Rogue One came from an idea from ILM’s John Knoll. And just as was the case on the original Star Wars in 1977, John Knoll and the team at ILM used Rogue One to push the boundaries of visual effects for a whole new generation, especially in the area of digital humans.

While Rogue One is in contention for a visual effects Oscar in its own right, the team at ILM have already won the recognition of the Academy with a 2017 Sci-Tech Award.
The Oscars are awarded by the Academy of Arts and Sciences but the science and technology awards are not for one single film but a contribution to the craft of filmmaking, normally over years. In this case, four people who were at ILM are honored for their development of the facial pipeline at ILM.
The Technical Achievement Award (or Academy Certificate) was awarded to Kiran Bhat, Michael Koperwas, Brian Cantwell and Paige Warner for the design and development of the ILM facial performance-capture solving system.
“This system enables high-fidelity facial performance transfer from actors to digital characters in large-scale productions while retaining full artistic control, and integrates stable rig-based solving and the resolution of secondary detail in a controllable pipeline.”
The award winning face pipeline that was used on Grand Moff Tarkin actually started after Kiran Bhat and Michael Koperwas joined up to solve the faces for Teenage Mutant Ninja Turtles.

Koperwas had worked on Rango as a character CG supervisor and knew what the artist needed, while Bhat is a self described maths guy.
Teenage Mutant Ninja Turtles was very complex and demanding, so much so that when ILM was awarded the film Warcraft, ILM put together a completely separate second team to solve the faces pipeline for that film. The facial pipeline development team for Warcraft was Brian Cantwell and Paige Warner.

These two teams then worked fairly separately, sharing work but not joining in a production senses until first of the new Star Wars films Episode VII: The Force Awakens.


TheTeenage Mutant Ninja Turtles team was focused on getting their digital characters to have much better lip and facial emotional translation from motion captured actors to final lip synced characters. While the Turtles required massive re-targeting, ILM still wanted to have the actors faces more accurately captured than ILM had ever done before. The Warcraft team faced a huge problem of delivering vast amounts of on screen digital characters talking. Like Turtles, they were keen to have the lip sync accurate to the performance, but they also faced an enormous amount of digital dialogue. Their solution needed to be very direct as a very manual process would blow out all of the film’s schedules and budgets.
So how does the Tarkin and Princess Leia face pipeline work?
The process starts with two sets of scans of the actor who will be driving the character. The first is a facial model and skin texture scan done in a USC-ICT invented Lightstage. Here, a set of cameras under both controlled and structured lighting can sample a very accurate high resolution facial texture. The detailed model of the actor provides not only the shape of their face but how their skin reacts to light.

fxguide has covered the Lightstage in great detail before, but the master contribution of the Lightstage is to get a separate sampling of the diffuse and specular skin reflectance properties.The specular pass in particular is capturing light that has not been diffused by scattering beneath the skin, so it provides a detailed skin surface detail to an unparalleled level. The original Lightstage is from USC -ICT invented by Dr Paul Debevec, while the Rogue One the team used a licensed Lightstage at OTOY in LA to scan Actor Guy Henry.
After Guy Henry was scanned in the Lightstage he was then scanned again in a Medusa rig. This is a special expressions or FACS rig invented by ILM’s sister company Disney Research Zurich. The Medusa rig looks somewhat like a cutdown Lightstage, but is very much about capturing the various FACS poses and the transitions between them. Sitting quietly in the Medusa Rig, Guy Henry ran through a set of FACS poses, ‘pulling’ faces that allowed a precise library of facial movements to be stored.

These FACS expressions relate to emotions and dialogue (or rather lip shapes for producing spoken dialogue called visemes). Visemes are described by Disney Research as “distinctive speech movements of the visual speech articulators. Traditionally visemes have been surmised as the set of static mouth shapes representing clusters of contrastive phonemes (e.g. /p, b, m/, and /f, v/).”
The Medusa scans produce a key library of expressions for ILM called the FEZ library, and you can make a digital face create any expression you like by adding and combining scans or ‘blendshapes’ from the FEZ Library. What is critical about these FEZ library blendshapes is that a facial ‘rig’ can be provided to the artist that has sliders for moving between expressions.
It is relatively simple to do photogrammetry of someone pulling different expressions. But it is a key step to have these all connected together in one rig which will not only allow the digital face to move between expressions (have spacial cohesion) but also the blendshapes can be combined and mixed. The production of a great rig remains to one of the key contributions to any facial pipeline. A blendshape rig is the dominant approach to facial animation used throughout the industry.

