One of the many surprises in Avengers: Endgame was ‘Smart Hulk’. This new version of the Hulk was animated by ILM and Framestore. Smart Hulk had not appeared in any of the trailers or marketing material so his casual introduction caught many fans by surprise. ILM has a long history with the Hulk and during the production of Endgame they rebuilt their face pipeline to provide a remarkable digital character, a hybrid of Bruce Banner and the Hulk, that technically allows actor Mark Ruffalo to deliver a nuanced performance, that he had never before been able to deliver.
ILM : Smart Hulk
ILM has done many versions of the Hulk, most prominently including Hulk in The Avengers (2012), and again in Thor: Ragnarok (2017) and now once again in Avengers: Endgame (2019). What few expected is that ILM would develop a remarkable new approach to Hulk, while in the same film having to re-do shots of the 2012 Hulk, thanks to the film’s time travelling plot. To make their work even more interesting, the present-day Hulk is now embodied in a new ‘Smart Hulk’, who is articulate and even comes complete with glasses and a cardigan. Kevin Martel was the animation Supervisor for ILM on Avengers: Endgame, and he also worked on the Avengers 2012 Hulk. “At that time (in 2012) ILM was creating a new look for Hulk in the Marvel Cinematic Universe. So it’s interesting to end up in this position now where again, we were creating a new Hulk for the Marvel Universe, but one that was very, very different from anything that we had made before,” he commented.
Martel recounted how the new Hulk was also a vehicle for ILM’s development of a new face pipeline. The previous face pipeline that had been developed over the films Warcraft, TMNT and Ready Player One involved filming an actor’s face covered in dots. These dots were filmed with stereo cameras on a head mounted rig, solved and then transferred onto ILM’s characters. While the pipeline had many upgrades and innovations such as ILM’s Snap Solve, the team always struggled to make sure they had fidelity to the performance and that they had captured all of the subtle fine lines and wrinkles that make up a face. As the team started their work on Endgame’s Hulk, they decided that while the dots on an actor’s face were useful and contained a lot of good information, “we wanted to get in-between the dots!” explained Martel. “We really wanted to see everything and so for this show, while we started using tools like Snap Solver, we explored ways to get extra information.”
For some time ILM and other effects houses have approached characters like Hulk by starting with a Light Stage scan for the appearance and a Medusa scan to build the blend shapes. Medusa offers outstanding 4D data, while the Light Stage offers stunning appearance data, but only on static poses (Dr Paul Debevec had planned at one stage to extend their research to 4D datasets, and perhaps this still may happen). Regardless, in all cases the actual performance is filmed on set and this is what drives the final performance.
The reference scans of the actor are done while they are sitting in a special rig, and they are used to make the puppet, that is later controlled by the actor and then polished by the animators. The problems in the old system were that it always relied on artists polishing and refining the animation, but the tools the artists had to work with were overly complex, and the global blend shapes that were used often had a strong tendency to over constrain the problem.

Xweave
The first approach ILM tried was to take around 60 meshes generated from Medusa sessions and use a new piece of software called Xweave (as in Expression weaver). Martel explains that at this early stage, “we would use Xweave to look back. It would track the facial dots, as we were doing with the Snap Solve, but then it would reference back patches of information to the original Medusa capture sessions.” This started to get more detail in the animation but it was not significant enough.
Anyma
Xweave was eventually replaced by a tool so advanced, ILM no longer even needs dots on the face of an actor. ILM was aided in their work by the Sci-tech Oscar winning team from DisneyResearch|Studios in Zurich, headed by Prof. Markus Gross. His team developed Medusa and recently Disney had tasked the entire unit to be more aligned with the film production unit generally. The Zurich team had been working on a new approach for some time and have shown tests to ILM from as early as 2015 when DisneyResearch|Studios first started developing Anyma.
