At this year’s SciTech Oscars there were three separate awards given for the invention, development and implementation of deep compositing.
“It is definitely a great honour and the Academy along with the reviewers did an amazing and thorough job,” commented Colin Doncaster of Peregrine Labs, one of those honored at this SciTech awards. “The recognition is a huge validation for everyone involved, from the initial use cases to ODZ and EXR 2.0, it’s great to see everyone working towards a standard to embrace acceptance and innovation. This very well could have been another case of a studio patenting technology and we’d all be without it. It was great to see Peter’s (Hillman) and Weta’s involvement in this be acknowledged by the Academy, and of course the initial concepts from Pixar. Jon (Wadelton) and others at The Foundry also had the insight to work with the various parties to make it available to a wider audience.”
Since our first coverage of this new and robust form of compositing in 2010, (click here for our fxguidetv ep where we originally explained Deep Comp) – fxguide has been following the development and now wide scale adoption of deep comp. Today it is a permanent feature at high-end effects companies such as Weta Digital, Animal Logic, MPC, ILM, FUEL VFX and others, and its use is spreading to mid size productions and even TVCs. Films such as Life of Pi, Prometheus, Man of Steel, Hunger Games: Catching Fire, The Avengers, Pacific Rim, The Hobbit: The Desolation of Smaug all used deep data in deep compositing pipelines. Not only do major renderers and programs such as Houdini and Nuke now allow for deep data but realtime tools like ILM’s Plume support deep data from the GPU.
What is deep compositing?
At its core deep comp is a different way of rendering and working with visual elements. Rather than layering a series of flat 2D renderings of say 3D imagery one on top of another – often times with hold-out mattes – deep comp aims to provide a channel of data in the rendered image that defines not a single Z depth for a point in the image (or pixel value), but rather an array of values that defines how say the fog density changes in front and behind a point in space represented at a pixel value.
Imagine a cloud of smoke – one with an actual varying density of moving smoke – rendered in 3D. The cloud may be at 15m in Z space at its front and the back may end at say 20m, but in a traditional pipeline this cloud is rendered as a flat 2D element with one Z depth position. Perhaps that Z depth position is the front 15m number, or the middle of the cloud is stored at 17.5 units back – either way there is one number for the ‘position’ of the cloud in Z space.
If the cloud is partially transparent clearly something would look very different if it passed in front, behind or actually in the cloud. But in compositing, your choice would be to place a different live action element layer in front or behind this rendered cloud. That’s it. There is no other choice since we have the cloud and the Z depth and no other information. To make something shot on set look like it is ‘in’ the cloud – moving through it – one would need to render the back half of the cloud, the front half of the cloud and use some hold out mattes.

But with deep comp, instead of one number there is a range or array of numbers that express the intensity of that cloud from in front of the cloud, through the cloud and behind the cloud. With deep comp, we can composite the live action plate ‘in’ the rendered 3D cloud since we can look up in this array of numbers exactly how much smoke would be in front or behind at say 18.2m or 16.1m etc. This allows for the compositing to not require hold out mattes and it means re-rendering is greatly reduced. Unfortunately it also means more data per pixel needs to be stored. On complex shots a frame could hit say 800M with this additional data. Furthermore, as the deep comp happens at the end of the pipeline in say NUKE, this data needs to be carried forward – around the facility – and cannot be used and then discarded like say fluid caches.
Yet the benefit is so great that for a studio such as Weta Digital deep data is the “standard way we do absolutely everything – I don’t know how hot to turn off deep data in the pipeline,” says Dr Peter Hillman, a senior software developer at the studio. So beneficial and flexible is Weta’s deep comp render pipeline that, as Hillman expands: “I am not sure we have a button to turn it off. You can throw away the data if you don’t want it, but it is just so useful.” And Weta are not alone; early pioneers such as Animal Logic and many others have re-engineered their pipelines so that, while they carry large files through their process, they have greatly reduced rendering and hold out matte rendering.
Once a deep comp pipeline is adopted it can be used for even more creative lighting approaches. Starting with Abraham Lincoln: Vampire Hunter, Weta Digital used a deep comp pipeline that allows complex volumetric relighting. As Weta stated in their DigiPro 2012 paper, Camera Space Volumetric Shadows, these files each pixel stores are an arbitrarily long list of depth-sorted samples. Elements rendered into separate deep images can be combined accurately to produce a single composited image of the entire scene, even if the images are interleaved in depth. This allows for great flexibility, since only elements which have changed need to be re-rendered, and the scene can be divided into elements without needing to consider how they will be combined. By comparison, in traditional compositing with regular images the scene must be divided into elements in such a way that they can be recombined without edge artefacts or depth order violations. Volumetric deep image pixels represent a volume as piecewise constant optical density and color as a function of depth. Volumetric renders of participating media are generally computationally intensive, so the ability to compute them independently and composite them correctly into the scene is highly advantageous.
For Abraham Lincoln, Weta separated the shadows and lighting from the volume. This allows for large amounts of flexibility during compositing. Here is an extract from fxguide’s 2012 coverage of that paper.
EXTRACT: In this first video below a demonstrative render shows inverted shadows (for clarity) on a static volume with an animated light source, demonstrating the shadow light shafts are consistent under motion.
Inverted God rays.In this second video, deep composite is shown with shadows and phase function of an animated light applied to static volumes, created by fx renders and procedurally within the Nuke plugin. The static environment is unlit (black) and is composited in depth to give silhouettes.
Scattering God rays.In this third video, deep composite is combining the shadows and phase function with a static environment lit by the same light source. The volumes are once again static and rendered without shadows and lighting, which is applied in the deep composite in Nuke – at Weta.
Combining shadows and phase function.The paper went further to show how some work can be done directly in NUKE, with the compositing software producing a low frequency ‘fog’. By adding that with deep compositing, and controlling it with both height fields and even roto, a large amount of the base low frequency work was all done and generated in NUKE. High frequency additional shadows were then added to this allowing even faster workflows and user directed volumetrics with amazing results.
Today companies are moving to deep pipelines but it is not a simple path. While most programs support rendering Deep Data not all compositing packages support it. Furthermore while much attention is focused on the increased file size, the real issue for many can come with network I/O bandwidth, without preparing for it carefully it can place heavy demands on a facility’s servers causing unacceptable internal delays. One of the attractions of using Deep Data is reducing re-renders from holdout mattes. As some companies additionally need to pass on traditional zdepth maps and mattes for grading and stereo-conversion they adopt an partial pipeline. Some pipelines have deep data but convert the files to more traditional z depth maps for most actual shots, knowing that they can access the pre-converted deep data files if need be, and still avoid re-renders but not have the disc file size issues and on going network demands for the majority of their work in comp.
Pixar beginnings
Eric Veach and Thomas Lokovic were honored by the Academy of Motion Picture Arts and Sciences for providing a functional and efficient model for the storage of deep opacity information while they were at Pixar. Initially the work published as Deep Shadow Maps was aimed at solving problems such as hair rendering and worked on a light based projection and storage of deep color information. It allowed for the rendering of self shadowing things like hair and smoke much more realistically.
