Emotion Challenge
Detailed character animation and facial performance is increasingly becoming important for AAA Games. This is directed at both rendering realism and animation performance. Activision was founded in 1979 and was the world’s first major independent game developer. Today, Activision Blizzard is one of the largest AAA game publishers in the world. Inside the company, the Activision Central Technology team recently mounted a project to look at improving their facial performance pipeline.
The CTX team within Activision’s Central Technology division has focused on developing powerful solutions for facial capture, solvers and performance reproduction, but they need to do this across a variety of different project pipelines and occasionally involving external vendors. It work was seen as important as it is often challenging to maintain visual consistency, even from character to character within a single project. The CTX team identified the need to research a unified, robust, and scalable pipeline for actor likeness acquisition, performance capture and character animation.
 To tackle this problem they created an internal research project known as the “Emotion Challenge”. Using the latest technology including their own acquisition of an ICT Light Stage, the team set out to research and document each stage in a facial pipeline and assess it for production viability. They then set to translating these research efforts into real world techniques that could be implemented to augment and extend existing approaches across a range of projects.
To tackle this problem they created an internal research project known as the “Emotion Challenge”. Using the latest technology including their own acquisition of an ICT Light Stage, the team set out to research and document each stage in a facial pipeline and assess it for production viability. They then set to translating these research efforts into real world techniques that could be implemented to augment and extend existing approaches across a range of projects.
The Emotion Challenge set out to build something that would work within current model and rig limitations and looking forward, could also:
- efficiently handle a large number of characters and a large volume of performances,
- achieve consistency with pre-rendered cinematics, and
- support a wide range of animation pipelines and game engines
Tucker Smallwood
 Tucker Smallwood was the actor chosen for the Emotion Challenge. Smallwood served in the U.S. Army Infantry, Airborne from 1967-1970, commanding a Mobile Advisory Team during the Vietnam War where he was severely wounded in action. After recovering from his injuries, he became an actor on Broadway, in film, and on television. He also wrote a book about his Vietnam experiences, and speaks publicly about his experiences with Post-Traumatic Stress Disorder.
Tucker Smallwood was the actor chosen for the Emotion Challenge. Smallwood served in the U.S. Army Infantry, Airborne from 1967-1970, commanding a Mobile Advisory Team during the Vietnam War where he was severely wounded in action. After recovering from his injuries, he became an actor on Broadway, in film, and on television. He also wrote a book about his Vietnam experiences, and speaks publicly about his experiences with Post-Traumatic Stress Disorder.
Smallwood was scanned and provided the emotionally-charged, technically demanding baseline standard for the challenge.
Pipeline Overview

Likeness Acquisition
To faithfully capture an actor’s likeness for recreation as a digital in-game character, Activision started with their new expanded version of the ICT Light Stage system. This stage is known as “Likeness Acquisition”.

 The Activision Light Stage uses 16 DSLRs for high-resolution geometry and reflectance reconstruction using polarized gradient illumination. As with the original USC ICT Light Stage, this allows isolation of specular and diffuse skin textures and high resolution geometric reconstruction.
The Activision Light Stage uses 16 DSLRs for high-resolution geometry and reflectance reconstruction using polarized gradient illumination. As with the original USC ICT Light Stage, this allows isolation of specular and diffuse skin textures and high resolution geometric reconstruction.
Activision augmented the DLSRs with 35 machine vision cameras capturing at 70 fps. These cameras filmed the movement of the actor’s face between the neutral pose and each of the various extreme poses.
The first thing obtained from the 16 DSLR rig is the actor’s neutral pose. This provides the base geometry reconstruction, the surface normals and the facial texture. “But when you want to go to the actor’s other poses, that is done with a combination of these XIMEA computer vision cameras and potentially also the DSLRs,” comments Alex Smith, Animation Director at Activision, Central Tech. The vertex deltas of the different poses comes from tracking the animation mesh based on the neutral pose shape. This is tracked as the actor goes into each pose, but to make wrinkle maps for any of those key poses, the DSLR data can also be used. The stills from the DSLR are clearly much higher resolution than any frames from the computer vision cameras which are just grayscale footage: 2k x 2k @ 70fps.