The new system was called Anyma and initially it involved “almost an ADR booth kind of set up with three cameras. It was initially a headless cam set up, that was also a markerless facial capture set up,” explained Ebrahim (Abs) Jahromi, Creature Supervisor on Endgame. The system was notionally designed to allow an actor to deliver lines after coming off set, or if additional dialogue was later needed. The actor could move insid the booth setup, in a space about 1 meter cubed. They did not need to sit down, in fact they usually stood and move. The three cameras rig allows movement without the restrictions of a Medusa rig, and it did not require any facial dots. This new system seemed extremely promising and so a team inside ILM decided to see if they could take this technology and apply it to footage from an HMC. Unlike the original Anyma, the new approach would be using footage from a camera fixed relative to the actor’s head (via the HMC). The Anyma system was design to work with as little as one camera, but the question was whether Anyma would work with the wide angle HMC head mounted cameras.
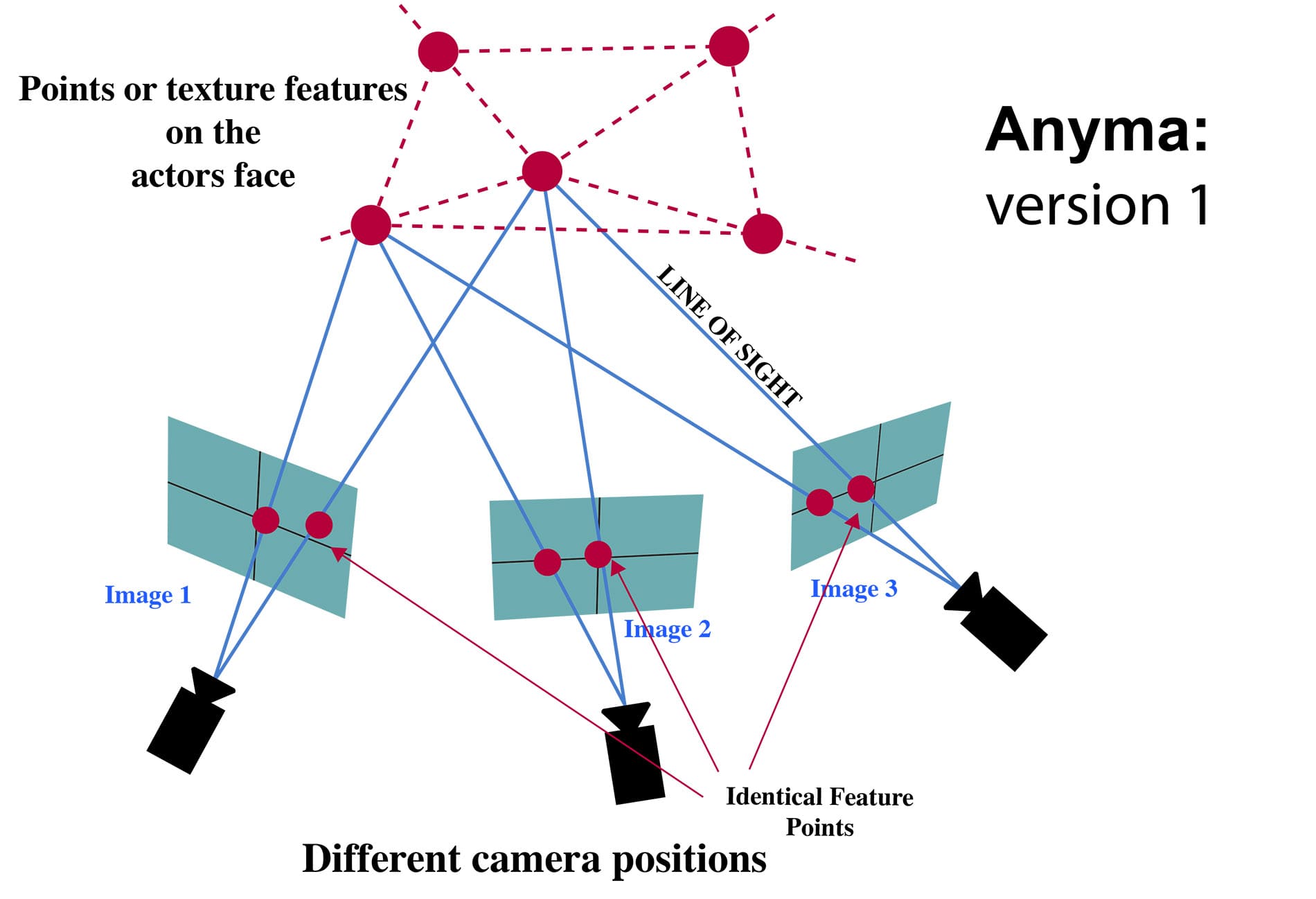
In 2016, Chenglei Wu, Derek Bradley, Thabo Beeler and Markus Gross published a pivotal and landmark SIGGRAPH paper entitled ‘An Anatomically-Constrained Local Deformation Model for Monocular Face Capture’. While the title and even the test images would not suggest it, this is the technology was from the core of Anyma, and that ILM would use on the HMC footage of Mark Ruffalo. Remarkably, the paper showed the team had Anyma working with just one camera, if required. “During the course of making Endgame, we started seeing more of these tests from the Disney researcher’s Anyma system and it was quite impressive,” explained Martel. “So we wanted to see if we could somehow use that for our Hulk.” The decision was helped by Dr. Thabo Beeler relocating to Northern California for a year, allow him to aid in the technology transfer and production pipeline implementation.