“A deep shadow map is a rectangular array of pixels in which every pixel stores a visibility function. Intuitively, a visibility function is defined by considering a beam of light that starts at the ‘shadow camera’ origin (a shadow camera is one placed at the light source origin) and passes through the given pixel. The function value at a given depth is simply the fraction of the beam’s initial power that penetrates to that depth.” – from the original Pixar Deep Shadow Maps paper, Aug. 2000.
It is this technology but applied from an actual normal camera view origin that was widely adopted as the foundation of early deep compositing pipelines. In a sense the Pixar paper was extended and applied differently allowing for an array of complex ‘depth from camera’ information to be stored per pixel.

We asked the original authors if they ever envisaged this when they published their original Deep Shadow Maps paper. “Well,” says Veach, “we certainly imagined using it in other ways beyond just the deep shadows. We thought about using it for lighting and as arbitrary function representation – which included images. I left Pixar shortly after we published this work so we never got to take it further.”
“For deep shadow maps the representation has obviously proven to be quite flexible for other domains,” adds Lokovic. “The way we represented the attenuation functions for shadows was interesting for Monsters Inc and movies after that but it has definitely been exciting to see how the varied uses of that have developed.”
Since the pair left Pixar to join Google (where Veach was pivotal in monetizing the search engine with Adsense), they have not worked on graphics in over 14 years. That meant the Oscar was somewhat of a shock. Apart from the odd grad student enquiry, the team were unaware of the progress that had occurred in recent time to their original research. “I have not been keeping track of how many papers had been building on our original work, so it was a real surprise to me when I was getting this award to go and see how many references there were to the paper we worked on,” says Veach.
“Both Eric and I have been out of the industry and so we have only seen glimpses of what’s going on,” notes Lokovic, “so it is now really exciting to see how people have picked it up, extended it and taken it into new and exciting directions, but the fact that it is being honored after all this time is certainly a surprise to me.”
 Veach and Lokovic were just the first of three awards presented at this year’s SciTech in relation to deep compositing. That illustrates how deep comp was an international development involving many key researchers and artists, something the pair was keen to point out. “I feel that we are very lucky that we have made the cut (here at the Oscars),” says Veach,” since deep compositing is the work of many people, and we just contributed one small part of that – so we are very happy that it has been recognized.”
Veach and Lokovic were just the first of three awards presented at this year’s SciTech in relation to deep compositing. That illustrates how deep comp was an international development involving many key researchers and artists, something the pair was keen to point out. “I feel that we are very lucky that we have made the cut (here at the Oscars),” says Veach,” since deep compositing is the work of many people, and we just contributed one small part of that – so we are very happy that it has been recognized.”
While the deep shadow maps research was almost immediately recognized for its ground breaking advances, the story of deep comp did not immediately then expand globally. It would be some seven to eight years later when computers had advanced sufficiently computationally that the original idea of deep shadow maps would be expanded upon to become the genesis of deep comp. And it would happen half way around the world, on the other side of the Pacific from Pixar’s Emeryville.
The story moves now to New Zealand and Australia
Colin Doncaster started working on what would become deep data while at Rising Sun Pictures (RSP) in Adelaide. At this early stage it was basically taking the deep shadow maps and using them almost directly but from the camera to record depth from the camera. He left RSP, took a year off and backpacked, but all the while the concept stayed with him. After a year he found himself at Weta Digital in 2007. “I was doing jack of all trades work on Avatar, lighting, R&D, pipeline, etc. and was playing around with the deep images as a side project,” he says. Actually Avatar was not Doncaster’s first project with Weta, “I was there for the Rings films, it was about 40 people when I started back in 2000. So part of the flexibility I had there during Avatar was due to relationships built during my initial tenure”.

Everything at this early stage was written in Shake as that was Weta’s main compositing tool. “I did a few tests and was trying to sell the idea to the Avatar supervisors,” states Doncaster. “At the same time FX TD Areito Echevarria was working on some The Day The Earth Stood Still shots where the volumetric cloud was engulfing trucks and stadiums. It was tedious because animation changes to the solid objects meant that everything needed to be re-rendered. He poked me about trying to use the deep workflow to speed up the process so it ended up being a bit of a skunkworks between Areito and myself to nut out the process.”
Those original Earth Stood Still shots were the first ones that were composited using deep compositing at Weta. Echevarria then went on to some commercial projects where he improved the process. “As we were still using PRMan’s deep shadows it was experimenting with compression and how much we could infer from the data etc,” says Doncaster. “The commercials were being comped in NUKE (one of the first projects) so the deep tools were ported over.”
Just around this time Weta was still going through look development on Avatar. James Cameron wanted Pandora to feel like it was under water and there was a lot of work going into volume fog renders to give that feel. “As the deep images had all the info we needed,” relates Doncaster, “I kicked out a deep fog tool that ended up in a shot that was the approved look. So that was a win for the deep comp workflow and what instigated its adoption for Avatar.” Once all of the elements were rendered with deep data the Weta pipeline was,” according to Doncaster, “shuffled around so we could render characters in separate passes and recombine etc.” But this was all happening in Shake, the NUKE deep pipeline had not been adopted in Avatar.

One of the cool side benefits for Doncaster was that Eric Saindon, a visual effects supervisor on Avatar, created libraries of particulate renders that compositors could use to mix into the volumes to enhance the underwater feel – “definitely a brilliant use of the tech,” says Doncaster. Mark Davies – another TD at Weta – also joined in the exploration and expanded on the deep fog tool by adding volumetric lighting – this would lead to the horses deep data work in Abraham Lincoln: Vampire Hunter.
About three quarters of the way through Avatar, Doncaster moved over to the Lovely Bones team. It was decided to have someone from the R&D team take over the development of the deep workflow. “So Peter Hillman jumped on the tech and cast his deft eye over the toolset,” explains Doncaster. “ODZ (OpenEXR-DeepZ) didn’t happen until after Avatar had delivered though it was created due to the resource demands created by the deep workflow.”
Dr Peter Hillman recalls that when Doncaster and Echevarria were originally working on deep comp, it was very much the deep shadow maps approach. “Effectively what they were doing,” he says, “was putting a light on the camera and shining it into the scene and seeing what it did, seeing what gets into shadow. And that tells you what depth different objects are and how opaque they are, and then a later development was to store color at depth.”
The later improvement still stores an array that is spread over depth, storing everything the camera can see in depth but also storing the color as well. This meant that a transmissive media could vary with texture, density, opacity and color. The original implementation was greatly affected by the fact that that is all the team could get from the renderer. “All we could get was the final color of all the objects combined together,” explains Hillman, “plus we knew what the alpha values were of all the objects separately, so we just did guess work of mixing the color in.”
