A Personal Note:
The FMX conference once again delivered with impressive talks and a brilliant array of speakers. Both John Montgomery and myself attended (John was first amongst us to discover FMX a few years ago). We both love the conference and the people. As we do at most conferences which have this much great content – John and I ‘divided to conquer” – so this is my personal view of FMX tech gems.

Most industry coverage of FMX will no doubt focus on the advance preview of Weta Digital, ILM and Rodeo FX brilliant Valerian and the City of a Thousand Planets or the automotive track which started with a detailed look at BlackBird being used in the Human Race. Certainly, hearing ILM’s John Knoll discussing the onset technology used for Rogue One as part of the Virtual Production talks was a highlight, but we have either covered these projects before or will in greater detail when they come out. Instead, I wanted to highlight some of the cool tech or hidden gems of this great conference. A few things really caught my eye:
- Clarisse version 3.5 – especially it’s integrated Cryptomatte implementation.
- Chaos Groups combined new GPU and CPU renderer
- Pixar’s efficient rendering of volumetric Motion Blur.
But dont worry, we will also be publishing great interviews we have done at the show with compositors from DNeg, Framestore’s Animator Supervisor from Guardians Vol 2. and much more over the next week.
One final point – we have added a gallery at the bottom of the story with some of the selfies and quick pics we took during the week. We love going to conferences and meeting up with artists from fxphd and readers of fxguide. It is brilliant to hear stories of people who started with fxphd.com and are now starting their third Chris Nolan film or working in their dream job in their home country. Thanks so much – your enthusiasm for what we do is the oxygen that fxguide and fxphd runs on. With literally millions of pages, podcasts and videos downloaded each year, we look forward to seeing even more of you at GTC, SIGGRAPH and the other upcoming conferences.

I want to give a special thanks to those who attended the Digital Humans Track at FMX and the great speakers who gave such brilliant talks : Hao Li of USC – ICT for his Deep learning in facial animation, Kiran Bhat from Loom.ai (ex ILM) who showed amazing avatar reconstruction from a single image and Luca Fascione from Weta Digital, who,- like Kiran at ILM, won a Sci-tech Oscar award this year for the development of face pipelines at Weta Digital. I learnt so much and it was the highlight of the conference for me.
-Mike Seymour (fxguide)
Clarisse
Psyop is a key visual effects company in NYC and LA and they developed a great tools for helping composite CGI. Released to the public last year, Cryptomatte is now in Clarisse. There is a lot of new things in Clarisse 3.5, and we will be posting a story after FMX on Clarisse’s use in a project at DNeg, – but the Cryptomatte works so well we wanted to single it out for comment.
Jonah Friedman and Andy Jones brought their high-functioning tool Cryptomatte to SIGGRAPH 2015. Although this ID matte creation tool had been a core component in the Psyop workplace it was only released as a ‘product’ in July 2016.
When it was released last year, Psyop’s Jonah Friedman commented that “Cryptomatte is a tool created at Psyop by Andy Jones and myself. It creates ID mattes automatically using organizational information already available at render time. This organizational information is usually names, object namespaces, and material names. It also supports motion blur, transparency, and depth of field, making it a pretty complete solution to the problem of mattes.”
Below is an example render from Arnold showing the object ‘id-ed’ when seen with the Nuke plugin.


Anders Langlands, a VFX sequence supervisor currently at Weta Digital, is the author of AlShaders. After SIGGRAPH, Andy and Friedman invited people from the 3D animation industry as well as developers of renderers to join a “Cryptomatte Committee” – a body with the goal of creating an open standard from Cryptomatte. Anders Langlands was the first to implement the 3D side of Cryptomatte in an open set of shaders. As Arnold is the default renderer at Psyop, and they used ALshaders, the plugin was first seen in Arnold at Psyop.