What the ‘Anatomically-Constrained Local Deformation Model’ paper showed was that a local deformation model composed of many small subspaces spatially distributed over the face could produce remarkable animation, even from a single camera. Mark Ruffalo wore two stereo cameras mounted vertically on his HMC unit, which allowed for even greater results. As their paper states, the trick is not solving for the whole face with a major single FACS pose, but rather to use a new anatomically-constrained local face model and fitting approach for tracking 3D faces from 2D footage. In contrast to traditional ‘global’ face models, often built from a large set of blendshapes, the Zurich team used a local deformation model composed of many small subspaces distributed all over the face.
This gives Anyma a much more flexible and expressive solution. Another key moment of insight was to think about how faces are made and use subspace skin thickness constraints, which constrain the face to only valid expressions. The system is robust and works with or without tracking dots.
The adoption of Anyma has one other key advantage – it allows for what the skull is doing. Unlike normal blendshape approaches, Anyma’s local deformation model explicitly decouples the rigid and non-rigid local motion, allowing for extremely accurate face shapes. This is important for two reasons. First, if Mark’s HMC head rig moved a small amount the results of the animation are unaffected. Secondly, it opens ILM up to the next level of the DisneyResearch|Studios work, using a new jaw model. The new jaw work was not used on Hulk, but Martel is very keen to explore it. This new jaw research from DisneyResearch|Studios is only now being published at SIGGRAPH.
Jaw Background
In simple rigs, a joint based system can be advantageous for jaw bones, as blend shapes can be spatially linear. Movement, especially around the lips, can look wrong due to these linear transitions with blend shapes. This can be adjusted with user controlled corrective blend shapes. Additionally, the mouth moves more in an arc than a straight line, so simple jaw movement is arguably handled better by a Joint rig models. But jaw rigs are difficult to master the look of muscle sliding under the skin. Having decided upon a blend shape approach the problem remains of getting the full range of accurate motion from the mouth. Highly accurate visemes are represented through deforming geometry using the blend shape methods but they often appear to suffer from combinatorial explosion in representing the complex manifold of facial expressions.