This attempt at adding color occurred part way through Avatar. Before that, deep data was only used to try and calculate hold out mattes and thus speed up the process through the loss of successive hold out matte re-renders when any small thing changed. A simple muscle sim being revised would cause the hold out mattes to all be re-rendered prior to Weta’s deep comp pipeline. With the deep data they saw they could go further and deepenate the color render, “which is our name for that color scattering, and when the Foundry took over the development, they decided to call it deep recolor instead,” says Hillman.
From this color deep data, Weta went still further in Abraham Lincoln: Vampire Hunter, expanding the tools and making them more robust so a compositor could wildly change God ray directions or intensities – accurately – without just completely ‘faking them’. “That was developed for that show,” explains Hillman, “essentially being able to apply or change God rays into volume data. On Avatar we did have volume stuff – so we were rendering deep clouds, towards the end, and we have used that quite heavily since but most of the time we baked the shadows in.”
Since then the Weta pipeline has matured, and the tools have become more stable. The process of not baking in the lighting of the volumetrics was used again in the last Hobbit film – The Desolation of Smaug – where once again instead of committing to particular volumetric shadowing and lighting, the final decision was delayed or deferred to the comp team in NUKE as they finished several key shots of Smaug, for example. To be clear, the use of deep data is very widespread at Weta, but in most cases the Weta lighting team makes lighting decisions earlier in the pipeline to provide consistent and accurate looks. The newer ability of deep data to provide dynamic fully uncommitted volumetric shadowing only locked down in final comp is still done but just not as commonly. It is used when subtle variation may be required to enhance the filmmaker’s aims in getting right the final look and shot.

Weta used originally ODZ. Hillman says the studio considers ODZ and the new OpenEXR 2.0 to be “pretty much the same, even though they are not the same. We expected ODZ to be standard, but we are now migrating over to OpenEXR 2.0.”
In both ODZ and OpenEXR 2.0, for solid objects the format stores a deep value for each object at that pixel. There is no interpolation as there is a finite number of objects in that case. However, says Hillman, “when it comes down to volumetric data it is more efficient if you use an interpolation scheme (between values in the deep data array), then you can use fewer samples to represent your particle swarm or whatever.” For a film such as The Desolation of Smaug, the data compression is quite elaborate. TDs are offered a choice of different cutting edge data minimization tools they can use to reduce file size on particularly complex or elaborate volumetric environments.
Without compression, a rendered frame file with volumetrics could get to be hundreds of megabytes, but for Weta the standard approach always uses some sensible compression and/or interpolation. As a rough guide Hillman estimated that around 10:1 – as in 10 samples per pixel is about right for a normal scene without volumetrics. Of course in a scene with complex volumetrics it rises. But unless an object intersects the volume there is no need to store more than just one single value. “If you know in advance that the cloud you are rendering up in the sky has nothing flying through it then you just one render one value,” points out Hillman. The dynamic and flexible data type built into ODZ and Open EXR 2.0 is therefore key.
For very complex scenes such as the bridge attack in Rise of the Planet of the Apes, Weta needed to combine multiple 3D characters, live action cards and all with smoke and fog blowing across the Golden Gate Bridge. “One of the tricks we did for that was not doing CG renders for much of the volume,” says Hillman. “We were just doing sparse volumes, something we learned on Abraham Lincoln. All the dust hits from their feet hits etc were properly simulated cloud renders, which were relatively dense, but most of the fill was created interactively in NUKE and sculpted to have that nice look, and then you can tolerate much more samples as you are not reading in from disk. You are creating it live in the comp (in NUKE)”. (see below for the implementation of deep compositing by The Foundry)
Weta Digital compositor Robin Hollander explains deep comp in Rise of the Planet of the Apes.
While Hillman was effectively taking the base work and producing production tools inside Weta Digital, other work was happening just across the Tasman Sea, as Colin Doncaster discovered.
After Avatar and his time on Lovely Bones, Doncaster left Weta and joined Animal Logic in 2009 for Legend of the Guardians: The Owls of Ga’Hoole. By the time Doncaster got to Animal, Johannes Saam and Chris Cooper had built their own deep compositing prototype tools and tested them on a few shots in Australia. “They had implemented them all in NUKE and it was interesting to see what decisions they had made,” says Doncaster, “so it was a case of both ‘teams’ reaching the same conclusion at the same time.”
“So the work at Animal Logic was more iterating and experimenting,” adds Doncaster. “Jo built some great relighting tools and at that time the two of us (Chris ended up leaving shortly after I arrived) along with Daniel Heckenberg (who is one of the brilliant minds behind their Quill feather system) began looking at ways of improving the data structures involved. A lot of that dev was short lived as production demands took precedence.”
Saam worked very hard with Doncaster to promote deep comp, setting up a website and giving presentations at industry events. Interestingly, while Saam also was honored at the SciTechs this year, SIGGRAPH actually rejected Doncaster, Cooper, Heckenberg and Saam’s paper submission. This effectively denied a great chance for the community to learn of the evolving technology. Their rejected submission paper can be downloaded here. Ironically, by 2013, the Birds of A Feather SIGGRAPH panel Deep Compositing – What is the Right Workflow? was a packed meeting with contributions by Weta, Pixar, Side Effects, the RenderMan team and The Foundry.
Saam had been at RSP originally with Doncaster. “The idea started at RSP during Australia,” says Saam, “when were were doing deep hold out mattes but in shaders with RenderMan, not interactively in compositing, but we were already starting to do this kind of work but in a shader context, which is a trick that has been around in the RenderMan community for a little bit. Inspired by this work, Saam was keen to get a similar approach working in a compositing environment. When he got to Animal he started exploring deep comp with Legend of the Guardians: The Owls of Ga’Hoole which was released in 2010. Work was also done exploring it for an earlier pre-production period for a Mad Max sequel, but the film in that form did not continue and the film project went into turnaround.
Saam explained that from a rendering point of view, the technology was very much placing a light’s field of view to match that of the camera’s, but while that produced a deep data set it was not deep comp as we know it today. “It was just the next step,” he says. “All along it is built from what Pixar did.” As a camera tool or a compositing tool “it was a re-purposing of this kind of technology initially. It marks the start of a whole new era and I myself believe this is just the start of using it for its potential.”
Saam points to Weta’s work on relighting and what Animal did with generating accurate depth of field and relighting and regrading using deep color information as just the beginning. “It is probably just the start of a whole new set of tools that we (as an industry) can cook up that are not even designed yet,” he says.
There is still a difference between deep opacity and deep color, and issues of whether or not everything needs to be rendered with deep data, believes Saam, and yet he feels deep comp has now reached a point that it can be called a standard way of doing high end work. Even Saam does not turn it on for all the shots he is doing, especially if projects have very tight render budgets, but it is now a major standard tool like any other. “But due to the fact of what it does it can save major re-render times and if it is used in a smart way,” he notes. “But it is so good that it is now a standard part of NUKE so people can use it if they want. The end has not been reached and I think it will continue to grow in use.”