It works by rendering an AOV that is read by a plugin in Nuke. The tools is lightweight as it acts much like a Deep Data ID system but without the actual deep data. The Nuke ‘decoder’ is given away free, but the Encoder was initially available in Arnold. Here at FMX it is being shown in Clarisse 3.5.
Unlike the Arnold version, Clarisse have integrated Cryptomatte into the software fully, which means that you can use it no matter what Shaders you use. In Arnold, if you choose to not use the ALShaders then you can’t access it. Clarisse is the first product to fully integrate it and it seems to work brilliantly.
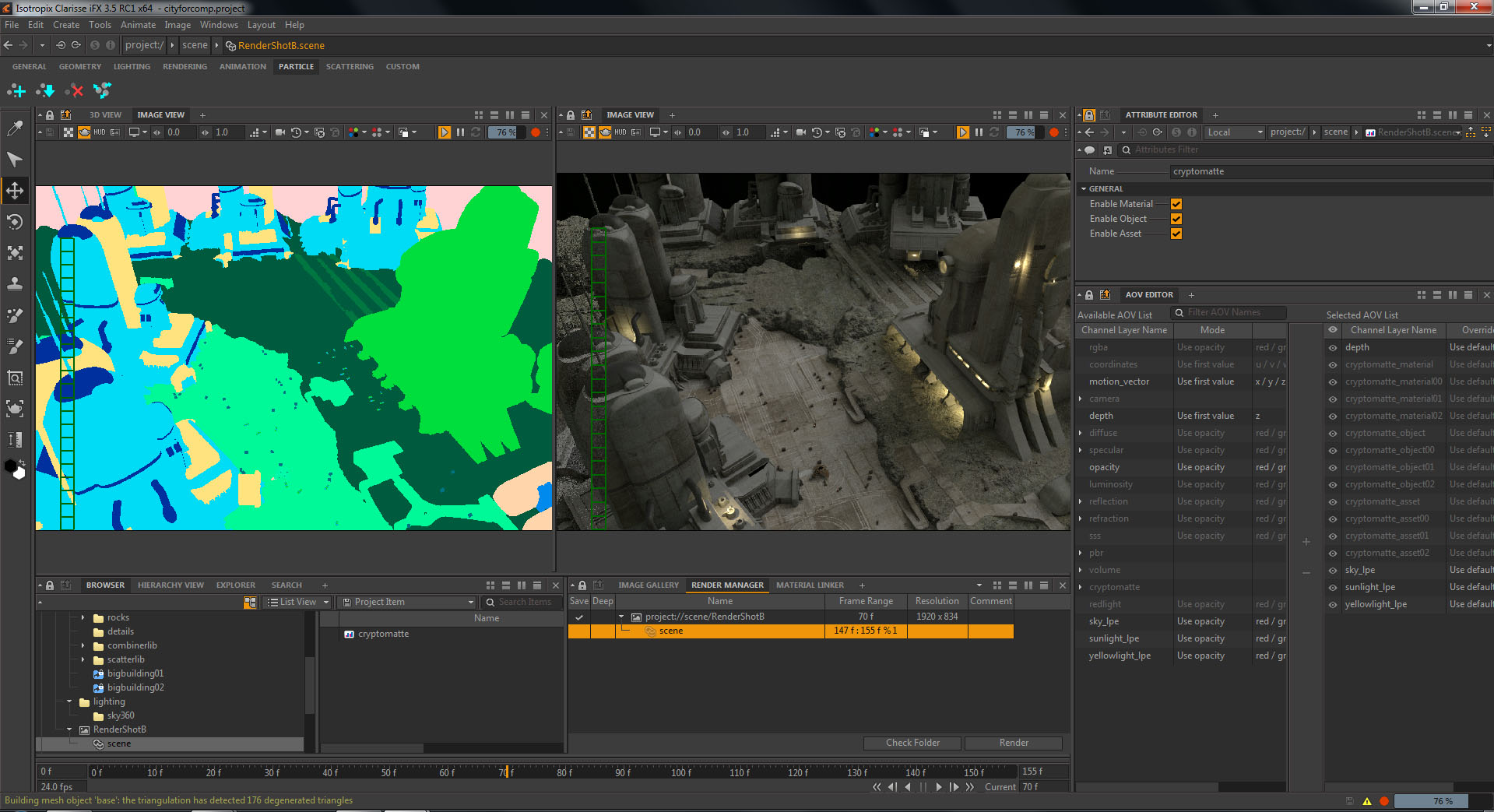
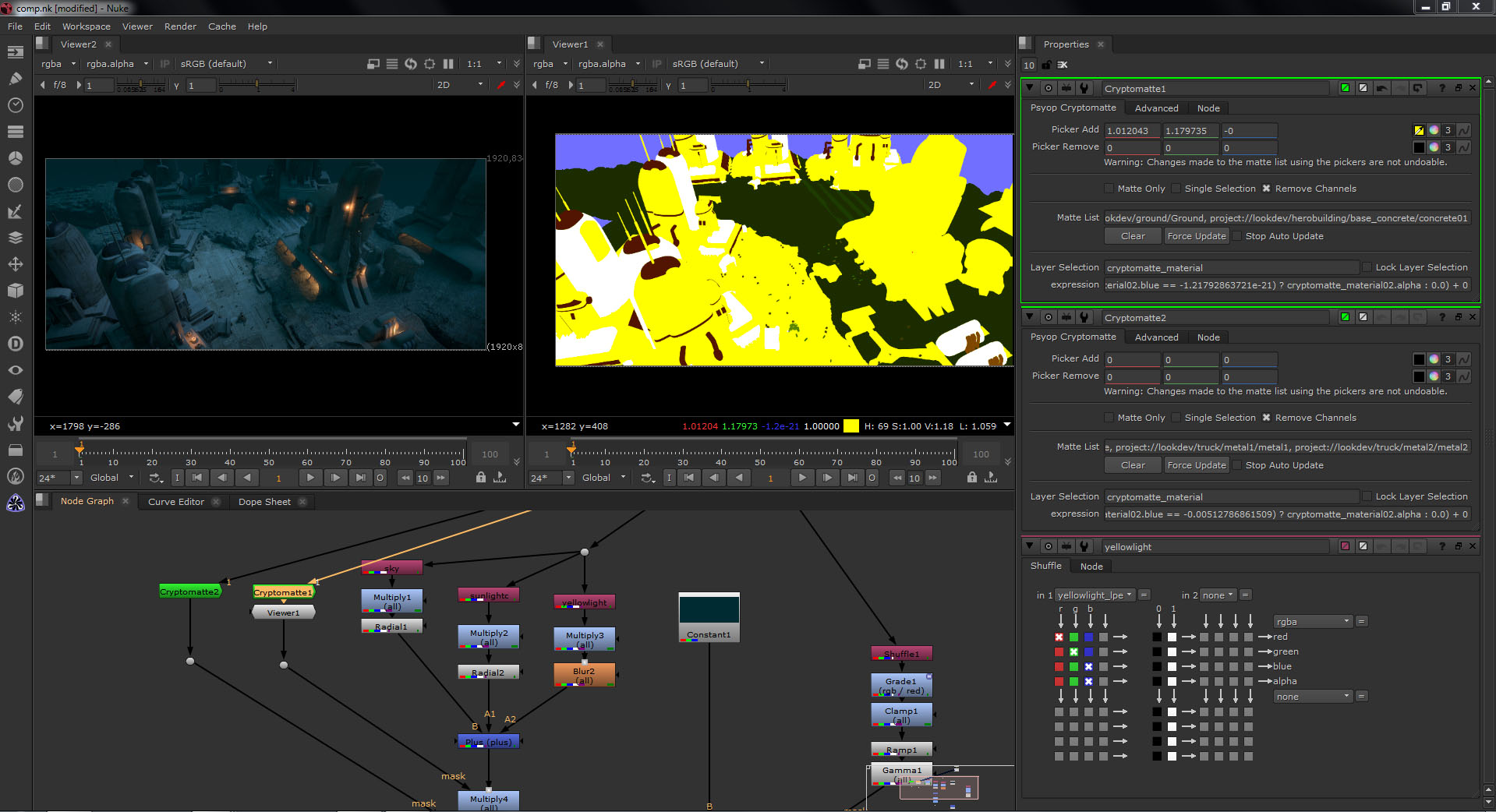
At first glance it may seem like Cryptomatte is a Deep Comp solution, but it is much faster and lightweight than a Deep solution, as it identifies matte and yet does not provide the depth information. When using the tool, a compositor can click on an object or set of objects and immediately gain a matte, even when the object is subject to depth of field or other effects.
