
“The entire motivation for Pinscreen is a comprehensive system where you can enable interaction with virtual humans,” explains Pinscreen founder Hao Li.
Pinscreen is at the forefront of Neural Rendering and digital human research that uses Machine Learning (ML). The LA-based company is now the full-time focus of Professor Li, who has just resigned as the director of the Vision & Graphics Lab at the USC Institute for Creative Technologies, and Associate Professor at USC Viterbi School of Engineering.
The company has two key streams of research, both involve technology built on their PaGAN and PaGAN II Generative Adversarial Networks (GANs). The first involves making digital humans from data as simple as a single JPEG image to puppet as an avatar. The second R&D area involves the end to end process of making high-quality Agents using both cutting edge rendering technology and state of the art AI which infers what a face should look like and uses Neural Rendering. By combining real-time rendering and technology similar to DeepFakes approaches, Pinscreen is set to deliver stunningly real and interactive digital humans.
Hao Li will be presenting the company’s latest work as part of the second day of the online Real-Time Conference (RTC), June 9th. His presentation is part of the session co-chaired by fxguide’s Mike Seymour with Facebook’s Christophe Hery. Building from the successful April RTC session on TelePresence / Avatars / Agents / Digital Humans, the June 9th event will focus on how ML can help in the creation and application of digital humans. Experts from New Zealand, USA, Israel, and Australia will all discuss the cutting edge new approaches to digital humans using advanced AI. Machine Learning, GANs, and Deep Learning looks to greatly influence face replacement, de-aging, digital makeup and character creation as these new Neural Rendering AI technologies become a part of a professional digital human pipeline.
Generative rendering using GANs and other similar approaches have shown to be able to produce remarkably accurate and realistic results, but full generative approaches have almost no artist control parameters. Neural rendering aims to use these ML tools but introduces controls to guide the process. Full computer generative rendering avoids long render times and a vast amount of artist time needed to create traditional 3D models. Generative rendering swaps laborious artist time for lengthy computer training time, but the final rendering is able to run very quickly. It can do this as it infers the lighting, performance, and responses for the final result. This comes at the price of not having fine-grained artist controls or keyframe parameters that an artist can adjust. Neural Rendering, based on similar ML, aims to sit between traditional CGI approaches and fully automated generative rendering approaches. Neural rendering uses deep neural networks to solve digital people while still enabling some explicit control of the final render. This translates to artist enabled control over illumination, camera parameters, posing, appearance, motion, or lipsync dialogue.
A PaGAN impersonation of the actor Sean Bean
Neural rendering techniques are diverse, and they build on seminal work on GANs by Ian Goodfellow (now Director of ML at Apple) by combining GANs with Variational Autoencoders (VAEs). A typical neural rendering approach takes as input images corresponding to certain scene conditions (for example, viewpoint, lighting, layout, etc.), builds a “neural” scene representation from them, and “renders” this representation with new scene properties to synthesize a new face, body or scene.
Face Replacement
To understand the far-reaching consequences of Pinscreen’s research into end to end agents it is best to start with face replacement. This type of technology avoids the typical CGI pipeline of model/texture/light/render and instead the ML program infers the image of what the new face would look like if it was positioned and lit by the original background face. What is important to understand is that the new face is neither modeled as a mesh nor lit with 3D lights to illuminate it. The face is implicit in look, expression, and position. In other words, it never explicitly works out the new face’s geometry, rigging or 3D position. Instead, it learns both the original background face and the face of the new subject. It then statistically approximates what the next frame should look like.
This statistical approach first became widely known due to the non-commercial Deepfake program. Pinscreen does not use the Deepfake software but like it, their proprietary PaGAN II core software infers the next frame during a face replacement and can produce exceptional results thanks to years of research into ML. In a face replacement such the Sean Bean demonstration above, there is a one to one mapping. One target and one subject, each trained on for over a day and then rendering in less than a second a frame.