An example of the growth and adoption of deep data can be seen now in stereo conversion. Most of the high-end effects houses on a project with loads of say destruction and smoke – especially in a native stereo show – would consider a deep pipeline, but most of the stereo conversion facilities that might take that work to post-stereo convert a film are not currently using deep pipelines. There are a number of reasons for this, but using deep data or a version of it for stereo conversion is certainly a valid area of research moving forward.
What Saam likes about the approach of the SciTech Committee’s approach on deep data was that it acknowledges the evolution of ideas, the promotion of them and the use of the tools in production. The Academy did not divide up credit, so much as accept that this was an idea whose time had come and internationally and collectively companies published, promoted and succeeded in explaining an idea that might have died should just one company sort to patent and withhold its IP.
At Animal Logic, Chris Cooper had started work on deep comp before Saam even joined. In fact, Saam took over from Cooper’s work as not long after Doncaster joined, Cooper left to join first another FX company Dr. D Studios, and then moved on to join a high end R&D unit outside our graphics or effects industry. Saam would also follow to Dr. D before moving overseas when Mad Max in its original incarnation did not proceed.
Cooper got first got involved on deep comp after working on some complex shots in World Trade Center (2006) at Animal Logic. There was a sequence of shots of a corridor that Animal was doing all set within a shopping mall in the base of the tower. As part of that sequence, Cooper and the team had to explode concrete columns and create big plumes of dust. “During that production there was quite heavy physics simulation of debris and volume rendering,” explains Cooper, “and that was being done using a volume renderer that I had written.”
The volumetric ray marcher in-house tool was called Steam. It simulated particles inside Maya and then exported a cache (with position etc, and control of rotation). This allowed a particle cloud to be controlled by a fluid sim, and on each particle Cooper put a density function – akin to a digital ball of cotton wool. For World Trade Center shots, the team would run fluid sims down the corridor and drive a lot of particles with procedural detail that would be the cloud front as the collapse happened. It is often said necessity is the mother of invention and Cooper had to composite this cloud with a lot of debris. At Animal Logic at that time this was done with a traditional set of hold out mattes but it was very expensive in re-renders as every time the debris changed Cooper’s volumetric dust cloud and its hold out mattes had to be re-rendered.

“If the TD wanted to change the debris, just a fraction,” states Cooper, “the volumetric had to all be re-done. And that was not a cheap process, so that established the need.” When the film Australia came around, there were shots of cattle entering Darwin that Cooper wanted to try a new technique for. On Australia, the first unit shot with just a small number of real cattle and then wet down the dusty road. Animal would then add in extra cattle and digital dust. “That raised a bunch of challenges as we had to incorporate a bunch of live action cattle and digital extras,” says Cooper, “as realistically as possible within a computer generated dust cloud.” As the Steam ray marcher was an in-house tool, Cooper realized that he could actually output data along the ray – rather than just a final color value. So instead of just rendering with a hold out or hand generated roto within the volume render, “we could render the volume with minimum holds, just the ground plane for example and do a lot of the other hold outs in the compositing platform if we output deep data,” explains Cooper.
After Australia, Doncaster and Saam arrived at Animal and Cooper passed his work over to the others who took it further on Guardians. Animal at that time was using an in-house file format which their NUKE pipeline could read using special plugins that the studio had written. Cooper now works as a Software Engineer at NICTA, where he continues to push the capabilities of visualization in computer graphics.
Meanwhile, back in North America
Work on deep was not just being down in the Southern Hemisphere. During this time DreamWorks Animation (PDI) worked on deferred shading (Janne Kontkanen was also honored at the SciTechs for his contribution). Kontkanen is no longer at DreamWorks – like many other extremely talented artists and researchers he is now in San Francisco Bay Area, specifically at Google.

Kontkanen started in DreamWorks in 2007 and deep data was one of the first things he tackled. The whole DreamWorks development started with a bug report in early 2007. Yancy Lindquist (an FX TD on Monsters vs. Aliens) complained that a shot did not look as good as it should. “He complained that there was color leaking from behind a motion blurred object into the front of it that was not correct,” recalls Kontkanen, “and then I looked at it – thought about it for some time – tried a bunch of things. We knew about problems in the old compositing pipeline.”
Eventually it became clear that Lindquist wanted quality that their current pipeline could not deliver with standard 2D images. So Kontkanen started putting together a 3D comp file format that included depth data, and tried to also find a way of storing this data as efficiently as possible. “The fall of 2007, early 2008 we had tools we could use for deep compositing, but they were simple tools,” Kontkanen says, and also notes that he was inspired by the Pixar deep shadow maps research. But for DreamWorks their approach always stored color in their data, since that was the issue with the original bug report. This meant that when they flattened the image – using the simple command line tools they originally had – and took the result into DreamWorks’ 2D ‘Comp’ tool, the image looked correct and solved Lindquist’s problem. The original command line work was later expanded and incorporated much more fully into DreamWorks’ standard tools.
Above: watch Colin Doncaster, Johannes Saam, Areito Echevarria, Janne Kontkanen and Chris Cooper accept their award at the SciTechs.
Kontkanen only heard about the work of Animal Logic and Weta Digital at the same SIGGRAPH 2010 presentations, but he was still unclear on how the other teams were storing their data, compressing and saving it. After SIGGRAPH, Kontkanen started to explore how others were solving data storage. Originally he was focused on just image quality, but he then started to see how you could post-process the data and get extra benefits such as breaking volumetrics into smaller pieces and accurately recombining them later. Having a library of deep volumetric and fx clouds allows for great re-use, faster initial rendering and much more sharing of assets internally. “The explosions and stuff that we had in How to Train Your Dragon,” says Kontkanen, “we could not have done them without deep compositing. It is not only the compositing of atmospherics with hard surfaces but also the combining of multiple smaller fx together. At the time DreamWorks used an internally written renderer for both fx and hard surfaces, so generating deep data was easy to organize as the team solved the various issues.”

Given the huge file sizes they were creating and the disk budgets on projects at DreamWorks, Kontkanen turned a large amount of attention to how to better compress and store deep data. This was coupled by their work on high dynamic range images at the same time. Deep data and HDRs are big files “no matter how you end up doing them,” jokes Kontkanen.
The R&D team that was really the key in the development of deep images at DreamWorks since the beginning was: Thomas Annen (now at Apple), Mark Davis (DreamWorks Animation), and Patrick Kelly (now at Weta). “I feel that their names should be also on the award,” Kontkanen comments modestly, reflecting on just how much the team contributed and worked together. “I don’t feel like I deserve it! And I really appreciate DreamWorks putting my name on it. There are a lot of people who deserve it.”
As stated above, the initial push for better compositing came form Yancy Lindquist, who was the head of FX for Monsters vs. Aliens. “There were a lot of other amazing artists and developers pushing the boundaries of this technology,” says Kontkanen, “including Koen Vroeijenstijn, Brett Miller, Devon Penney and others. And I need to add that the management was excited about this technology since the beginning, including my manager Andrew Kunz, and director of R&D Andrew Pearce. Their support was critical too.”