Jaw Research

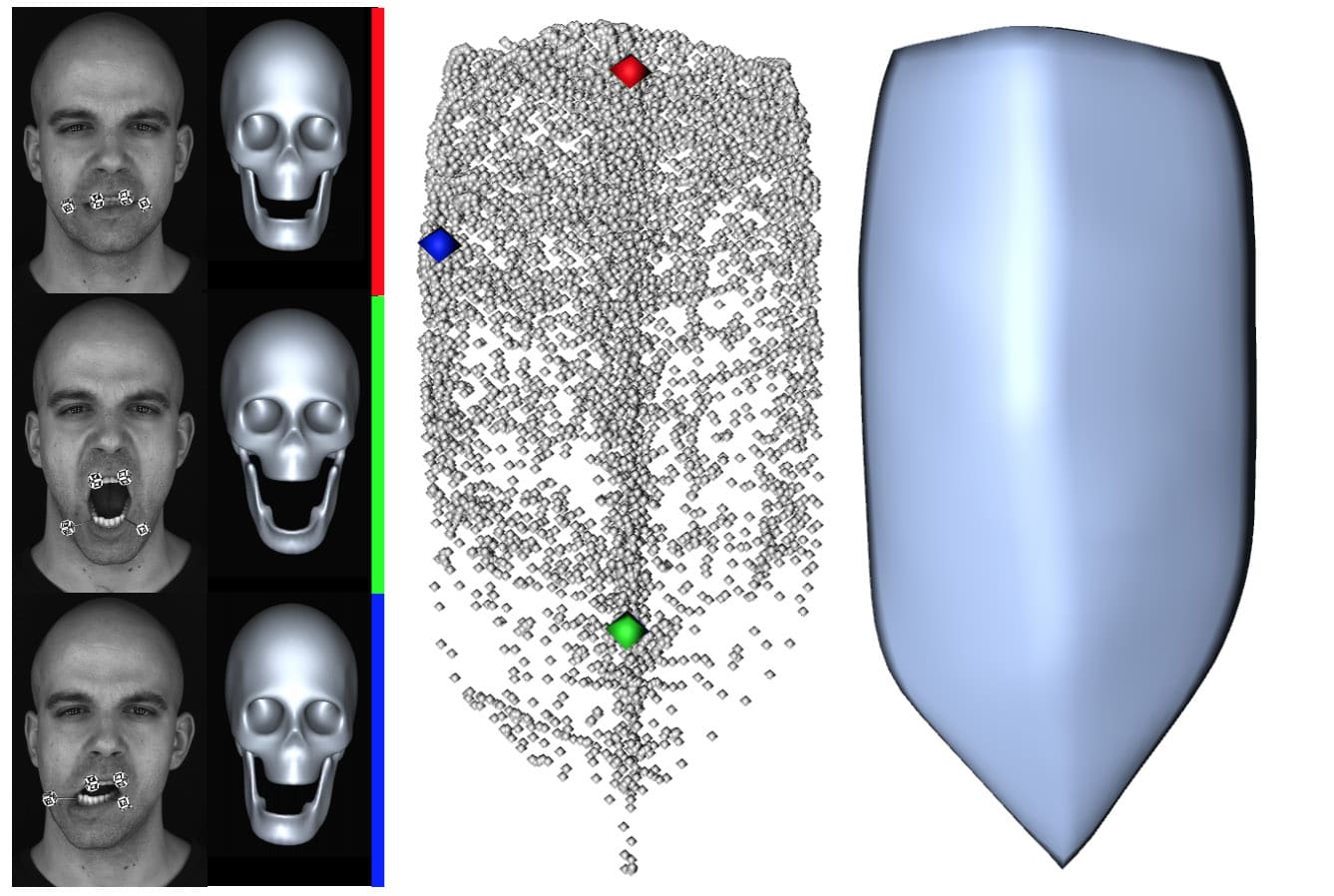
The jaw seen above in the DisneyResearch|Studios’ image is linked to the skull at pivot point ‘o’. The jaw moves relative to the skull and has two rotational and one translational degree of freedom. ILM had previously had a 6 degrees of freedom jaw rig in house. “Our jaw traditionally does have six degrees of freedom. Animators however prefer less than that when they animate the jaw typically,” explained Jahromi. “But on Hulk we did something interesting where we looked at what the Disney Zurich guys were doing, but that wasn’t available, and we learnt from their early work. Part of what we did in the ILM Solver was to introduce this concept of a Posselt’s shield shape.”
Posselt’s Envelope or Shield
DisneyResearch|Studios is made up of a team of dedicated PhD researchers who are not afraid to get their hands dirty. From Medusa rigs to eye scanners, they have a real flare for the practical as much as the theoretical. In this case, the team wanted to improve facial animation around the mouth. They designed 3D printed cubes with fiducial markers on them, which were then mounted on steel pins and glued to the subjects teeth using dental glue. The team did two marker cubes on the lower teeth and two on the upper. Eight cameras then capture the jaw movement from four distinct viewpoints. The first time they did this, the team really had no idea how well it would work, or if it would work too well, since after all they were gluing steel rods onto each other’s teeth! No one actually knew how hard it would be to remove the pins, which led to a lot of checking of instructions and a rather tense first lab trial in Zurich!