Li’s plan is not just an end to end digital human creation system, but one where faces are generated using AI and rendered with a neural rendering approach. “In terms of scale, we’re actually building a whole platform that allows the entire avatar to live on a cloud and to be streamed directly to people”.
Pinscreen originally built PaGAN to solve the problem of creating a 3D mesh face from just a single Jpeg picture. “PaGAN was written a couple of years ago when we introduced this method, it was to intended to use just a single input image, but have the ability to generate photorealistic faces,” say Li. “But, we’ve actually progressed from there,…One of the first things we changed is the ability to not just learn from a single picture, but from multiple pictures or even videos as training inputs. He did this in order to facilitate faces that are more personalized and higher quality. The second thing we have done is to focus on real-time. If you want to make a virtual assistant, you can’t use pre-rendered content as people have done with things like Deepfakes. You have to generate something that can instantly produce the face so that you have the ability to interact with it,” he explains.
The next step was for Pinscreen was to build an approach that doesn’t just map from a known person to another known person but allows the program to handle a ‘Many to One’ mapping. The many to one mapping means that “any person can appear, with specific training, and we can turn their face into a photorealistic face”. The first demonstration of this new instant approach was shown publicly at the world economic forum in Davos, where Pinscreen showed their real-time face-swapping demonstration. fxguide reported on this demonstration in Switzerland earlier year. For this demo, any person could use the system without pre-training, and yet still to be able to generate a photorealistic face interactively.
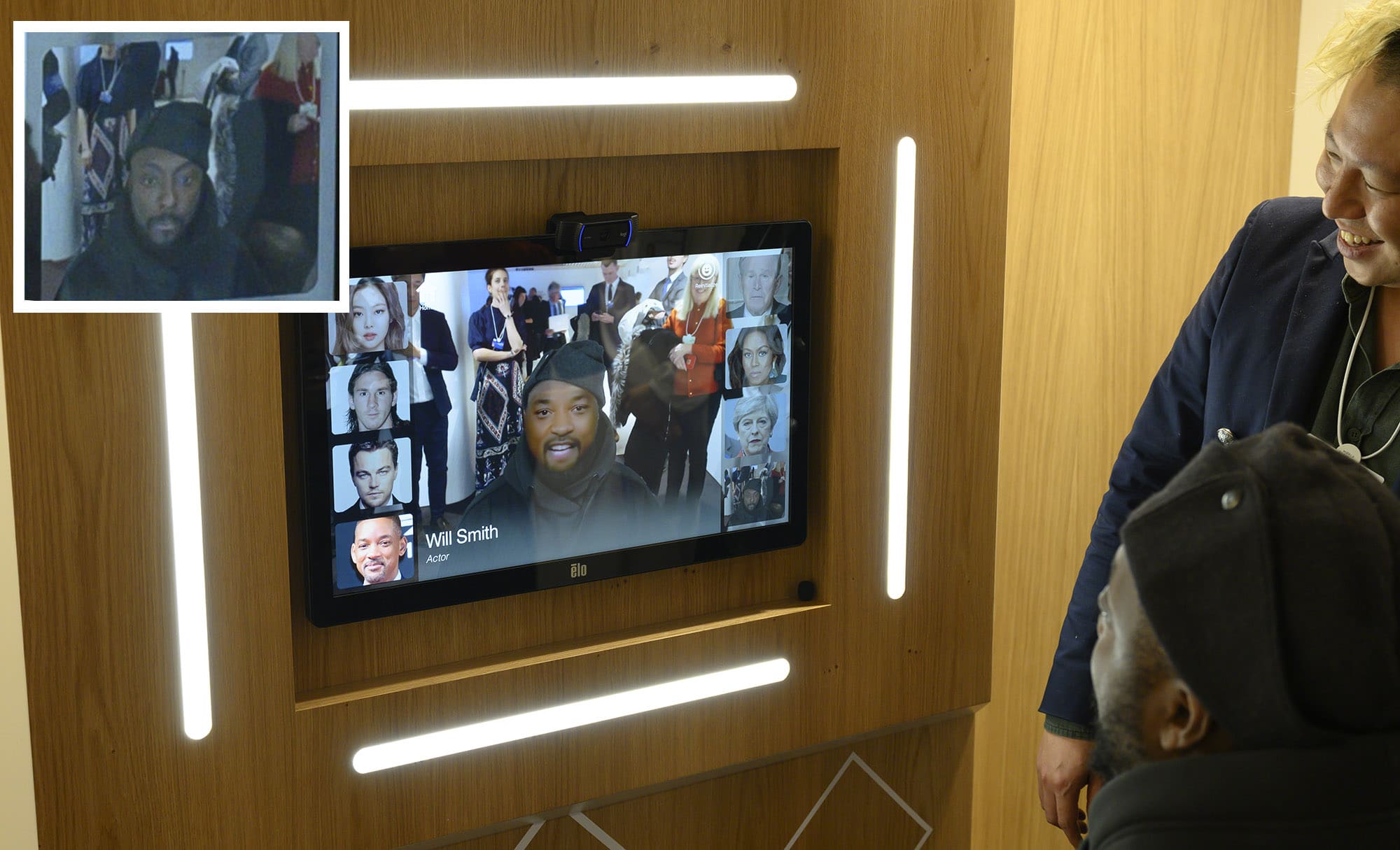
To accomplish this, the system needs to be able to track a face while isolating expressions. “The important thing normally is knowing all the details of the face that is being mapped, …which normally means training data,” he says. The original deepfake approach to face replacement is a one to one method, with training on both the input subject and the target. With Pinscreen’s live approach, there was not time to train on the subjects face, since it needed to work on anybody who walked up. “We dealt with this approach by training another network to have the ability to handle lots of people’s faces, and then map all those faces to a very specific intermediate representation. From that (intermediate) we can infer to a specific target subject that we want”. In summary, to