For many years compositors have been requesting special hold out passes and mattes, or simply rotoing the 3D in the final render to adjust aspects of a comp. This approach allows the compositor to directly and immediately gain the matte without needing to go back to 3D. The AOV does not contain the depth information but rather for any pixel if say three objects contribute to that pixel then the id’s of those three objects is maintained and their contribution. This makes the file light and very fast to access compared to doing this via a full deep render. Several companies have had similar solutions internally, but the Cryptomatte solution is starting to gain momentum especially with the strong adoption by Clarisse. The tool just works so well, and solves such a fundamental need in CGI compositing that hopefully the industry will embrace it widely.
Given this integrated solution we sort the opinions of the other key render developers. We spoke to Chaos Group, (during the CG Garage podcast – see below), Vlado’s answer can be heard in Chris’ great podcast but in short he stated that he would like to include it, but he could not commit to when. He did point out that currently a Deep pipeline in V-Ray was a great approach for V-Ray customers, before any possible V-Ray Cryptomatte solution is implemented.
The Foundry (now branded just Foundry – with no THE), are keen to see a standard become established but already Cryptomatte is being used successfully by many facilities and frankly after seeing it work so well in Clarisse it is easy to see why.
Pixar also is keen to explore it further, speaking after one of the RenderMan sessions, they suggested that RenderMan might support Cryptomatte in an upcoming release. Pixar and others are faced with several possible ways forward with tools like Cryptomatte, including a similar but not identical improvement to Deep Image Compositing using Subpixel Masks that was developed at Dreamworks Animation. Unlike Cryptomatte the Dreamworks solution is a Deep Solution, but by using an 8×8 Subpixel-mask their deep compositing solution provides anti-aliasing of deep images while keeping memory and disk sizes in reasonable check.
Weta Digital has one of the most advanced Deep pipelines in the world, and uses the approach as the core of their compositing pipeline, but then Weta also has one of the most impressive technical backbones in the world. Other smaller facilities struggle with the sheer weight of data in Deep pipelines especially as the format from ILM was not designed for fast access use as is needed in a compositor such as Nuke.
Chaos Group
 We attended the live podcast recording of CG Garage. Christopher Nichols is a great communicator. He also joined a panel on Virtual characters the day before that I chaired along with others such as Vince Baertsoen (The Mill), Steve Caulkin (Cubic Motion), David Morin (David Morin LLC), and Hao Li (USC-ICT).
We attended the live podcast recording of CG Garage. Christopher Nichols is a great communicator. He also joined a panel on Virtual characters the day before that I chaired along with others such as Vince Baertsoen (The Mill), Steve Caulkin (Cubic Motion), David Morin (David Morin LLC), and Hao Li (USC-ICT).
Chris, it seems, is effectively in charge of professional engagement at Chaos Group, and he does a brilliant job in connecting in a respectful way with the high end V-Ray community. One of his initiatives is the CG Garage Podcast and at FMX he was recording a live show.