Deep comp in NUKE
As the premiere film compositor, NUKE was the natural choice for Weta Digital to approach about deep compositing. Besides, Weta Digital and The Foundry have a long relationship spanning MARI and many other joint research ventures.
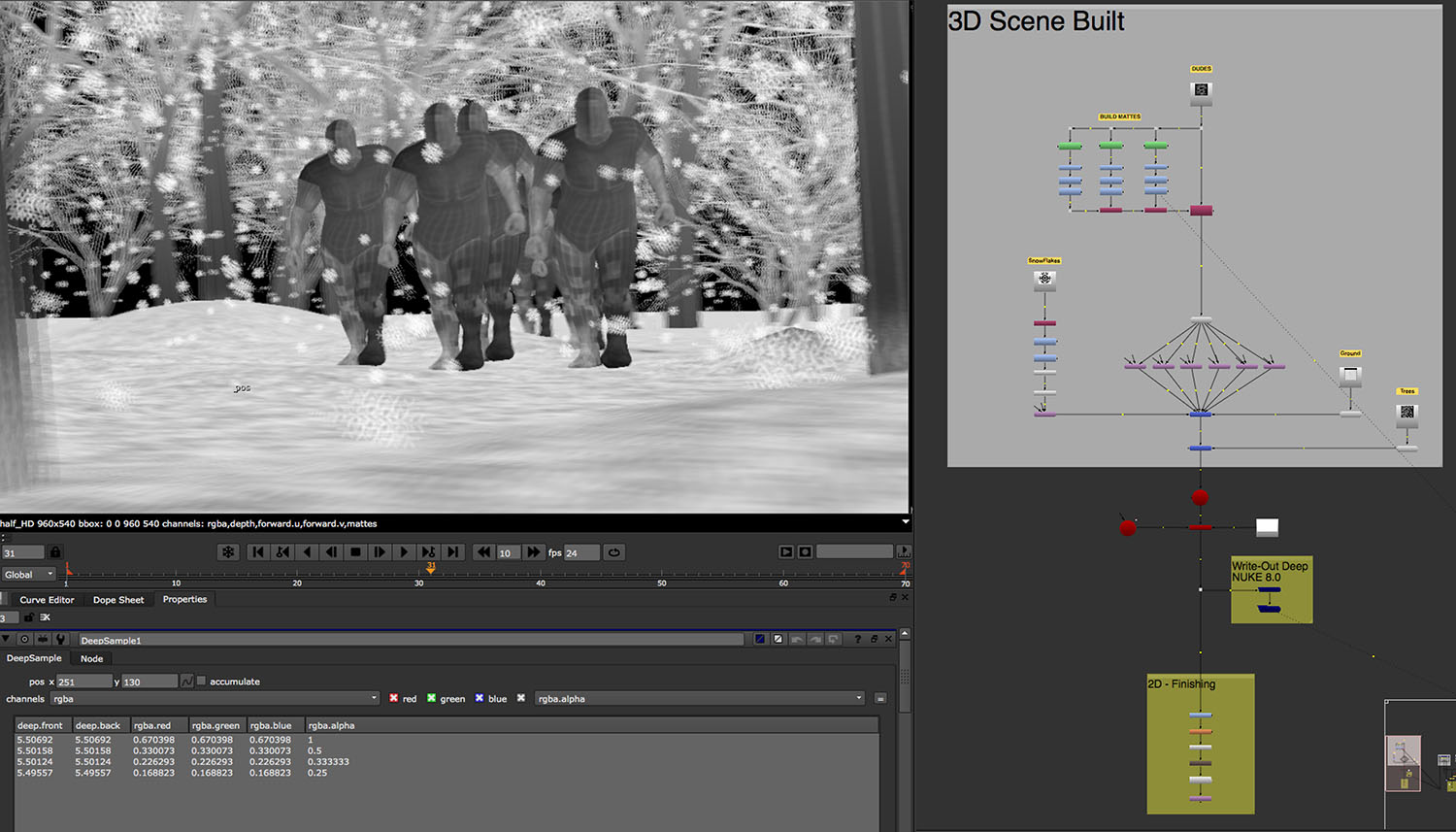 The initial implementation of deep comp had actually been in Shake. Following the Apple Shake shutdown, many companies had access to the Shake source code and Weta was one of these, so it followed that the team would look to test it in Shake first. But Weta’s Shake was never a long term option and so NUKE was the ultimate choice.
The initial implementation of deep comp had actually been in Shake. Following the Apple Shake shutdown, many companies had access to the Shake source code and Weta was one of these, so it followed that the team would look to test it in Shake first. But Weta’s Shake was never a long term option and so NUKE was the ultimate choice.
Jon Wadelton, NUKE Product Manager at The Foundry was one of the first people from the company to explore the work that Weta’s Dr Peter Hillman had earlier demo’d with Shake to The Foundry’s Matt Plec in 2008. Initially, Plec explained that deep was not on The Foundry’s radar, but Hillman was very keen for The Foundry to implement Deep in NUKE. So using just the API and NUKE itself, Hillman implemented a first solution himself. “That’s when we got much more interested and went much more in-depth on what was happening and how it worked,” says Wadelton. “It has been a partnership,” adds Hillman, “in terms of sharing ideas and working together.”
Colin Doncaster and Joannes Saam also knew Wadelton, and independently they approached Wadelton not long after also keen to explore a deep comp pipeline built on the principles of the original deep shadow maps. While it was Hillman who had the most robust and production ready implementation, and the Foundry licensed tech from Weta, Wadelton also consulted with Doncaster and Saam during The Foundry’s implementation phase.