The actual paper that this research was published in is called : ‘An Empirical Rig for Jaw Animation’ by Gaspard Zoss, Derek Bradley, Pascal Berard and Thabo Beeler, all from DisneyResearch|Studios. From the early efforts of the Disney Research team, ILM was able to gain a clearer understanding of how Mark Ruffalo’s jaw moved when retargeted to Hulk

The anatomy of Mark’s jaw, or indeed any actor’s, is shown above. The mandible, or lower jaw bone, is attached to the skull via the temporomandibular joint (TMJ) and held in place by ligaments and muscles (image a). For small openings, the TMJ acts mostly rotational (image b), but when the jaw is opened further, the posterior condyle, or jaw knuckle, leaves its socket and slides over the temporal bone of the skull (image c), causing the rotational pivot to translate along a curve. A cartilage disc (seen in blue) serves as a cushion and prevents abrasion of the bone (which would otherwise be insanely painful).
Since the mandible jaw bone slides over the surface of the skull in a complex way while rotating, jaw articulation occurs with a complex six degrees of freedom. Just this alone would be complicated enough for animators to deal with, but in the medical field, a host of research studies have analyzed the motion of the jaw, in particular for dentistry. Early studies by a Dr Posselt indicated that the range of motion of the jaw can be mapped by tracing a point at the jaw. Hence, the DisneyResearch|Studios team’s efforts to see clearly the jaw’s position and their glueing of steel rods and tracking markers. If you map a marker over all the dialogue and expressions of a person, you get the shape of a shield. This is known as Posselt’s Envelope of Motion or the Posselt shield.
At ILM they incorporated this into their retargeting for the face of Hulk. “When we do our re-targeting, part of our system analyzes how the jaw is moving and keep Hulk’s jaw within the constraints of that Posselt Shield,” explains Jahromi. “We do this so Hulk’s jaw is more anatomically correct. We also incorporate a skeletal structure underneath it to see what the anatomy is doing so we can better visualise that it is correct.” At the end of the day, the system provides starting animation keyframes on the jaw to the ILM Animators that are within the limit of that shield shape, “and that should give them a better result,” adds Jahromi. “If you want an anatomically correct performance, even on the creature, then the parts have to be anatomically correct – from the retargeting, the solve, the eye solve, to even the blinks – it works best when the animators are given anatomically correct animation to work with.”


Anyma for use with On Set footage
ILM helped adapt Anyma from the initial research using a three camera rig to something that could be used for the on-set HMC footage. “Originally, the actor would stand in a volume and static cameras would be positioned around them,” commented Martel. “But we had already filmed these scenes on set with Mark. We had all this footage, information and data that had been acquired from the dots on Mark’s face and our cameras. At this point our film was shot. So we wanted to see if we could adapt to the system to what we had shot.” Getting Mark Rufflo’s full on-set performance was the ambition.
Skill of the animators
Even with the principle photography completed, ILM set out to see if they could rebuild their face pipeline to be centred on the on-set HMC footage for the performance, with all of Mark’s choices while on set. Jahromi was previously the co-creature supervisor on Avengers: Infinity War, “but I decided to shift gears a little to focus more on Hulk’s facial performance, primarily dealing with the final output involving the retargeting,” he explains.
Jahromi was responsible for the retargeting system used in concert with Anyma, but it was not just a matter of using better data from Anyma, as Jahromi wanted to improve what the animators were given. In particular, he wanted to make the system deliver to the animators a more accurate starting point, but also a more easily controllable set of animation controls. This is a complex task, to both increase the fidelity and reduce the complexity for animators. But as Martel explains, “for the animators at ILM, there is all this technology and yet by the time it gets to the animators, our hope is that things are intuitive and easy use and all of that extra tech is invisible except for this wonderful aesthetic that it brings.”