ILM next needed to have Guy Henry give his actual performance; in other words drive the rig. This is a motion capture process where the actor’s face is tracked and whatever expression they have at any one moment is interpreted or solved into a combination of FACS shapes from the FEZ library.
Motion Capture is another major piece of intellectual property for any facial pipeline. In days gone by, this was done in a lab environment but for some time ILM has wanted to capture the actor’s expressions while they moved around on set. This on-set motion capture was very much pioneered on the film Avatar where Weta Digital handled most of the facial pipeline. But ILM was also a major contributor on Avatar and this head-mounted approach is now universally adopted by most vendors.
By having Henry acting on set instead of isolated alone on a capture stage, Director Gareth Edwards could have him interact with the other performers. While Henry is acting his expression is recorded by multiple tiny cameras on a head mounted rig (Avatar originally used just one).
These multiple cameras allow a 3D reconstruction of facial features or points that the system is tracking on the face. From the tracked points, a 3D model of what Henry’s face did on set is built, or rather manipulated, to align with the points that have been tracked. The key is to move from a set of points that are separately sampled each frame to a complex 3D moving model of the actor’s face, just as it was on set. As the rig uses the blendshape FEZ library the face now moves smoothly between poses without jittering and with as much accuracy as possible.
It is at this stage a few years ago that the first Ninja Turtle team had a brilliant break through. The normal solution is to just ‘solve’ from the rough point cloud of tracked dots on a single frame to a combination of blendshapes that produce the same facial pose. If the points indicate that the eye brow was raised and the lips closed etc, then the blendshape sliders are all tweaked to match as closely as possible. This is non-trivial but the maths for fitting the best solution had been known and published for sometime. The problem was it never does match fully.


Part of the reason is that the computer is trying to match the on set expression to the poses that the actor gave when seated quietly in the Medusa rig. But when they were trying to pull realistic facial expression their head was not really moving around, the actor’s faces were not captured displaying the right inertia, gravity or physics that one’s face has when you are on set turning and looking up to deliver lines. One might think that this is a tiny difference, but tiny differences are critical with faces. To fix these differences, the team invented ILM’s SnapSolver during the Ninja Turtles development stage. This is a genius innovation in an already highly complex pipeline.
SnapSolver
After the computer does the best possible match to features on the face between on-set and the Medusa FEZ blendshapes, ILM introduced a new stage which is the SnapSolver. This new tool adds tiny offsets to make the silhouette of the faces match even more accurately. This clever innovation and piece of software is a big part of that extra 5% ILM manages to achieve in high frequency facial expression accuracy. The FEZ library blendshape solver produces a result which is close, based on feature tracking, such as the eye brows or the corner of the lips. The SnapSolver then takes this solution and compares the silhouette that this ‘digital facial hockey mask’ outputs back to actual filmed face.
It is important that it is the silhouette, as in theory the computer has already aligned as many facial features as possible. If the lower lip silhouette (i.e. ignoring the teeth, tongue, etc.) differs from the silhouette it calculates from the live action plate the software tweaks it to align. It does this all over the face, especially around the mouth and soft tissue areas of the face.
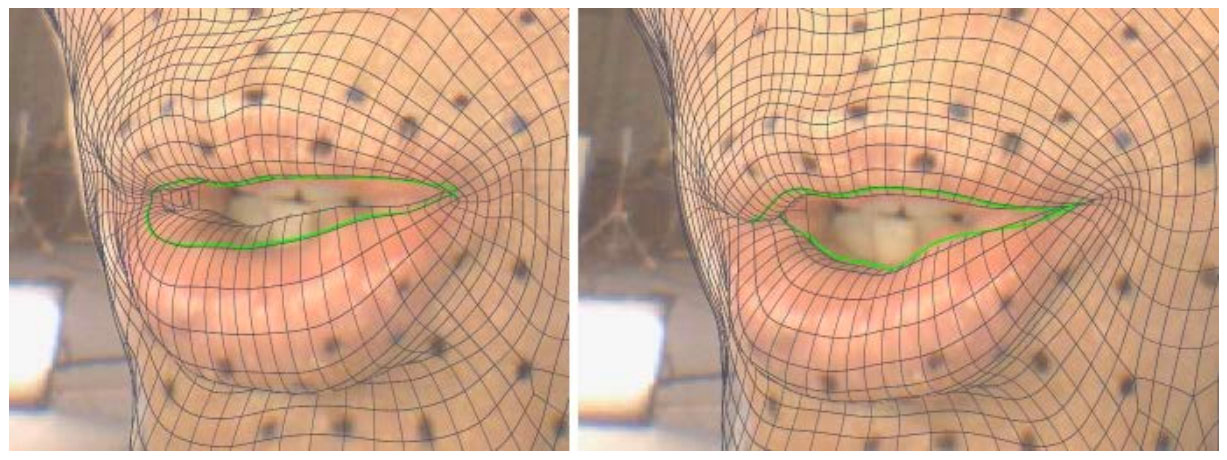