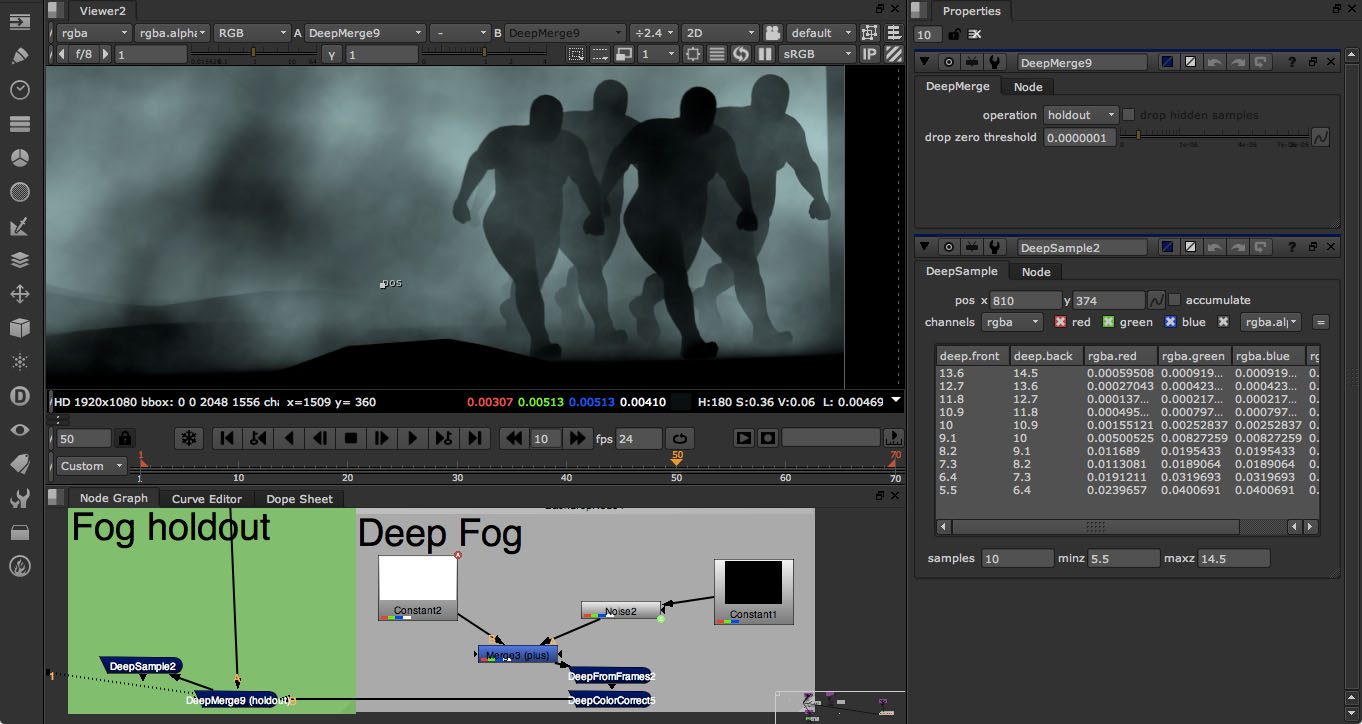 Actually, the very first Foundry implementation in mid-2011 was long before OpenEXR 2.0, which only came out of Beta last year in 2013. OpenEXR was first developed by ILM and is now maintained by key VFX players such as Weta Digital, Pixar Animation Studios and Autodesk. OpenEXR 2.0 has deep data support based on Weta’s ODZ deep data format. “When we first started the deep compositing stuff,” says Wadelton, “we were inspired by Weta and by Peter Hillman and what he did with his version of the deep composting in NUKE, which had nothing to do with us, except we helped him with the NUKE API. He built it on top of the existing NUKE, but later on we decided it was a good idea to have this compositing system so we built our own from the ground up – inside NUKE – with a C++ API and with proper deep buffers and so on. Which was the start of it.”
Actually, the very first Foundry implementation in mid-2011 was long before OpenEXR 2.0, which only came out of Beta last year in 2013. OpenEXR was first developed by ILM and is now maintained by key VFX players such as Weta Digital, Pixar Animation Studios and Autodesk. OpenEXR 2.0 has deep data support based on Weta’s ODZ deep data format. “When we first started the deep compositing stuff,” says Wadelton, “we were inspired by Weta and by Peter Hillman and what he did with his version of the deep composting in NUKE, which had nothing to do with us, except we helped him with the NUKE API. He built it on top of the existing NUKE, but later on we decided it was a good idea to have this compositing system so we built our own from the ground up – inside NUKE – with a C++ API and with proper deep buffers and so on. Which was the start of it.”
The Foundry actually ended up licensing the Weta implementation, but more as reference than using the code directly, since Hillman’s version sat effectively on top of NUKE. The Foundry built it into NUKE. “It was a bit hairy in the maths in deep,” admits Wadleton. “When you are thinking about say straight color correction with a normal 2D image, it is quite straight forward, you just go through all the pixels and treat them all the same and then you put the result on the screen. In deep with our first implementation it did all of that with the deep data, but if you say do a lift or a similar operation, you can’t treat it the same way. You actually need to do something more volumetric. We had to learn quite a bit as we went along.”
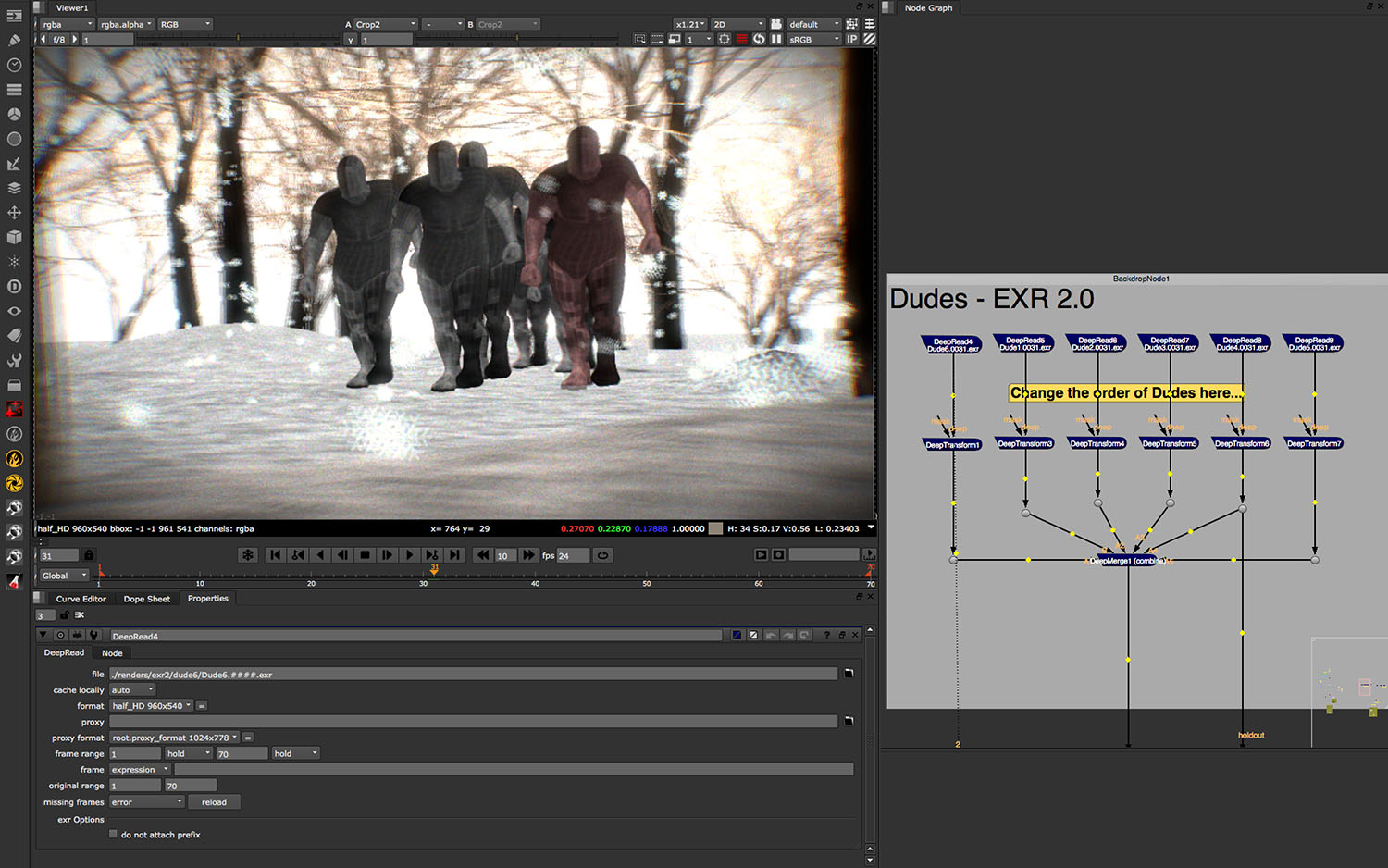 Thus, the first version of The Foundry’s deep implementation in NUKE 6.3 only ‘half worked,’ says Wadelton. The team re-wrote it entirely for the next release of NUKE – version 7 – which came out in late 2012. They also included a proper hold out matte. Prior to version 7 a compositor had to flatten an image to make a hold out matte, now one can make a proper deep hold out matte, with a ‘deep volume’.