achieve a real-time instant face swap, that appeared to need no training, first the process tracks someone’s face (similar to original PaGAN I). The process analyzes their face and expressions, but it has been pre-trained on how a large number of people would map to a special internal intermediate specific ‘character’ at the core of the software. And this internal data model, “allows us to do, at inference time, handle any person and generate a compelling likeness of the target subject” Li explains. Having the PaGAN II neural network do this implicitly allows Pinscreen to both be fast (real-time) and appear to work without source training data and yet still produce a very realistic and accurate final output. While PaGAN I worked with anyone (even from a mobile phone app), the results were less realistic. With PaGAN II, it is actually pre-trained so it can handle everybody and yet Pinscreen has the ability to infer(render) in real-time, with most of the aspects of the face being implicitly solved and completely skipping traditional CGI methods. The new PaGAN II pipeline provides a higher quality output but still runs in real-time.
If one is willing to forgo real-time, such as for visual effect pipeline, a third approach is also possible. A direct GAN would be an inflexible generative render. To produce a super high-quality neural render the PaGAN II can still be used but with three key differences. First, all the optimizations for real-time can be removed, these often had minor quality loss issues for the sake of speed. For example, a deeper more complex network can be used. Secondly, there is no need for the ‘Many to One’ stage as time can be taken to train on both the Subject and Target faces, but thirdly and most importantly, it is how the team trains PaGAN II. As many academic papers explain, how one trains a Neural Network is very important. “A lot of the deep learning papers, discuss how you train a Network,” says Li. “They explore how you augment the data? What is your strategy and how do you package batches of training data,” explains Li. “All these things lead to different results, so we now have a very specific way of training.” Given that PaGAN II was built to be a Neural Render which allows user intervention, the team can address issues that a straight generative network could not. “We tweak the network, and we designed the network to handle that,” he says. Without the adjustments, “you cannot guarantee that the expressions of the final person don’t just look weird. And that weirdness is not necessarily blurry artifacts. For example, it could be eye gaze or weird compositing blending artifacts. These are the things that we’re focusing on being able to now get right”.