This enables correspondence of the animation mesh topology, not only with each extreme pose, but also with all the intermediate poses. Correspondence between poses is as important an aspect as geometric reconstruction of the face at any pose. The high resolution details can be projected back onto the same modified base mesh. Correspondence is key in facial animation. Obtaining a single photogrammetry pose is relatively easy, but building a face that can accurately move between poses is at the core of human facial capture.
If only the DSLR pose reconstructions are used, then there is no correspondence between any two pose meshes. But by tracking a mesh between poses and then adding back the high frequency wrinkles, the mesh is the same mesh and thus has a 100% correspondence. “By doing it this way, the mesh topology is consistent and thus we have one common animation mesh which was formed from the neutral pose and then we are able to deform it (via the machine vision cameras) and each new pose then has the high detailed added on. This means the textures are all in a consistent UV space”, explains Smith. If the alignment is not accurate then the projection of the DSLR data as blended wrinkle maps may produce a “ghosting on the image or face, where it seems like some detail on the face is from one location and other detail is from another,” he adds.
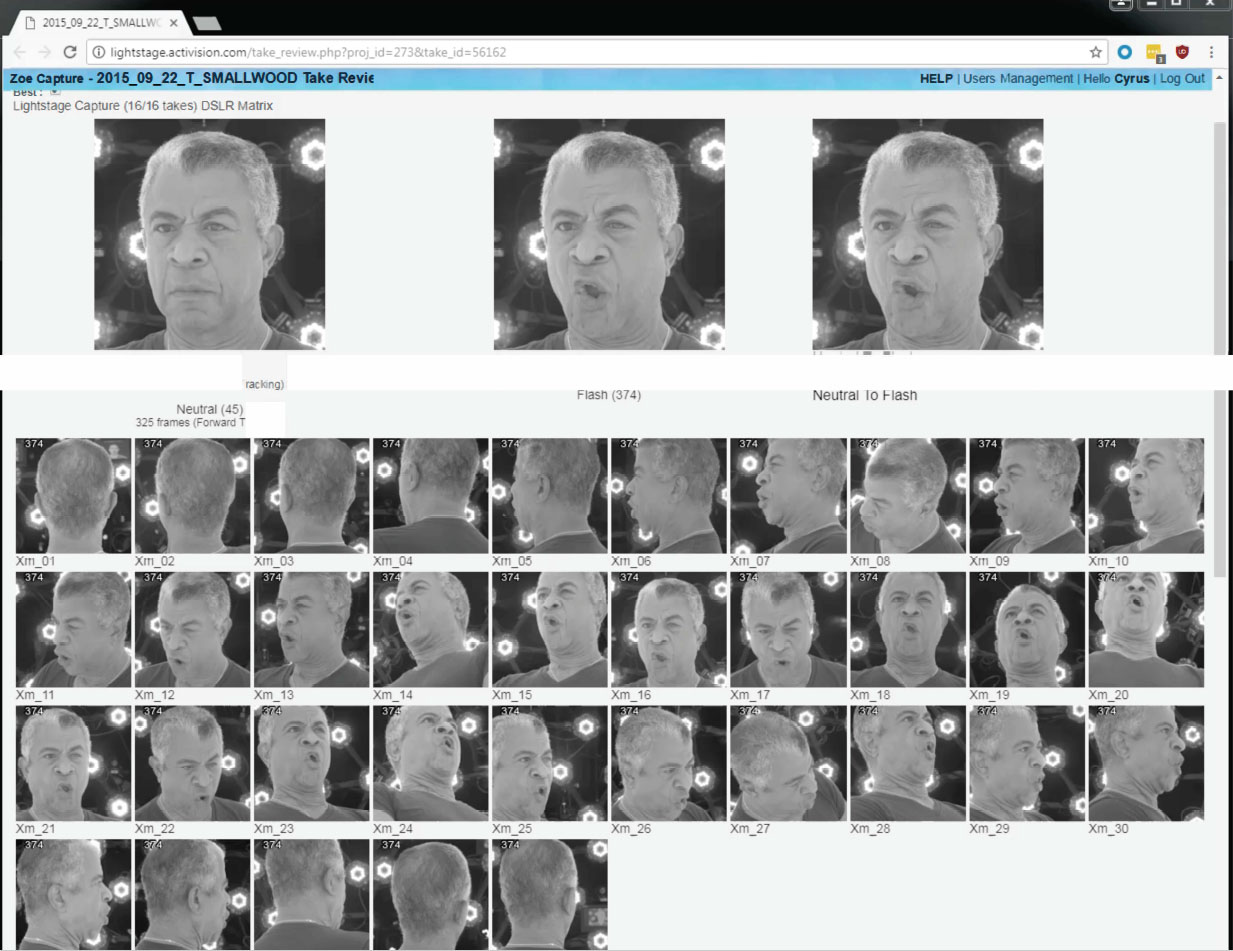
It is worth noting how the Activision Central Technology team use of their Lightstage is different from both USC ICT Light Stage and other similar spherical capture systems such as the Disney Research Medusa system, used in companies such as ILM. The very successful Medusa Rig works with a machine vision, temporal tracking approach with constant illumination, while the USC ICT original Lightstage is known for its’ remarkable and detailed diffuse/specular separation based geometric reconstruction. Activision appears to be somewhat of a hybrid, it still uses the USC ICT Light Stage illumination patterns developed specifically by the USC ICT researchers under Dr Paul Debevec, but it also aims to do temporal tracking (although differently than the Disney Research team).