Thus, the first version of The Foundry’s deep implementation in NUKE 6.3 only ‘half worked,’ says Wadelton. The team re-wrote it entirely for the next release of NUKE – version 7 – which came out in late 2012. They also included a proper hold out matte. Prior to version 7 a compositor had to flatten an image to make a hold out matte, now one can make a proper deep hold out matte, with a ‘deep volume’.
In version 8 of NUKE this was extended to have native deep data from NUKE’s scanline renderer directly. This new scanline renderer supporting deep has been widely praised and several current deep data pipeline TDs have praised the move in comments to fxguide, as being a huge improvement to the NUKE implementation. This allows one to insert elements from say NUKE’s Particles system into say a deep data rendered element from say RenderMan or Houdini’s Mantra. Prior to version 8, while one could generate deep data inside NUKE, you could not produce a deep render from deep data. Even without the 3D render, NUKE was still very valuable and from the first v6.3 of NUKE’s implementation, 3D deep data could, for example, be visualized by converting it into a point cloud (DeepToPoints node). “It was important to have that visualization in from the outset so you could place cards, even without the 3D render we have in v8, it is still useful to generate cards or to make holdouts, just using a depth map,” says Wadelton.
At The Foundry in the UK, the development work was spearheaded by Abigail Brady who developed the core NUKE deep comp architecture, including the caching, integration with the viewer, deep C++ APIs, and volumetric alpha merge algorithm. “All of the nodes except DeepHoldout were coded by Abi for Nuke 6.3”, notes Wadelton. “So this included DeepCrop, DeepReformat, DeepSample, DeepTransform, DeepMerge (combine), DeepToPoints, DeepFromImage, DeepColorCorrect, DeepToImage, DeepFromFrames, DeepRecolor, DeepExpression, dtex DeepRead. and exr2 DeepRead.”
 Jon Wadelton himself wrote DeepHoldout for version 6.3 of NUKE and some improvements to the toolset for NUKE 7. These included DeepMerge (holdout mode), DeepColorCorrect2 (being able to adjust alpha and ‘correct’ math for lift operations), Deep multichannel support for DeepColorCorrect / DeepRecolor / DeepToImage EXR2 deep reader / dtex Reader and EXR2 deep writer.
Jon Wadelton himself wrote DeepHoldout for version 6.3 of NUKE and some improvements to the toolset for NUKE 7. These included DeepMerge (holdout mode), DeepColorCorrect2 (being able to adjust alpha and ‘correct’ math for lift operations), Deep multichannel support for DeepColorCorrect / DeepRecolor / DeepToImage EXR2 deep reader / dtex Reader and EXR2 deep writer.
DeepRecolor (target input alpha mode) with alpha rebalancing algorithm was done jointly with Chris Horvath at Pixar. Deep volumetric color merge algorithm (Nuke 6.3 did not merge color volumes correctly).
They were helped by Pierluigi Garaventa who did the ScanlineRender Deep Output that was released in NUKE 8. And the ‘product design’, i.e. what nodes The Foundry should make and what they would be called etc, was a combination of Matt Plec and Jon Wadelton. It was not trivial to implement this. The V8 implementation has mutli-sampling, motion blur and other advanced features that are mathematically correct.
Data size is always an issue when discussing deep pipelines. Deep data can be very large. Looking forward, The Foundry is looking at new approaches to compressing deep data. One of the things the team is looking at is having the compression done later in the process, so a more informed compression algorithm can be used. Poor compression will introduce artefacts, one almost needs to use the data to understand how best to compress the deep data. Perhaps NUKE will be extended to allow the artist to compress after the data is first evaluated and used and not when the render is done and the file is first written. The issue is both one of perception and reality. Some companies have stayed away from deep pipelines due to concerns over data size. Yet deep data can be very useful when not handling vastly complex volumetrics and thus avoiding all deep data since just some shots are data heavy, according to Wadelton who thinks as more people understand the benefits and who have the correct implementation, the wider deep comp will become. “I think it makes sense to render a lot of your elements in deep, even if they are not volumetrics. It saves time, especially with re-lighting and moving elements.”
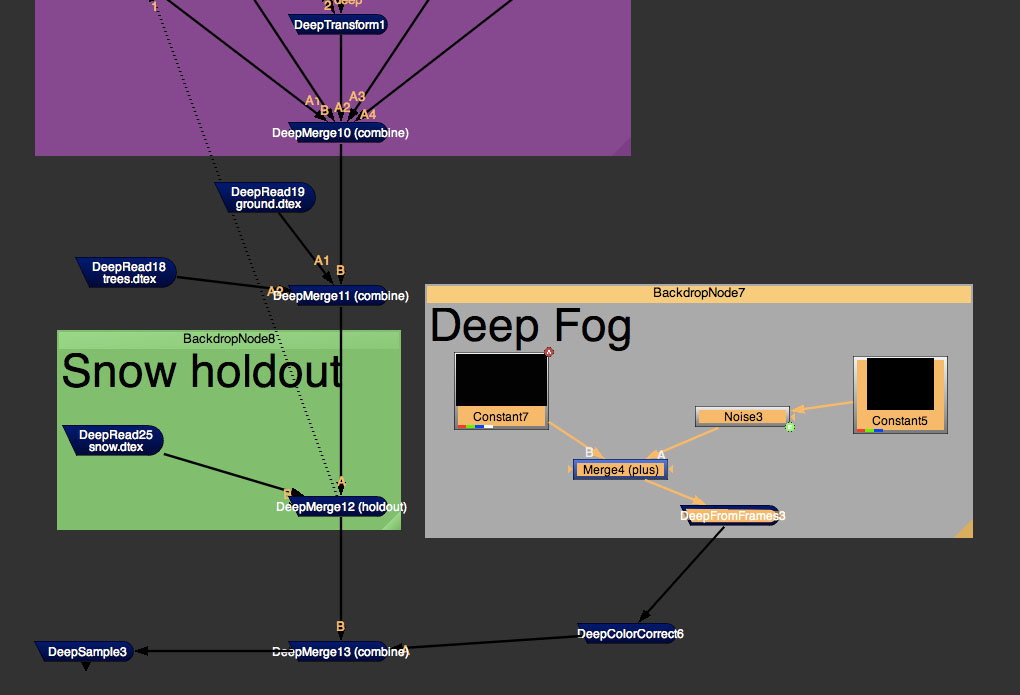 At the moment NUKE is the only product at The Foundry supports deep data, the company must be considering it for the MODO 3D renderer. Ocular, The Foundry’s stereo tool is primarily a live action tool that generates a disparity map. It does not currently support deep data but it would be another possible area of applying deep data to help with stereo conversion. “It is not something we are doing right now,” says Wadleton. “It would be a research project to work out how we might use it.” If deep data did become widely adopted throughout the industry, one could imagine the people behind stereo conversion pipelines would look at ways they might use deep data. For now deep is widely adopted at the high end and spreading out to more general purpose pipelines.”
