Loom.ai today publicly unveiled their new platform to create personalized 3D avatars from a single selfie.

Loom.ai is a San Francisco based startup founded by award winning visual effects veterans from DreamWorks and LucasFilm. Loom.ai was founded by CEO Mahesh Ramasubramanian and CTO Kiran Bhat, who together bring decades of hard core visual effects and animation experience with digital faces. Mahesh Ramasubramanian comes from DreamWorks Animation where he was the visual effects supervisor on such movies as Madagascar 3 and Home, and he also worked on the Academy Award-winning Shrek. Kiran Bhat previously architected ILM’s facial performance capture system and was the R&D facial lead on The Avengers, Pirates of the Caribbean, and TMNT. He recently was featured in fxguide as one of the panelists on the VR on the Lot panel at Paramount Studios chaired by our own Mike Seymour.
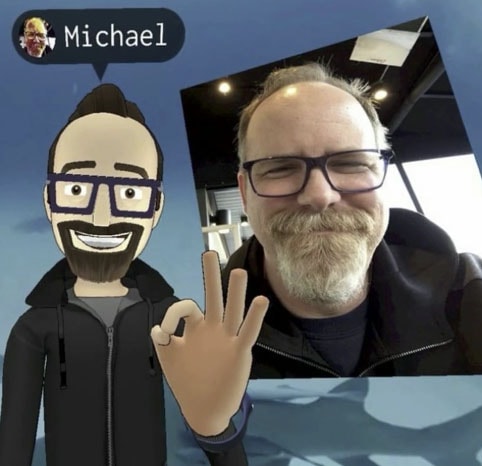
In that VR story, we discussed Facebook’s approach to avatars which is very much built on a Constructo set or Identikit idea of building a version of yourself, rather than using an image of yourself and having it automatically generated.
With the Facebook model, the expression of your avatar would be driven by the system inferring your facial expression from hand and head movements. It is not designed as a system that would be rigged and driven by markerless facial tracking.
The Loom.ai solution is quite different. It builds a face that is intended to be driven by a traditional vfx pipeline for previz or connected to some as yet unknown or undeveloped facial tracking system.
Loom.ai’s face platform provides the essential building block for providing informative social interactions and co-presence between individuals in virtual reality or augmented reality. As the system allows facial animation in a VFX style, the range of expressions their avatar can deliver is greatly in excess of the Facebook approach. It provides a way to produce the cartoon version of you from a still you might take on your phone. It can also provide a rigged avatar but it does not address how to drive your Avatar in a VR space.
 “The key to building believable digital characters is to extract the perceptually salient features from a human face in 3D: for instance, Mark Ruffalo’s version of the Hulk in The Avengers,” said Bhat. “The new suite of computational algorithms built by Loom.ai will democratize the process of building believable 3D avatars for everyone, a process that was previously expensive and exclusive to Hollywood actors benefiting from a studio infrastructure,” he adds.
“The key to building believable digital characters is to extract the perceptually salient features from a human face in 3D: for instance, Mark Ruffalo’s version of the Hulk in The Avengers,” said Bhat. “The new suite of computational algorithms built by Loom.ai will democratize the process of building believable 3D avatars for everyone, a process that was previously expensive and exclusive to Hollywood actors benefiting from a studio infrastructure,” he adds.
“The magic is in bringing the avatars to life and making an emotional connection,” added Ramasubramanian. “Using Loom.ai’s facial musculature rigs powered by robust image analysis software, our partners can create personalized 3D animated experiences with similar visual fidelity seen in feature films, all from a single image.”
The company’s fully automated software creates 3D avatars that are lifelike, animatable and stylizable. Loom.ai has a patent pending algorithm that uses deep learning and the team’s expertise in computer vision along with VFX conceptual approaches inherited from the team’s years of feature film work. As Loom.ai is just a part of the pipeline solution for a virtual interactive avatar, the company is also releasing a public API for powering applications in areas like VR, games, and virtual worlds.