Beyond scanning, rigging is a unique exercise for each project. Each game team has their own face rig and that means each has its own topology. The game team’s character artists take the data from the Light Stage session and regionalize mesh deltas to derive blendshapes for their specific face rigs of their own project.
Hand polishing
Extensive animator ‘hand polishing’ of characters to a high level is traditionally expensive. Activision estimate that blendshape cleanup, when handled by external vendors, costs approximately US$25,000 per character and takes on average 2-4 weeks turnaround time. By the end of this research project, the Activision team believe they have gotten this cleanup to a point that it can be handled internally. Additionally, they estimate it will take just 1-3 days (for one artist to do per one character) and it can be done using with roughly the same pipeline for background as foreground characters.
Personalised Blendshapes
Activision is also researching, but not yet using, automatically generating personalized blendshapes from an actor performance while preserving the fundamentals of the underlying template facial animation rig. Once implemented, they could then do a 3D reconstruction from each pose using an image-based tracking algorithm. The core of this possible new framework is an optimization algorithm which iteratively refines the initial estimation of the blendshapes such that they can fit the performance measurements better. This framework could facilitate creation of an ensemble of realistic digital-double face rigs for each individual with consistent behaviors across the character set.
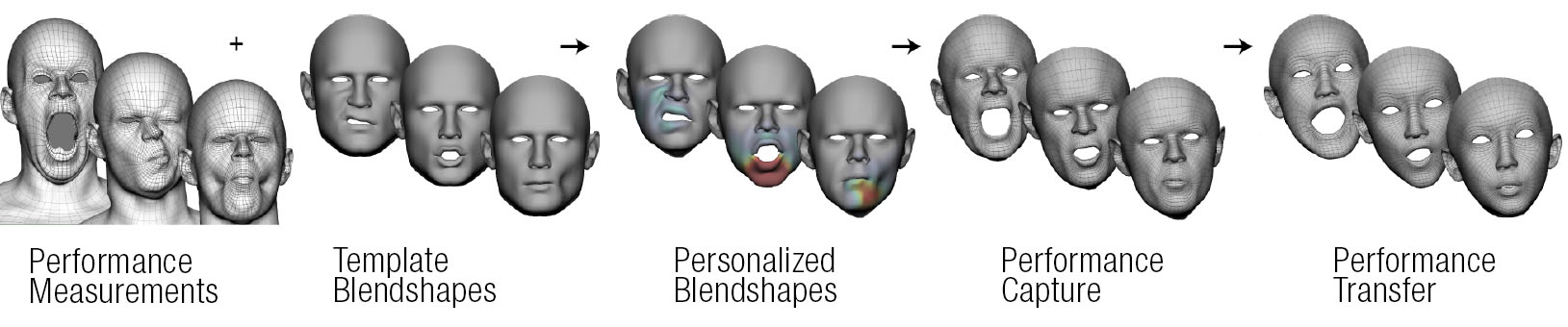
Performance Capture
Once a rigged face is built, it needs to be driven by an actor’s performance. This requires accurate tracking and solving of the actor’s expressions into their expression space which can then translate to the rig built from the Light Stage.