Blink retargeting
Central to helping the animators was the ILM Blink retargeting system.
One function of Blink is to present animation curves to the animator. In prior pipelines, the animator might have been presented with 100 animation curves. Jahromi and his team got this down to about 25. The immediate effect is a more manageable set of controls for the animator, but the benefits are even more substantial. When a solver produces a solve, it is matching the face data to the ILM FEZ library set of FACS shapes. On any given frame, this looks correct with say 25% of this shape, 33% of this etc… The problem comes in the next frame. When the solver then solves again, it may once again produce a seemingly accurate match between the face at that instant and the shape library, but this might be a radically difference approach to the solution on the previous frame. This leads to spikes in the animation curves as the computer rapidly switches approaches. The results may seem great, but it is a nightmare for an animator to adjust. “Typically, when a system transfers a cache to a set of blend shake weights, you get crazy curves. For example, the system may think at one frame it’s seeing a smile and it will dial the blend shapes way up on a smile and the next frame the smile might change and it now thinks it is better represented by a frown. It then immediately dials in a frown shape, all at once. You get really high peaks of curves, as it just changes frame to frame, which is impossible to edit and animate.”
Deep Learning.
Blink was one of the key places that new deep learning approaches was applied to the ILM pipeline. Part of the new shape decomposition was to train the system. The system trains for each shot and it takes roughly 30 minutes. It does this using the FEZ library, the blend shape library data that is derived from the Medusa scans. The training sorts out permutations of the shapes and figures out combinations of them that will be used to present to the animator. It provides less curves but importantly, it provides curves that flow and that do not jump rapidly around from shape to shape on a per frame basis.
“The shape decomposition, in the previous FEZ version at ILM, has often decomposed to upwards of hundred shapes, which is crazy because animators can’t manipulate a hundred animation curves. It’s just very difficult to work with”, explains Jahromi. By limiting the amount of shapes, it makes the task of the animator easier. “The great thing about that approach is that it is easily editable by the animation team. The curves are clean, they’re animator friendly curves. They are easily changeable and the animator is not just presented with a thousand curves all over the place.”
“A key part of the new Blink system, was to decompose to a ‘recipe of shapes’ that were hand picked by Kevin (Martel) as the animation supervisor,” Jahromi adds. “He said, ‘okay, these are shapes that we want to decompose to. This is a manageable amount of compound shapes‘. And the system tried its best to match to those shapes.”
Blink decomposes to compound shapes and tweaker shapes, (which can be thought of as correctives). The system has a unique way of tracking and not loosing subtle detail.
After Anyma, “we still break down the face into blend shapes, but they are seemingly invisible. They are there, but under the surface,” explains Martel. Any difference between the blend shapes and what Anyma has provided is kept as a ‘delta’. “We have our blend shapes and we have a ‘difference’. That is how we’re able to continue to manipulate the performance,” he adds.
Previously the Medusa data was used as a point of reference for ILMs modellers to model the blend shape library. But on Endgame, Jahromi wanted to be more mathematically accurate. Having done training and using the new DisneyResearch|Studios tech, the difference, or delta, between Anyma and the blendshapes was much smaller than ILM’s previous pipelines. These deltas are called “residuals” inside ILM. The residuals are valuable as they are the difference between the blend shapes and the data from the new accurate pipeline, so Jahromi worked hard to maintain them and then apply them to make Hulk’s performance even more accurate. “Those residuals are what we love to keep because those residuals are essentially the granular, very fine, minute details, things like skin twitching, that you see in the facial capture but can be lost when resolved to blendshapes,” he explains. “We have then the shapes plus the residuals equals the raw re-target on the face.” ILM makes a fully animated digi-double of Mark Ruffalo before retargeting onto Hulk. The ‘raw re-target’ Jahromi refers to is based on digital Mark Ruffalo retargeted to Hulk. It is essentially a set of points in 3 space – one can think of it as a cache. But the extra step of shape decomposition that follows has other animator advantages.