The internals of the rig is custom sauce, but we expose a standard set of FACS controls after customizing it to the photograph”
The Machine learning startup is not suggesting it will deliver an ILM level rig from a single selfie. Full production rigs are incredible complex and very proprietary. Initially, the company is showing that not only can it produce a face but that face is appropriate for a range of animation. It is doing this by producing 3D avatars of various famous people based on just one sample still.
Early next year fxguide will follow up with a deep dive into the Loom.ai algorithmic approach, as for now the company is not discussing its exact AI approach for producing the faces. It has disclosed that it uses a combination of machine learning techniques style of approach to build the complex faces with much more detail than any single image provides.
https://www.youtube.com/watch?v=9w3QSYzGL9M
The company also announced a $1.35 million seed funding round from Silicon Valley investors, including Y Combinator and virtual reality luminaries. The company was a part of the Y Combinator Fellowship, Summer 2016 batch. Loom.ai raised their seed round from Danhua Capital, Y Combinator, Presence Capital, Anorak Ventures and angel investors including Zach Coelius (led first AngelList syndicate into Cruise Automation), and Joe Kraus (partner at GV).
The company also recruited Dr Jeremy Bailenson, founding director of Stanford University’s Virtual Human Interaction Lab, and Halo creator Alex Seropian, as advisors.
“Since the late 90s I have been searching for an easy way to make 3D models of people – avatars that look and behave like their human counterparts. Up until now there has been no way to do this at scale and speed. Loom.ai has provided a solution that will revolutionize how avatars are made; it’s all automatic and requires nothing more then a simple 2D image,” Stanford’s Bailenson said. “This is important because social VR is likely to be the home run application in VR. Social interaction via avatars will be much better than videoconferencing in terms of the intangible feeling of being with another person. It all starts with building avatars that look and behave like their owners.”
https://www.youtube.com/watch?v=sfvVTxBj9QA&feature=youtu.be
“Easily getting your likeness into the digital world has widespread applications,” said Greg Castle, Managing Partner at Anorak Ventures and seed investor in Oculus. “The impact of experiences is significantly increased when you can visualize yourself in a game, simulation, communication environment or advertisement. Every face in the world will be modeled for innumerable purposes.”
Investor Zach Coelius agrees. “I am incredibly excited about what Loom.ai is doing and I can see them becoming the Dolby of avatar creation and licensing their solution everywhere; the network effects are amazing. This will be the technology that captures five billion faces,” Coelius commented.
How well does it work?
We decided to test drive the system. We submitted a selfie of Mike Seymour with a neutral expression and here is the result:
https://www.youtube.com/watch?v=Dipw7pbo3Fc&feature=youtu.be
What is clear is that with only one photo, if your photo doesn’t feel like you then the avatar won’t look like you. Which begs the question: can the program work with more than one photo? The answer is theoretically it can. While the initial approach and all the examples shown in this article are all created with just one source photo, the rigged animated face could be built with a few frames or by the same logic a video short clip. Loom.ai are not discussing beyond one static image but the technology is still very new and there are major opportunities to improve and extend the software.
The current system is very fast as it uses a cloud based computational structure. The program can produce an avatar in a few moments and it is an automated process.
There appears to be an intent by Loom.ai to offer to provide your avatar with a range of animated expressions, based on pre-captured and re-targeted facial capture. In parallel with this approach, the software’s API will allow other developers to integrate the tool into a bigger pipeline. The application in pre-viz vfx work is clear but pre-viz is a very small market. Loom.ai, like other companies, seeks to provide an inexpensive and broad solution not only to output simple youtube style clips but particularly to be used in VR and in your virtual representation.
Key to the company’s approach and possible success is the animation background of the founders. They are very much approaching the problem from a movement perspective. The company is not just exploring modeling but also producing special animation rigs that integrate with the work of other startups.
Sidebar: markerless facial capture
Driving the rig is not part of Loom.ai’s current API, but clearly it will be important to users and other developers alike.
One of the first companies to offer inexpensive commercial markerless facial capture was FaceShift. The product has since been withdrawn after the company was sold. Interestingly, the Apple Inc. owned FaceShift had its birth from research work that also lead to the ILM Monster Mirror (as used by Mark Ruffalo for Hulk). Part of the original source team and key developers of that technology was USC’s Hao Li, who we featured in Part 1 of our “Face Me” series of articles.
