At GTC, NVIDIA Research produced 3D scenes from 2D photos using ultra-fast new GPU inverse rendering. This is approach is one of the first to combine ultra-fast neural network training, NeRF, and rapid rendering. NeRF stands for neural radiance fields. NVIDIA calls this new implementation Instant NeRF. At GTC this new approach is shown is achieving more than 1,000x speedups in some cases. The Machine Learning requires a few seconds to train on a few dozen still photos, plus data on the camera angles they were taken from, and then the resulting 3D scene can be rendered within tens of milliseconds.
For a long time, NeRF was expensive to train, hence much research was focused on reducing the necessary GPU time required to fit a scene. Despite iterative improvements, the issue remained largely unsolved, until recently. The first NeRF models rendered crisp scenes without artifacts in a few minutes, but the original process took hours to train. The principle NeRF is to sample ‘5D’ coordinates (location and viewing direction) – along camera rays. Feeding those locations into a multilayer perceptron (MLP) to produce a color and volume density model. Using classical volume rendering techniques this volume data can be converted or rendered into an image with view-dependent RGB color. It is this last point that really provides the final high-quality finishing touch.
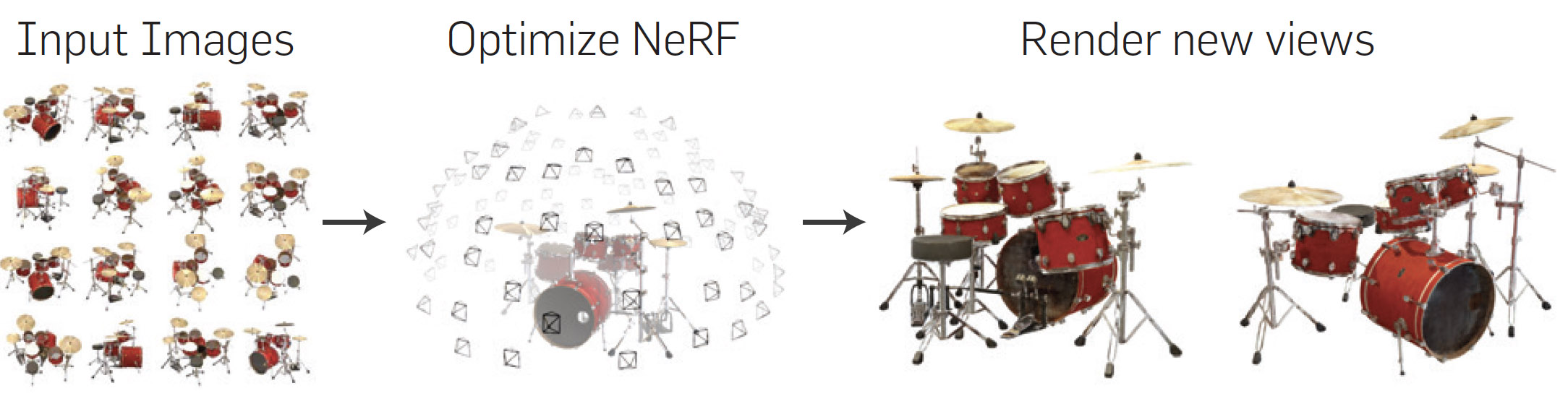
In Jan 2022 Instant Neural Graphics Primitives with a Multiresolution Hash Encoding was published by Thomas Müller et al and it was built on NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis by Ben Mildenhall et al (2020). Neural graphics primitives using fully connected neural networks, can be very costly to train and use. Thomas Müller and his co-authors recently published new versatile input encoding approach uses a smaller network without sacrificing quality. It reduces the number of floating-point and memory operations and works extremely well on a single CUDA GPU.
The small neural network works with a multiresolution hash table of feature vectors ( optimized through stochastic gradient descent). The multiresolution structure makes for a simple architecture that is trivial to parallelize on an NVIDIA card. At GTC Thomas Müller showed an iconic photo of Andy Warhol taking an instant photo and turning it into a 3D scene. The technology behind the demo is the fastest neural radiance fields (NeRF) model to date and can achieve more than 1,000x speedups.
The training of the small neural network works to reconstruct the scene by predicting the color of light radiating in any possible direction, from any point in the 3D space. The technique can even work around occlusions when objects are blocked by obstructions.
Thomas Müller is a senior research scientist at NVIDIA, working on the intersection of light transport simulation and machine learning. Before joining NVIDIA, Thomas obtained his Ph.D. in 2019 at ETH Zürich, where he collaborated with Disney, leading to several awards and patents in the offline rendering world. The resulting algorithms were implemented in multiple production renderers, including Pixar’s RenderMan and Walt Disney Animation’s Hyperion.
“If traditional 3D representations like polygonal meshes are akin to vector images, NeRFs are like bitmap images: they densely capture the way light radiates from an object or within a scene,” says David Luebke, vice president for graphics research at NVIDIA. “In that sense, Instant NeRF could be as important to 3D as digital cameras and JPEG compression have been to 2D photography — vastly increasing the speed, ease and reach of 3D capture and sharing.”

Instant NeRF could be used to create avatars or scenes for virtual worlds, to capture video conference participants and their environments in 3D, or to reconstruct scenes for 3D digital maps. The NVIDIA demo was developed using the NVIDIA CUDA Toolkit and the Tiny CUDA Neural Networks library. Since it uses a small lightweight neural network, it was trained and ran on a single NVIDIA GPU using NVIDIA Tensor Cores. Beyond NeRFs, Thomas Müller made the point that this input encoding technique could also possibly be used to accelerate multiple AI challenges including reinforcement learning, language translation, and general-purpose deep learning algorithms. “We have demonstrated that single-GPU training times measured in seconds are within reach for many graphics applications, allowing neural approaches to be applied where previously they may have been discounted,” – Müller et el (2022).
This work may accelerate the use of neural primitives for modeling and could become a powerful tool in real-time production for creating photorealistic imagery. It is important to note that while this is incredibly impressive, it does not produce temporally consistent geometry or segmented, rigged, or isolated geometry. It does however offer the next generation of researchers an amazing opportunity to build from this to tackle these next stages of scene reconstruction. It does immediately offer visual effects teams an incredible spatial reference to use in animation and effects.