You can listen to this show in a week when it airs on his podcast channel, via his site but a couple of points of note:
V-Ray will be releasing GPU–CPU hybrid rendering capabilities. Chaos Group ‘leaked’ that they will be releasing a combined CPU and GPU rendering solution. This addresses much of the central problems of memory allocation, task splitting across units and being able to use the CPU and GPU simultaneously. For the first time V-Ray will compute the same CUDA code on both the GPU and CPU, with the exact same results, allowing users to maximize their hardware, while paving the way for wider adoption of GPU rendering.
This grew from actually debugging GPU rendering and trying to simulate it on the CPU. Vlado commented that as the GPU code was so streamlined, when he ran the CUDA on the CPU, it actually ran faster than he expected.
 Memory limitations inherent to GPU computing have always been a fundamental challenge when rendering on GPUs. With recent advances to V-Ray GPU, Chaos Group has reduced overall memory usage by up to 70%, and up to 700% through On-demand Mip-mapping, an intelligent way to automatically resize textures. Since textures consume the most memory, solutions like these will radically increase the size and complexity of the scenes artists and designers can render.
Memory limitations inherent to GPU computing have always been a fundamental challenge when rendering on GPUs. With recent advances to V-Ray GPU, Chaos Group has reduced overall memory usage by up to 70%, and up to 700% through On-demand Mip-mapping, an intelligent way to automatically resize textures. Since textures consume the most memory, solutions like these will radically increase the size and complexity of the scenes artists and designers can render.
Adaptive lights system has recently been introduced. This is a way of speeding up ray tracing by avoiding the problem of sampling every light for every ray. The system analyses the scene to work out what lights it really needs, and it adapts as it goes along, thus speeding up by reducing unnecessary light computations and significantly reduces render times.
Pixar
Dylan Sisson gave a talk on RenderMan with special attention to the Oscar winning short film Piper.

In addition to covering the short film (which we have done extensively), Dylan also showed two really interesting technical examples. The first was how Renderman was being used now in episodic television and in ways that render far faster than a traditional high end Pixar feature.
Leif Pedersen created a domestic robot scene which Dylan then had rendered with all the bells and whistles of a major Pixar feature, including complex SSS, refraction, bi-directional indirect illumination and loads of lights. He then rendered it again with a more ‘toon’ type array of settings. The render times and final frames are below: (click on them for full size version)


The great thing is that the Broadcast version looks clean and fun, in every way acceptable, but at 3.5 mins a frame it is well inside the render budgets of most Broadcast workflows.
As a side note, Dylan also provided a great demo clip showing just how powerful bi-directional path tracing can be. The clip below has a light and a fresnel lens. This is exactly the type of complex caustic solution that bi-directional path tracing does so well, but RenderMan RIS can be full uni-directional as well.
On a more complex note, Dylan showed the clips from Pixar’s recent JCGT paper: Efficient Rendering of Volumetric Motion Blur. That paper introduced temporally unstructured volumes (TUVs), a data structure for representing 4D volume data that is spatially structured but temporally unstructured, and Reves, an algorithm for constructing those volumes.

While a lot of work is done with Motion blur generally, much less has been researched on getting volumetic motion blur correct. Here parts of the volume, more with different rates and the new system from PIXAR, provides a data structure that supports efficient rendering of motion blur effects in volumes, including sub-frame motion. Reves is a volumetric extension to the classic Reyes algorithm, and produces TUV data sets through spatio-temporal stochastic sampling.
Compared to the current state-of-the-art in volumetric motion blur, Pixar’s new approach produces more accurate results using less memory and less time, and it can also provide high-quality re-timing of volumetric data sets, such as fluid simulations.
This is easy to see if one looks at the amount of blur at the source of this simulation compared to the outer parts of the volume.
The original research and paper were published by Magnus Wrenninge at Pixar Animation Studios. Magnus has previously won a Technical Achievement Oscar in 2015 for his work with Field 3, a library for processing volume data for computer graphics. I was also lucky enough to moderate a panel with him at Siggraph 2011 (when he was at SPI).
Fun Pics from FMX: ( Including some of fxphd and fxguide members who stopped us to say Hi) .