The FaceShift system worked in three major stages (see below), but it relied on an RGBD camera (Colour + Depth camera). This is quite different from the mono RGB video that most developers are designing around today. The RGBD camera sat much like a webcam on your monitor and provided a roughly 1 meter square volume around the user to capture their face in 3D.
This was then coupled with feature tracking such as mouth, eyes and eyebrows and it drove a rigged face. The user would produce their own rig and then the generic rig of Faceshift would be linked to the various blend shape controls of your own rig. The system would read one’s eye brow going up with feature tracking. This would drive the generic rig which in turn was retargeted to your own custom rig. The system ran in realtime with terrific interactivity. Before it was purchased and removed from the market, fxguide covered the approach in the video below.
Watch a demo of Faceshift by the author, including the training phase with FACS-like poses and the real-time tracking stage with different animated characters. Note, there is no sound in this video.
We test drove the system with two RGBD cameras: an Intel depth scanner, the Intel RealSense, on a PC and the Structured scanner, PrimeSense Carmine, on the Mac. The Microsoft Kinect also worked, but not as well, primarily due to the capture volume being much larger for the Kinect and the technology somewhat older.
The FaceShift Stages
There are 3 main stages after a facial animation rig is built and set up for driving the rig.
1. Calibration (setup)
The setup needed to be done once per camera and saved. This stage allowed the user to modify the depth volume and other key aspects.
2. Training
The user sat in front of the camera and ran through a series of FACS style poses rotating one’s head left and right for a good 3D capture. There were about 29 poses, such as eyebrows up, jaw right, jaw left etc. In each case the system was building a point cloud of your face in each key pose.