This is a per-vertex per-frame tweak that gets the facial rig more closely aligned by effectively adding a tiny delta or offset to the blendshape solution everywhere that the blend shape version of the digital face is not perfectly matching whatever the actor’s face did. It could be many reasons. It could be momentum, it could be blood flow from a heated performance, or it could be just that the original Medusa expressions were not quite close enough to how they acted on set. It does not matter, but these tiny tweaks preserve the actors fine detailed performance as it moves from the head rig filmed footage to the animated facial rig. This does not stop animators from tweaking the blendshape rig, as the delta offsets were on top of the major expressions controlled by the blendshape sliders.
When all this was being invented on Ninja Turtles, the other team on the film Warcraft were so impressed with this innovation that they invented a way use it even more aggressively: make SnapSolver work even harder. They saw a way to magnify or ‘amp’ up the use of SnapSolver to allow the ILM Warcraft team to do the huge volumes of facial animation needed for that film. The Warcraft team also did a bunch of other innovative things like better eye tracking, but the SnapSolver approach made a vast difference to performance fidelity. On Warcraft the CG characters really maintained the acting subtly of the original performances of the actors.
The new approach that Brian Cantwell and Paige Warner pioneered was based on questioning why the SnapSolver only needed to add tiny delta offsets. They reasoned that if Warcraft had to process hours of facial motion capture footage then the detailed facial rig approach might prove too time consuming. Their innovation was to allow a much rougher rig to be built that was faster to make. But then rely on the SnapSolver to add bigger, more significant offset deltas to bring the rough and quick blendshape solution to match the specific actor’s face at that instant.

While Bhat and Koperwas had expected the SnapSolver to make only tiny but critical adjustments, the Warcraft team built a pipeline where the SnapSolver did a huge amount of the alignment. The ‘cost’ of doing this is that the system was less accommodating to artist intervention. Warcraft aimed to take the entire performance of an actor on any one take, match it very closely and then retarget it. But if the director did not like the performance completely, they encouraged him to get the actor to do another take, rather than expect that they could edit and tweak it as part of the animation process.
Rogue One faces
The process to this point has produced accurate animation of the actor, but the digital model is still of that actor and not of the character they are meant to be playing. The digital double is a near perfect recording interpreted into an animatable rig that wont flicker but also keeps high frequency subtle facial performance but it now needs to be retargeted to the actual character by that Snoke in Force Awakens or Tarkin in Rogue One.
For the latest Star Wars film this meant producing a model of Tarkin and another of Leia. Here, ILM was lucky. Not only did they have great reference of both actors, but John Knoll himself discovered a plaster life cast had been taken of the actor Peter Cushing in 1984. This allowed them to model and sculpt a digital Tarkin head very accurately. On screen you mostly see Henry’s filmed body with a digital head, unless the lighting did not allow a composite and then the whole body was replaced.