The creative aim of the performance capture research stage was to
- capture and convey a genuine emotional performance using a pipeline viable for games,
- capture very subtle emotions, and
- provide good results without extensive animator ‘hand polishing’ (see above).
“Beyond” FACS space
During likeness acquisition, the team captured a comprehensive set of facial expressions that are designed to cover the full range of motion of the actor’s face. “Whilst we initially used a typical FACS-based expression set, we’ve since refined and augmented that approach to include a large number of non-FACS poses designed to target specific facial motions that occur regularly during actors’ performances” explained Wilson. “Particularly those involved in articulating dialogue across varying levels of (performance) intensity”.
The team also identify and capture unique expressions that a particular actor may use to portray character traits specific to their role. This allows them to build a more complete ‘motion likeness’ of an actor; one that is attuned to the expressiveness typically seen during their specific acting performances.
Additionally, the system is not just capturing static facial poses. “With our system, we also capture the action of the actor’s face moving into those expressions, and are able to select any frame within that motion to extract as a blendshape.” Wilson adds.
HMC
For facial performance capture, Activision acquires stereo 60 fps footage using a head-mounted camera (HMC) system with a vertical stereo camera pair. The rig shown below was built by Technoprops. These rigs are the default ‘state of the art’ industry standard for premium HMC rigs, as they are both accurate and lightweight.

The on-actor facial acquisition HMC system allows for complex facial performances. Activision decided to use a marker system involving makeup dots applied to the actor’s face. These dots are then tracked using a semi-automated tool, producing a sparse input to the solver. The tracking markers were placed where the team found them to be most effective. They started with about 32 to 40 in the research project, (especially when the challenge project was exploring dense stereo reconstruction). In production, they stopped using dense stereo reconstruction and now typically use around 56 markers for production work. These are solved with Activision’s own in-house tool. The markers are also used in overall head stabilization.The whole process is not real-time and the face tracking is one stage in the overall pipeline that does involve some manual artist intervention.
Exploring dense stereo reconstruction
For dense inputs Activision had computed a dense stereo reconstruction between views on every frame, as well as a dense optical flow from each frame to the next. This was all fed into an optimization which fitted the input data using the blendshape basis constructed for that actor based on the above Likeness Acquisition Phase.
In the end, the team wanted the performance capture solver to compute the blendshape weights and rigid head transformation per-frame.

Dense stereo reconstruction was explored in the Emotion Challenge but was not used in the production. This is in part due to the highly variable light sources in production compared to what the team could achieve in the controlled research lab conditions.
In-engine Animation
The per-frame blendshape weights can be exported directly to engine to drive facial blendshapes at runtime. Or, depending on the project pipeline, they can be used as inputs to a facial animation rig for additional animator polish prior to export.
Inhouse Test Game Engine
The team built a prototype that used dense stereo and markers around eyes & mouth. This ran on their R&D test-bed internal game engine. The team did 3 performances using this test pipeline rendering in their internal engine.
Transition to Production
The Likeness Acquisition pipeline has proven scalable into production,thus far having been applied in the creation of approximately 215 in-game characters. The ‘Emotion Challenge’ project demonstrated that the performance capture process was most viable under ideal conditions. “For the actual application in production,.. the way we use it in production, we aren’t quite getting the quality bar that we did under ideal conditions, ..we ended up, giving up some of constraints of the research project to embrace the realities of production” commented Alex Smith.
As mentioned above, the other big difference between the Challenge and the production approach was the lighting. During the research testing, actor Tucker Smallwood sat facing a surrounding bank of LED lights panels for even lighting, “In production, actors do not sit with consistent light, so we use the LEDs mounted on the Technoprops HMC helmet and we added more ambient light to their MoCap stage in general” adds Michael Sanders, Senior Visual Director at Activision.
The non-ideal conditions encountered in production present additional challenges for any performance capture process, for example, in addition to non-optimum lighting, actors might be sweating, head-gear or helmets might move, there can be focus issues and motion blur.