This stage was done just once per actor and their custom profile can be stored.
At the end of the example poses, one used the BUILD function to make a custom profile. Once completed, the system’s generic head is morphed and modified to better match your head. If your jawline is more prominent or your forehead more rounded then the base mesh is modified to match an aggregate version of you, based on the 29 x 3D scans.
3. Tracking
Once you have completed the first two stages you were ready to be tracked in real time and for a target 3D version of you to be rendered as you watched. Clips were able to be recorded, but the system worked in real time with little lag and could retarget your performance to any 3D rigged face imported into the system.
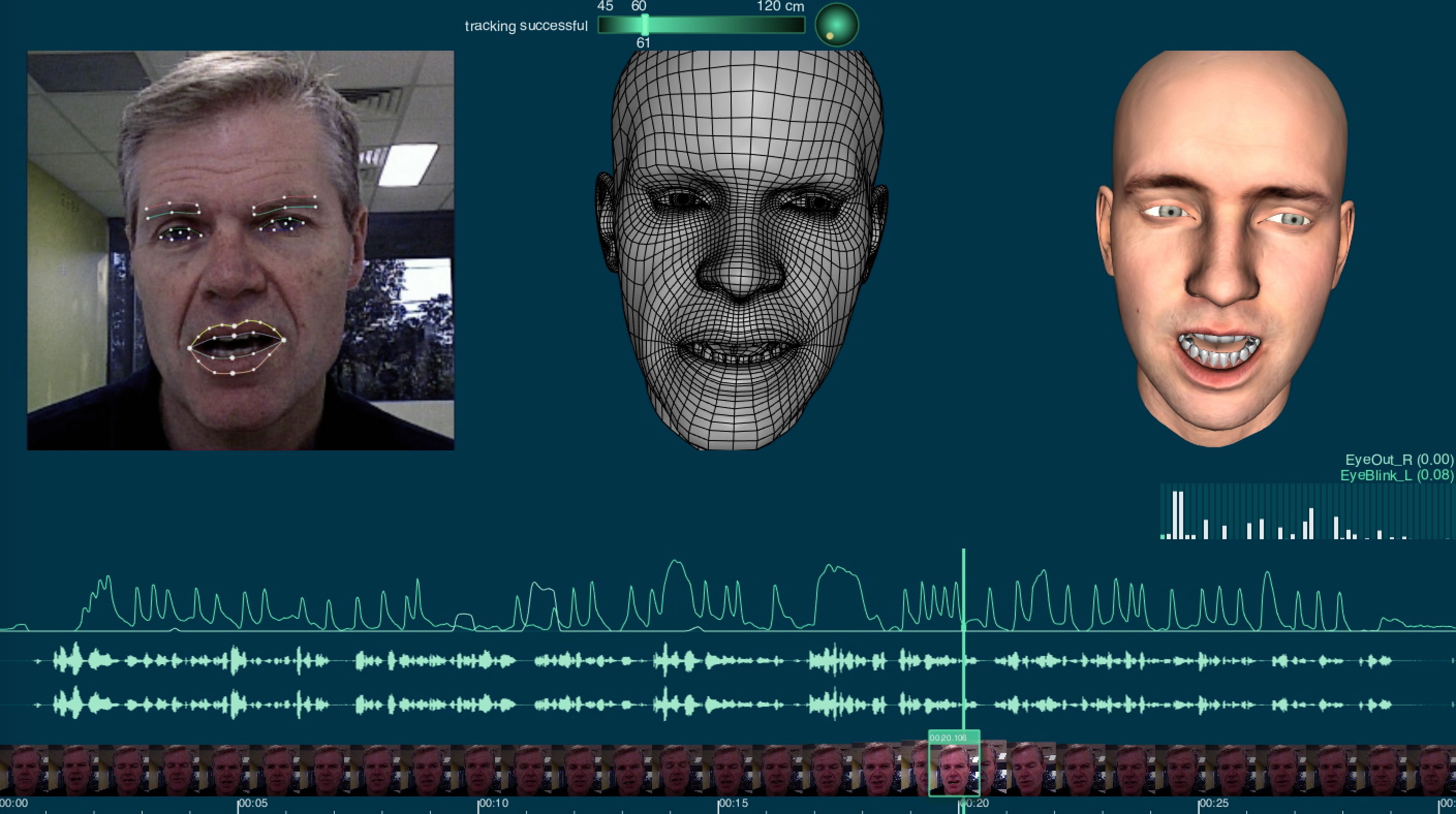
In addition the system had gaze direction that controlled where you were looking and it recorded audio for lip sync dialogue.
Faceware
Faceware came from Image Metrics and we have covered them previously in our testdrive story.
Faceware is actually a collection of both software and hardware. The company not only sells the process but also has services for hire such as rigging and facial mocap in general.

Unlike Faceshift, Facewear is alive and fully available. The Faceware approach does not use an RGBD camera but can be driven by a regular camera such as a GoPro 5. Facewear, while initially aimed at capture for later animation use, also has a real time option. The Facewear rig works with a head mounted display and so unlike the Faceshift approach it requires a capture helmet. Also unlike Faceshift, the camera and technology are RGB so much more easily able to be updated and expanded as cameras and approaches develop.