For Leia, with Carrie Fisher’s blessing, the team sculpted a digital Leia soley from reference. Interestingly, the team discovered that Leia also changed, or rather Carrie Fisher physically changed somewhat during the filming of New Hope. As it made plot sense, they picked a scene close to the start of New Hope and thus close to the timeline of Rogue One as the reference look for Leia.
Once a digital model of the target character is made, one might be tempted to think that all that is needed is to retarget from the actor’s matching digital head to the final new characters digital head. After all, the team now have a perfect replica digital head delivering the new lines and a corresponding digital model of say Tarkin? Not so.
Unfortunately, while Henry acted and sounded very much like Peter Cushing, as with all such work, he sometimes used different parts of his face and lips to make the actual visemes. For example, when Peter Cushing played Tarkin he made an ‘aah’ sound without really moving his upper lip. This is where the artistry of the animators at ILM comes to the fore. The digital character of Tarkin needed to not only sound and look like Peter Cushing but also move his lips and annunciate in the same way as Peter Cushing did when he was playing Tarkin.
Once the animation is complete the team rendered the head using the new RenderMan RIS integrator. Getting the skin and the way light is diffused and reflected is informed from the original Lightstage scans. RenderMan models the way light behaves on human skin and hair very realistically and in a physically plausible way to how the real on set lighting was when filming the plates. While the animation was accurate and effective the team still faced several integration challenges. The lighting style deployed by Star Wars’ DOP Gilbert Taylor in 1977 was quite different in style from Greig Fraser, who lit Rogue One. Furthermore, Director Gareth Edwards liked to operate many shots himself in a very hand held and almost documentary style. Both the lighting and the camera movement are therefore different.
ILM faced the challenge of either making the new Tarkin match New Hope perfectly but be lit very differently than other shots, or light Tarkin in the new style of cinematography and no longer match as closely. In the end, the solution was a mix; some shots remained very faithful to the on set modern lighting, while others moved to a solution closer to the original film. For these later effects shots, Tarkin’s whole body needed to be replaced as the face lighting of any character needs to match the light falling over their body. “In about 50% of the shots we replaced just the head and we used the body of Guy Henry,” explained Nigel Sumner, Visual Effects Supervisor at ILM, who was a key part of the digital human team. “On the other shots we did a full digital replacement using Guy as a guide and in those shots it also gave us the ability to reframe if we wanted to.”
“Going into this we had done digital character’s before, with facial motion capture performances, but we had never tackled something that had to work as a very recognisable representation of a real person before” commented Sumner.


“On Warcraft we had done work that allowed us to do very convincing performances,..quite phenomenal..and that let us understand the complexity and challenges involved, … but there were a number of challenges we faced on Rogue that we didn’t fully appreciate going in,” says Sumner. Artists have produced believable digital still images of people, but the complexity of moving from a still to a fully animated character turned out to be even more difficult and challenging a problem than the ILM anticipated.
Getting something that reminds one of a great real actor or even looks and sounds like them is a very different problem from one believing they are them
“There a number of levels of difficulty, and some of that comes from it not just being a digital character with life breathed into them but it is a recognisable character, someone that behaves, performers – as them,” relates Sumner. He makes the point that standup mimics can give a performance that sounds or looks a lot like a character, but we, the audience, do not believe that they are that character. Getting something that reminds one of a great real actor or even looks and sounds like them is a very different problem from one believing they are them.

For example, when Henry’s digital double said a line, it felt as if that was a good digital Henry. But when that same line was retargeted to the Tarkin digital double, it did not seem like it was Peter Cushing saying that line as Tarkin. It might have been believable if the audience did not know Peter Cushing, but as they do, the delivery felt wrong.
“And that gap was one of the unforeseen challenges that we had to overcome when we went into production,” explains Sumner. “A line could sound the same between the two actors, but they would use different facial muscles so it would not look authentic. These little differences – that even a mimic would not be able to train their faces to match.”
One of things that John Knoll suggested and became part of the process was producing the first digital Guy Henry face to such a high level. “We joked that we should now make a Guy movie just because of how good the asset looked,” says Sumner. He further explained that they stopped short of modeling Henry’s hair, but it the asset was modeled “right down to the fine detail skin texture, with fully working eyes. So when we were checking how well we had capture the data we would composite Guy in there and that would allow us to check performance against the actor, the lighting against the scene and that was a good initial step to make sure the data was as close as possible.”
Interestingly, John Knoll also directed the effects team to produce a Tarkin that was accurate to how we all remembered him – not to a precise shot of him from Ep IV New Hope. For example, the lighting in the 1970s was much harsher as the ISO of the film was much lower; New Hope was shot on Eastman 5247 which was 100T. Compare that with the Arri Alexa 65 digital which has a base sensitivity of 800 ISO and it can go to 3200 ISO, which is between three and five stops higher. Due to the low ISO, the lighting was much stronger and harsher so the makeup was much heavier.
To be a ‘perfect’ technical match to the Tarkin of 1977, the digital model of 2016 would have needed very heavy skin makeup, which would again be very different from the levels of makeup of all the real cast in the same scenes. No one remembers such details, as all of the cast had the same lighting and makeup in 1977, but the gap still needed to be bridged between reality and looking correct to today’s audience. The ILM team ended up with three basic lighting environments for Tarkin and one for Leia. Each needed to be addressed and balanced separately but they did find the process sped up once they learned what the key issues were to pay attention to. In the final film, there are 32 shots with Tarkin (two and a half minutes of screen time).