Principal Component Analysis (PCA)
Technically, Principal Component Analysis (PCA) is a statistical procedure that uses “an orthogonal transformation to convert a set of data of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components“. In lay terms, it can be thought of as revealing the internal structure of the data in a way that best explains the variance in the data.
After the initial research project, the team sort to improve the process and came up with a solution that involved PCA as an intermediate process, this was in part, to achieve consistent results regardless of how different studios had set up their shapes.
From this, the PCA solution was developed as a tool for practical production. “Instead of solving directly to the animation rig shapes, we solve to PCA shapes and then we go from the PCA shapes to the animation rig shapes”.
The PCA Basis (normally derived from the animation rig shapes given back from the studios after the first stage).
PCA played a key part in the final production pipeline. From the representative samples of the facial deformation, a mathematically-derived shape basis is calculated for the solver. The system applies PCA to obtain principal modes of the actor’s facial deformation. It selects the PCA shapes to account for the most significant approximately 92% of shape variation. It then leverages the inherent weighting in how much statistical variance each PCA shape accounts for, such that the solver prefers PCA shapes responsible for the major modes of facial deformation, only dialing in PCA shapes which account for minor details as needed.
In this way, the solve is more robust to noise in input performance data.To convert from this first PCA solve intermediate to the final solve, a second pass is needed to retarget per-frame PCA shape weights for a given performance to per-frame animation rig shape weights. The pipeline offers two options for this conversion.
Option 1, Change of Basis: In this approach, each animation rig shape is approximated as a linearly weighted combination of PCA shapes. Therefore, conversion between per-frame PCA shape weights to animation shape weights is simply a matrix multiplication. In the simple case, this is sufficient.
Option 2, Second solve pass: This alternative approach applies a second solve pass to best match the per-frame vertex positions (by applying the PCA solve weights to PCA shapes) with a new solve to animated shapes. The second solve includes sparseness and temporal smoothness terms, which can be tweaked, as well as the ability to exclude specific animation rig shapes for a given performance. Such parameters are also present in the first solve pass. However, the second solve (to vertex positions) is significantly faster than the initial solve (to input data). Therefore, in production, the parameters of the initial solve are tweaked relatively rarely, whereas the parameters of the second solve pass can be quickly iterated on per-shot. This approach allows the pipeline to better deal with the variety of scenarios which can occur in practice.
From the 56 markers combined with optical flow, there are about 90 PCA shapes per actor/character. This is constructed from approximately 120 shapes, and re-solved to ~70 animation rig shapes.
This PCA approach seems to work well and goes a long way to removing the prior approach of using a lot of manual tweaking and hand polishing.
Above: Comparing a re-solve PCA pass approach with an ‘animation approach’ (that was polished by an actual human animator). As one can see, there is now little difference between the two.
Time to process
Once the team have the data from the camera, there is the supervised/ semi-automated process, of tracking, (discussed above) and then the first PCA pass which “slower than real time and then do you do a second pass solve and visual it, but we want to reduce the amount of time, so that on set you can review in the afternoon, everything you had shot in the morning, or perhaps the next day in dailies.. but we are a long way from achieving final quality in real time right now”, comments Sanders.
“Anyone who is pushing real-time is not acknowledging the real world practicalities” comments Smith. “Often times the asset is not ready by the time you are doing the creative (capture) process, and there is a danger in the real time approach. Most real-time assets are a (simplified) subset of the fidelity of the real assets and the problem is that the creatives can get caught up in the limitations of the rig or fall in love with a sub-standard performance that they see on set, and then you are stuck trying to match that with the high fidelity rig later”. Activision CTX team instead suggests that creatives view the HMC footage directly and then “we can guarantee the final will match that later”.
Future directions
While some 215 actors have been through the Activision Light Stage for multiple productions, so far only been one productions has used the facial solver for three individual characters, but more are being evaluated right now, as the research lessons move into full scale productions.
Next the team are turning to looking at:
- Eye performance capture and eye wetness exploration,
- Eyelid folds and interior mouth work
- evaluation of how different aspects of production input data impact solve results,
- make certain aspects more fool-proof and
- targeting (re-targeting) stylized human characters and creature characters
All Images Copyright Activision Publishing 2017.
Note you can download DigiPro presentation at research.activision.com.
Yesterdays technology today, cool article brah