The normal Faceware pipeline is two stages:
- Analyzer
- Retargeter
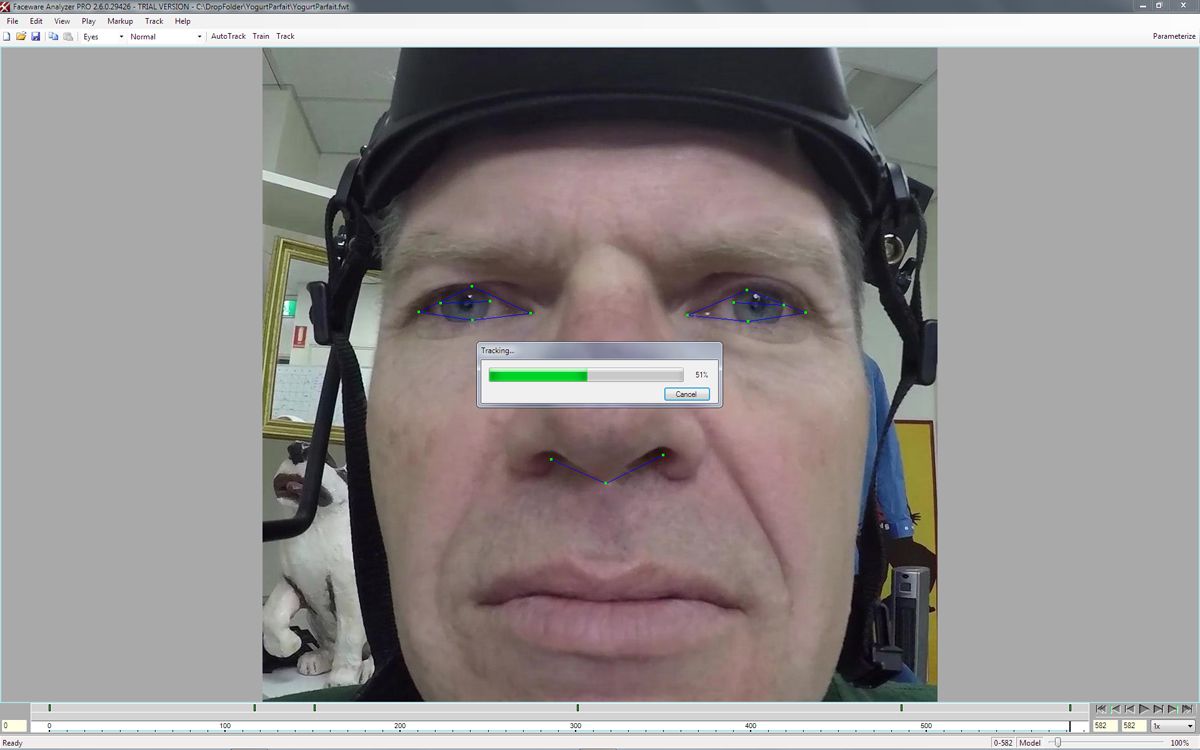
Analyzer
The Analyzer is the tracking software. It tracks the face and exports the data to a format the Retargeter can use to drive a pre-rigged face in a standard software program. The Analyzer tracks three features into three groups of data: the eyebrows, the eyes (pupil movement and eyelid movement) and the mouth (lip movement). There are 51 tracking points, which are called landmarks. You can manually place them on the face at key poses and ‘train’ the software to produce a better track.
Once everything is tracked, the data needs to be parametrized so the track can be used in retargeting.
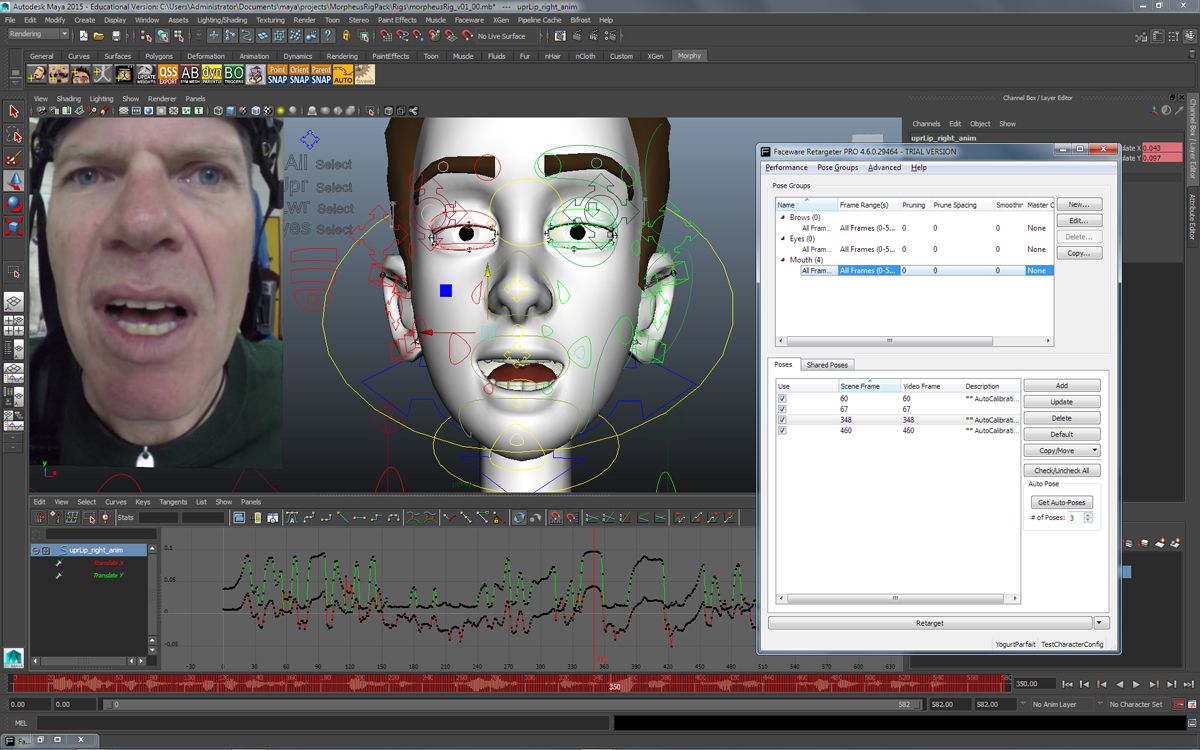
Retargeter
This runs as a plugin in your 3D program. Before you can retarget the tracking data to a 3D face, the Retargeter needs to know how the 3D face is controlled by the rigging.
The Retargeter needs to ‘learn’ how the face is posed by these controls. This can be achieved by manually posing the face to match the 50 or so pre-determined poses in the expression set. You only need to do that once for each face model and the expression set can be re-used for the same character on different shots.
Faceware Live
The key benefit of Faceware Live is the ability to produce facial animation in realtime. Using the company’s patented computer-vision technology, Faceware Live automatically tracks video of a performer’s face and streams the realtime animation data into the display environments such as Autodesk MotionBuilder.
A unique feature in Faceware Live is the ability to calibrate any performer in one second. There is no need for a lengthy range of motion or complex character setup process. Faceware Live is built on the same powerful technology as the original animation pipeline that has been developed up over 15 years of R&D. The technology is robust, and most importantly, stable.
Given Faceware’s position in cost-effective solutions it is perhaps the leading contender to broaden out to more consumer level options, although this is not part of any publically stated roadmap.