Leia’s double, Ingvild Deila, was shot on set with about 100 makeup dots on her face but no actual head rig while she delivery the single word of dialogue ‘hope’. Instead of a head rig, five off screen cameras were used to capture her performance. She was also filmed separately without dots delivering the same line but at a higher frame rate. The original makeup and wardrobe designs from Episode IV were referenced for how Carrie Fisher had been made up and to inform her cloth simulated digital wardrobe. Deila, like Henry, had a Lightstage scan done, to inform the way light would scatter on the digital Leia’s young skin.
Sumner and the whole team were naturally saddened by the loss of Carrie Fisher. John Knoll had a chance to show the work to Fisher and she very much approved. “From what I understand she responded in a very positively – and somewhat ‘profane’ way,” Sumner amusingly recalls. “She was very excited to see the work we had done, and as an artist and a supervisor involved with the work – that is one of the most rewarding things you can hear.”
Leia was just seen in one shot, yet all the performance and digital double matching work for Deila still had to be completed. It is safe to say this single shot is one of the most labour intensive character shots in the history of ILM.
Be sure to check out our other articles covering Rogue One
Part 1: Rogue One shows its Force
Part 2: Rogue One character animation
I worked on Avatar for 3 1/2 years and as far as I know ILM had nothing to do with the facial rig. We used Glen Derry’s Technoprops rigs on Avatar, and to my knowledge Technoprops has no affiliation with ILM.
Was thinking the same thing. My understanding was ILM didn’t do any hero animation on Avatar. The article, on second reading, doesn’t explicitly state that they did but it does seem to strongly imply that they helped develop this tech during Avatar. Touchy subject I guess given the dodgey media coverage by CNet and others about that project.
That is correct. Giant Studios and Weta Digital did all of the body motion/animation and facial animation on Avatar. I hate being pedantic with things like this, since it was a really cool article, but I don’t like it when the wrong credit is given. ILM was most likely given a few big shots or a sequence to help on, as well as a few other 3rd party vendors like Blur, but Giant and Weta did all the the character animation and Weta did the bulk of the VFX/CG work on the film.
This is exactly what my research is about: https://sites.google.com/view/uncannyresearch
If it wasn’t a professional affair I wouldn’t mind so much, but typos in technically-orientated stories bug me a little especially when it comes to getting technical points across. Because accuracy is a key component (ironic considering the subject matter eh?). And there were quite a few here. Sorry to be the narky commenter, but hopefully you guys take that as pertinent and not unreasonable. Cheers mate.
But cool article indeed. I remember years ago being scoffed at (by an ILMer whose name I can’t recall) for asking whether unusual or different mouth shapes owing to character design and/or physiognomy had to be taken into consideration in terms of relatable expressions and dialogue. And yet look at this! I also was very interested in the same vein to hear about ESL animators having a bit of difficulty with English/American mouth shapes too. Fascinating stuff.
Finally as far as “pioneering”, I’m pretty sure Weta *started* getting into onset capture on LOTR for some of the Gollum stuff, not Avatar? And I think I remember ILM’s Avatar scenes had nothing to do with mocap? And not a huge part of the workload?
Not *everyone* agrees as you said. Watch out for all-encompassing statements, mate. Especially when they’re opinions not facts. And the “obvious” statement is redundant for those of us who know Cushing is dead and Fisher isn’t 19 and how ELSE could it have been achieved. It becomes a catch-22. Sure many of us effects-types noticed immediately, but even there there’s argument over which character was better/worse. And then there’s the larger general audience. A great many of whom *didn’t* realise the digital trickery until it was brought to their attention. So no, not everyone agrees. At all.
And considering you’re so damning, I’d love to hear your constructive solution – a blasé/careless and unsupported grade-school dismissal like “is wrong… is wrong…is wrong” and “just looks digital” is really easy to do, but doesn’t exactly stick when you can’t offer any specifics or explain for example how the shape can be wrong when it was taken from a lifecast of the actor himself! So “poorly” sort of has no meaning when you haven’t offered any understanding or explanation. I’m sure everyone would love to know! And Social Network is an apples-to-oranges comparison.
While I was aware of the effect for every second (and that was probably inevitable given the aforementioned context), I still acknowledge these shots were a monumental step up in terms of sheer magnitude and *way* beyond what’s been done bin terms of difficulty, whether they convinced “everybody” or not…