Inversion Process
The shape decomposition is what ILM refers to as an ‘inversion process’. This process also helps the animators. In the past if the animators needed to enhance the performance, they were essentially animating a ‘face at rest’ with the face capture data overlaid on top, “which doesn’t necessarily give you correct results,” explains Jahromi. For instance, imagine the animator has to work on a re-targeted performance of the Hulk doing a kiss or pucker. Typically, this involves the lips moving forward and pushing out to form a kiss. If the the target is a raw version of that data on Hulk and the director wants to push that pucker for comic effect, then the animator would need to jump in and enhance that pucker by dialling up the pucker blend shape.
That blend shapes comes from rest position because the rest of the shape library is made prior to the face capture of Mark Ruffalo on set. The facial motion capture is just the cache or set of points effectively on top of the rig. The problem is, “you’re not in that space. You’re not in that vertex space. You are essentially dialling in pucker from the rest position and you’re making the vertices move in a particular displacement and a particular vector that isn’t necessarily correct,” says Jahromi.
However if ILM’s shape library is updated with the inversion process of shape decomposition, the library is already providing something very much like this pucker and the rest is coming from the tiny deltas or residuals. The animator is adjusting a shape that is already in the pucker shape and just enhancing it. “Its delta or residuals are really small and so the amount that the vertices are moving will mean the final face is more accurate. It just gives you a much, much better result and it gives you, an animator, what we refer to as a ‘non destructive way’ of being able to enhance the performance without fighting it,” Jahromi concludes.


Old Hulk
In addition to new Hulk, the ILM team had to animate the old Hulk in the time travel sequences. While on the surface the old Hulk looks very much like the 2012 Hulk, under the skin, the old Hulk control and animation was completely redone. While Hulk is scarred and covered in dust from the Battle of New York, “under the skin he was pretty shiny and new,” joked Martel.

Turnaround in a day
The ILM team completed around 150 shots. The last sequence they worked on was for the scene where the Hulk and a few of the other Avengers are standing around in the Avengers Bunker, discussing the nature of time travel. It is an amusing dialogue heavy scene known as the BTT sequence.
The BTT sequence involved about 15 to 20 Hulk shots. Jahromi is proud to point out that by this stage in the production, the process was working so well that “the turnaround time from shot turnover, to Anyma, to Blink to the animators was just a day.”
The sequence arrived at ILM at the last minute, so it was important that only high quality material was presented to the animators, and as fast as possible. This meant the highest quality fidelity of data, with the lowest amount of human intervention or fixing/tweaking as possible. “And to provide that data on a platform that can be easily manipulated,” adds Jahromi.
Working with DisneyResearch|Studios, ILM’s artists and technicians, the ILM team rebuilt their pipeline twice during Endgame. “We made it happen and that’s what ended up using in our pipeline, it was using Anyma solves directly from two head mounted cameras” explains Kevin Martel.


Framestore Hulk.
As aforementioned, Framestore also worked on Smart Hulk shots. The company choose to embrace Machine Learning in their efforts to faithfully transfer Mark Ruffalo’s acting choices onto Hulk. It should be noted that rigging, especially facial rigs, are never transferred between facilities. Technically there is no interchange format for full rigs. This is not a commercial decision but a practical one. As such, Framestore shared the same on-set data but had to build their own separate pipeline solution.

At the outset, a small team at Framestore were tasked with developing their Machine Learning approach and taking source footage of Mark Ruffalo and solving it to match it in Hulk’s animation. “It was a way of convincing the client that we had the software that could do this quickly,” explains Robert Allman, CG Supervisor at Framestore.
This resulted in a first pass of animation that could be used by the filmmakers to decide on the edit. Framestore then begun the process of refining and adding face-shapes to use in their rig. Keyframe animation was then deployed for over 60 of their Smart Hulk shots, with head cam footage from the shoot used only for reference. Mark’s performance was key for the animators on the film. “It was absolutely about channeling Bruce Banner,” explains Max Solomon, Animation Supervisor. “His face is very expressive. Every nuance, every little twitch and eye dart, slight curl of the lip and muscle tension needed to be translated.”