You can find out more about Faceware at their website.
Beyond this level, there are studio level rigs, which are much more expensive and not relevant to the wider Avatar market. Systems such as the high end Vicon Cara 3D facial motion capture headset, which uses a helmet built with four cameras (as used in Fantastical Beasts and Where to Find Them).
There is one key aspect of avatars that should be noted. While the problem of making a digital version of your face is complex and especially from one still image, it is not the biggest problem in VR. Any markerless facial capture system is defeated by wearing a VR head rig, as it simply covers most of your face. Hao Li’s research team and others have been looking at a range of problems to address this, from stress sensors inside the VR headset to AI to guess the rest of your face based on just the mouth and small amount of your face not obscured. There are no commercially available solutions to this problem right now, hence the Facebook approach at the top of the story that guesses your expression from your hand movements.
Without VR, there is still a large hill to be climbed to get clean, yet relatively unfiltered facial movement data using whatever rig is used. Even for the most successful animation systems, such as Zurich-based Disney Research’s Medusa system, maintaining the fidelity of the performance is critical.
The most impressive high end real time system shown publicly is the EPIC Games/Cubic Motion and 3Lateral system. This live system won the 2016 Siggraph Live and we have covered it extensively. But these high end and powerful systems are aimed squarely at serious production and not any type of selfie animation.
Humans like seeing faces, and with such a vast social media community keen to explore avatars and selfies it seems likely that this area of facial capture and avatar motion performance will continue to attract both research dollars and some of the brightest minds working in the field today such as Mahesh Ramasubramanian and Kiran Bhat.
One final example from Loom.ai (not driven live).
https://www.youtube.com/watch?v=IuJxbxOK0Tc&feature=youtu.be