Sean Bean Demo
To demonstrate the high-end PaGAN II approach we inferred an imitation of Sean Bean (L) by fxguide’s Mike Seymour(R). (While Mike is no actor, and an Australian (!), he did impersonate Bean’s distinctive UK accent, for this – he asks forgiveness).

The Sean Bean / PaGAN II demo required about a day of training but then renders at a rate of just under a second a frame. This is still fast by 3D standards, but much slower than the 30Hz real-time PaGAN demo shown in Switzerland.
Agents
![]() While Avatars and face replacements such as this are driven in by a source person, they could also be driven by an AI agent, not unlike a Siri or Alexa. Over the past year, Pinscreen has concurrently developed an entire pipeline for such graphical agents. This includes Natural Language Processing (NLP), AI chatbots, motion synthesis, class simulation, real-time body and hair simulation, and more.
While Avatars and face replacements such as this are driven in by a source person, they could also be driven by an AI agent, not unlike a Siri or Alexa. Over the past year, Pinscreen has concurrently developed an entire pipeline for such graphical agents. This includes Natural Language Processing (NLP), AI chatbots, motion synthesis, class simulation, real-time body and hair simulation, and more.
“We now have on the AI side, an entire pipeline that can do a state of the art agent,” says Li proudly. “That includes vocal recognition, response generation for freestyle or everyday conversation, as well as the ability to actually generate speech(audio), -so from text to speech to lip animation”.
On the left is a neural rendered real-time hybrid agent image, with a base generated in UE4, including interactive, dynamic cloth, and her face enhanced via PaGAN II Machine Learning.
Audio Speech
Pinscreen is very interesting for its digital agents to be more than just purely rule-based agents. They are working on hybrid bots that respond based on a rule-based approach and also uses AI generative methods to simulate freestyle conversation discussion and questions. This would allow Pinscreen’s agents to provide more accurate small talk and semi verbal human-style responses. Li is keen for their agents to provide a range of verbal and semi-verbal cues found so commonly in natural conversation, such as ahh, ha, um, and huh. These almost throw away things, like micro facial gestures, add realism, intention, and emotion, just as much as larger facial clues such as broad smiles or frowns.
“The nice thing about this pipeline is that one anyone can personalize it. And it is so fast, that we can generate an accurate voice and there is still time for us to compute other components such as generate the right facial expressions, emotion, and lipsync.
Influencers
Pinscreen is already producing agents that are being used to model clothes and will hopefully soon be launched to become virtual Influencers in Japan. These autonomous agents are all running in real-time for interactivity, and unlike many stylised Japanese ‘Manga’ characters, these use both the UE4 game engine and the PaGAN ML to produce highly real-time realistic agents. The Pinscreen custom agents can move, talk and emote. The ML runs in the game engine to provide dramatic quality for a real-time application, including cloth and hair simulations. “We are all in on the Unreal Engine for this,” Li comments. “The real-time clothing they wear was shown at SIGGRAPH Asia in December last year and the new Pinscreen AI Agents will be released soon”.
To achieve their aim of an end to end solution, Pinscreen is had to apply its ML Neural Rendering approaches not only to faces, but bodies, hair and clothes. The company is now starting to produce avatars and agents as full humans.
Talks & Demos
Pinscreen is very focused on real-time and Pinscreen are a key presenter at RTC, next month. “In June I’ll talk about how we’ve gone from ‘deep fakes’ to virtual assistants to virtual connectivity. Plus there are a couple of new things that we hope to show on real-time telepresence and maybe even a surprise or two!”, concludes Li.
For RTC Registration Click Here

fxguide is a proud media partner of the RTC. Fxguide’s Mike Seymour, along with Facebook’s Christophe Hery, are curating the June 9th session on Digital Humans | Artificial Intelligence | Machine Learning | GANs.