At the moment NUKE is the only product at The Foundry supports deep data, the company must be considering it for the MODO 3D renderer. Ocular, The Foundry’s stereo tool is primarily a live action tool that generates a disparity map. It does not currently support deep data but it would be another possible area of applying deep data to help with stereo conversion. “It is not something we are doing right now,” says Wadleton. “It would be a research project to work out how we might use it.” If deep data did become widely adopted throughout the industry, one could imagine the people behind stereo conversion pipelines would look at ways they might use deep data. For now deep is widely adopted at the high end and spreading out to more general purpose pipelines.”
Wadelton commented to fxguide just prior to the SciTech awards that, “deep compositing has been an enabler for artists to create some of the most extraordinary visual effects sequences put to film. We are indebted to those individuals who had the creativity to both invent and adapt existing technology to create this technique. Without them these sequences might never have come to life.”
Extending on from NUKE
Today Colin Doncaster is with a small company Peregrine Labs that makes specialist high end effects tools. One of those is defocus tool Bokeh. That tool was used by FUEL VFX for Prometheus. Compositing supervisor Sam Cole explained its key use, when fxguide spoke to him back in 2012: “In all of our renders that were coming out ‘deep’, they were coming out sharp so we were able to match the focus later in comp with Bokeh. Inside the Orrery (in the ship) we wanted to have full control over the exact shape of the bokeh and the slight chromatic searing that you would get on those discs. And that allowed us to do it in deep. We’d plug in the cameras, plug in the T-stop from the on-set sheet and that’s where we start. It was fantastic for that. A lot of the iterations – we would have been really stuck without being able to iterate with that, especially for the Engineers where all the points are coming off the ground in the storm that are coming off them.”

Avoiding hold out mattes and re-rendering is only part of the motivation for wanting to adopt a deep comp pipeline. Many companies are finding other optical effects are better simulated with deep data, just as FUEL did on Prometheus. Wadelton agrees: “One of the reasons people want to adopt a deep pipeline is so that they can do correct depth of field in post,” he says. The Foundry admires the work of Doncaster and has considered doing something like Bokeh in NUKE directly. “We’d like to do a correct depth of field with deep data, ’cause obviously you have much more information on some of the pixels you would not have had before so you can do a much better job at defocusing, and Colin’s plugin is used widely across a lot of different facilities.”
Peregrine Labs’ Bokeh has support for deep data, for both color and depth as well as traditional Z depth support. It can vary lens shapes thus simulating lens aperture blades correctly. It provides accurate lens blooming, spherical and chromic aberration simulation and is driven by typing in the f-stop and focal length settings to match the real world lens you are trying to simulate. It also importantly works with NUKE’s 3D camera input.
Peregrine Labs is only two people. “Kirsten is our producer and I’m the development team,” states Doncaster. Peregrine Labs has created its own deep toolset. Bokeh is a part of this and “although initial versions of Bokeh were ductaped into NUKE it has since evolved on its own as the way deep works in NUKE is different from how we deal with it in our deep engine,” he says.
Watch a further breakdown from the Orrery sequence.Bokeh models very accurately what lenses do, and with the additional data stored in a deep comp pipeline is able to simulate real lenses with exceptional accuracy in a way a barrel rack defocus of simple flat 2D can’t do. “Besides our deep support,” relates Doncaster, “I’ve tried hard to make sure the real world lens simulation is accurate to the degree of actually deriving slightly different equations than commonly used. Cooke published a great paper on lens construction and its effect on Bokeh which was a valuable resource.”
The deep engine that Peregrine Labs has can be considered more experimental in that Doncaster is trying to solve a lot of the very complex problems inherit with deep data. Deep compositing has two components, the data and how to use it. “There has been a lot of work on the data representation and how it’s stored on disk,” says Doncaseter. “Peter Hillman and Weta really made working with deep data possible with the ODZ format and rolling that into EXR. And having both Weta and ILM behind the format helped the rest of the industry sit up and take notice.”
Doncaster believes there is still a lot of thinking that needs to go into how to work with the deep data, and whether or not the deep data disk representation is the best way of storing it in memory. “Deep data isn’t ideal for a lot of the GPU based image processing tricks,” he notes. “Convolutions are hard as there are disparate samples in neighboring deep pixels etc. So this is what I’ve been focusing on. At some point these may be available outside of Peregrine if there’s enough interest/demand – but I’d like to get it right first.”
The Blue Umbrella

To close the loop from the original deep shadow maps paper at Pixar, while there are many films today that use deep comp, there is one film that has shown how creatively deep comp can help a story and that is Pixar’s short The Blue Umbrella directed by Saschka Unseld. The film has beautiful imagery all with heavy use of atmospherics and environmental fx animation. Colin Doncaster, who did not work on the film, commented:
“Pixar’s Blue Umbrella is a great example of this (deep data). You can’t really point at a comp that has used deep for holdouts/mattes and see how much better it looks – but if you can defer creative decisions about depth of field without fighting with edge artifacts (ie. fur and traditional Z depths) then that’s a win.
Click here to see our fxguidetv interview with Christophe Hery of Pixar to learn more about the film in which a live action aesthetic – and tools such as deep comp – helped bring this wonderful story to life.
Wow. That’s what I would call an in-DEEP article!
Pingback: 3D Production Pipeline: Lighting, Rendering & Compositing | Luke Jarrett
Pingback: The Art of Deep Compositing | CGNCollect
Pingback: The visual effects magic of ‘The Force Awakens’ | Rapid Notes
Pingback: 3D Production Pipeline, Continued 2 | Leif Eriksson Animation
Pingback: deep compositing | Abigail Brady
Pingback: Research Blog – Rendering for Compositing | Kynan STW Blog
Pingback: FX artists – Olly Crawford
Pingback: ANM230 Weekly Blog – Jacob Duncan Blog