving for a photoreal albedo of the face, (it is not a 100% albedo but it is close). “With this albedo texture, when combined with the rest of the pipeline that uses traditional computer graphics, you can achieve a compelling result”, explains Li. The solution is not unlike a volumetric video result.
When deployed in user testing, the CGI faces approached a near perfect score, performing very close to being able to perfectly fool the users compared to real faces presented the same way, in a similar context.
Phone Level (Direct)
Below is the pipeline for the single Jpeg to final iPhone character. We have included below that the source image of Mike Seymour. While the Pinscreen team could use the depth camera, this iphone real time Mike was made with a single Jpeg image and not the depth camera sensor data. The image was taken on an iPhone X but using the non-depth sensing camera.


“At Pinscreen we have two teams, one that is focused on making things that are fun for people to play with,…and at the same time we have a very strong research group. This group focuses on fundamental questions”.
Pinscreen wants to democratise 3D avatars, but why do people need avatars? “First of all, most of the games are 3D and most have a large percentage of humans, but I think it can go much further than this”, says Li. He sees applications in 3D communication, a 3D version of Skype, “in a way that I perceive you as actually here in our office. That is the only way for people to really work together to fully solve problems together and communicate ideas and emotions… that is the key to building trust”. He says he looks forward to a day when we will really feel as if someone is there in the room when using 3D avatars, but “to do that you can’t rely on on a game or film research studio to capture your face data,- it has to be something that is smart enough to build all this complexity based on limited knowledge or exposure”. This is why Pinscreen has committed so heavily to advanced ML and specialist GANs.

The Pinscreen strategy is to build the ‘game’ level mobile platform first, “but this is the platform which we will be able to use to deploy all the new research technologies that we are developing”.

Above: the team train a GAN that can produce expressions in various viewpoints given a neutral jpeg face image. On the right the extracted textures from the trained network is used to drive a dynamic avatar in real-time on the Phone.
The network is trained using a massive face image dataset that captures a wide range of subjects and expressions. paGAN cannot run on the current iPhone hardware at a satisfactory frame rate, due mobile hardware limitations. Once the network is trained, it is used to generate a small set of fixed key expression textures. This fixed or sparse set can then be expanded to a complete set of Facial Action Coding System (FACS)-based blendshape UV texture maps. Once computed, the textures can be used to create the avatar with a wide range of expressions, all driven by the tracker in real time on the phone at 30 fps. It is synthesizing per-frame textures online live. This mobile ‘compression’ is an important part of the Pinscreen solution and it will also be shown at SIGGRAPH.
paGAN works so well as it is not only used to make the face, but also the mouths and eyes. The program does 300 inner mouth textures and 20 pre-computed eye-textures for the avatar. The eye textures from paGAN can then be used to approximate all viewing directions. Using the gaze tracker on the mobile device such as the iPhoneX, the program picks the closest gaze and composites the appropriate eyes onto the appearance.
Hair
The final component is the character’s hair. The example frames above use Pinscreen’s Data Driven Hair solution. This was previously published by Hao Li and the team. The team is working on a remarkable new hair simulator that fxguide got a preview of, but as this new approach is only now being submitted for publication, it will not be used in this year’s Real Time Live Demo. The new system is another end to end neural learning solution, that will always produce a plausible hair model based on the training data.
Real Time Live
At Real Time Live Pinscreen’s demo is titled: Deep Learning-Based Photoreal Avatars for Online Virtual Worlds in iOS
It is described as showing “a deep learning-based technology for generating photo-realistic 3D avatars with dynamic facial textures from a single input image is presented. Real-time performance-driven animations and renderings are demonstrated on an iPhone X and we show how these avatars can be integrated into compelling virtual worlds and used for 3D chats.”
This will be presented by multiple members of the team:
- Jens Fursund, CTO
- Koki Nagano, Principal Scientist
- Jaewoo Seo, Director of Engineering
- Kyle San and Aaron Hong, Software Engineers
- and Hao Li
The plan at the time of writing is to scan and recreate a volunteer’s face on the night of Real Time Live. The Pinscreen team will then based from this single jpeg image, the team will drive/animate the face in real time. The team will show how this can run on the phone without the power of a TitanX or 1080 Card. Finally, the team will show a Unity world, (but to see what happens in this virtual world example, you will need to attend SIGGRAPH in Vancouver next week!)