 At the Adobe Summit in Las Vegas last Wednesday, before an audience of more than 10,000 professionals and data scientists, Adobe CEO Shantanu Narayen and NVIDIA CEO Jensen Huang spoke about how AI and machine learning are adding capabilities to Photoshop and other Adobe applications such as Premiere and Character Animator.
At the Adobe Summit in Las Vegas last Wednesday, before an audience of more than 10,000 professionals and data scientists, Adobe CEO Shantanu Narayen and NVIDIA CEO Jensen Huang spoke about how AI and machine learning are adding capabilities to Photoshop and other Adobe applications such as Premiere and Character Animator.
In the lead up to NAB in Vegas, Adobe has released updates to many of the Creative Cloud Apps. These include even more examples of Adobe applying Machine Learning (ML) and AI approaches to their creation tools.
At the Adobe Summit the two company leaders also spoke of NVIDIA’s latest ray tracing tools. These tools use ML in noise reduction to produce faster final results. Full 3D rendering remains the missing part of the Adobe creative suite. It is almost odd that such a graphics based company as Adobe does not already have a set of professional 3D rendering and animation applications, perhaps this indicates that that may change in the future?
In a busy news week for Adobe they also released a research paper using deep learning to produce professional quality matte channels. Clearly both companies are now taking advantage of the massive gains in image recognition and image processing occurring in AI. This research area remains one of the most successful applications of deep learning approaches in the AI landscape.
Adobe and NVIDIA announced a strategic partnership to enhance their AI and deep learning technologies. The companies will work to optimize the Adobe Sensei AI and ML framework for NVIDIA GPUs. The collaboration will speed time to market and improve performance of new Sensei-powered services for Adobe Creative Cloud.
Adobe and NVIDIA have worked together for more than a decade on a broad set of Adobe’s creative and digital experience products. This includes Sensei-powered features, such as auto lip sync in Adobe Character Animator CC and face aware editing in Photoshop CC(see below), as well as cloud-based AI / ML for image analysis and enhancement using Adobe’s stock image library.

As mentioned, Adobe is interested in NVIDIAs ray tracing shown recently at GDC in San Francisco. Huang at the NVIDIA’s GTC conference (right after GDC) showed the Quadro GV100 with Nvidia RTX Technology. This is made up of four Volta chipsets, or a $68,000 computer that is meant to replace the current computers to render graphic images and complex light shading in real-time. Huang said that a traditional “render farm,” like those used by Hollywood studios for computer graphics scenes, uses about 280 dual CPU servers and about 168 kilowatts of energy. Huang said that this could be replaced by 14 Quadro GPU servers that use only about 24 kilowatts of electricity. The significance is not only the power reduction but the associated air conditioning costs of cooling larger (and hence hotter) computer render farms. It was this Quadro GV100 that powered the EPIC real time ray tracing demo at GDC (see below).
https://www.fxguide.com/featured/epics-unreal-real-time-ray-tracing-gdc-day2-part-2/
While GPU rendering is computationally heavy, so too are these new AI applications that Adobe is championing. Huang also introduced the “world’s largest GPU,” the DGX-2, a massive chipset marketed as a supercomputer that weighs in at 350 pounds. It is designed for deep learning and AI applications.

The chipset is 10 times faster than the company’s DGX-1 and will be available in the third quarter for a staggering $399,000. “We are all-in on deep learning,” Huang said, adding that while computing power is growing exponentially, the growing computing power needed for deep learning is growing at double that rate. ”This is some new type of computing.”
Matte Generation Research
Adobe’s researchers have long been working on ways of isolating and matting out parts of images. Most professional approaches have relied on green or blue screen keying, but this has steadily given way to increasing use of semi-manual rotoscoping tools. While such tools are getting smarter and deploying such innovations as IK models and complex new shape deformations, Adobe’s team still seeks a generalised object isolation tool. They believe that in order to generalize auto extraction to natural images, matting algorithms must move beyond using color as a primary cue and leverage more structural and semantic features. In this newly published research paper, they show that a neural network is capable of capturing such high-order features and applying them to compute improved matting results. Their experiments seem to show that they can not only out perform prior methods, but also generalize the approach to most real images.
However, the paper is heavily bias to still images. Moving matte generation requires temporal cohesion to avoid distracting flicker and sparkles that defeat the effect, (although it did sample frames from video clips).

The new research paper uses a set of test images from alphamatting.com which were set up as part of a 2009 paper at the Conference on Computer Vision and Pattern Recognition (CVPR), called A Perceptually Motivated Online Benchmark for Image Matting. These test images are very high resolution ‘difficult’ images with fine detail and transparency. The publicly available16bit linear RGB images contain such complex artifacts as plastic bags, fur and hair.
The new research work is the product of Adobe research, Beckman Institute for Advanced Science and Technology and the University of Illinois. The approach works in two parts. First, there is a deep convolutional encoder-decoder network that takes an image and the corresponding trimap as inputs and predict the alpha matte of the image.
The second part is a small convolutional network that refines the alpha matte predictions of the first network to be more accurate and have sharper edges. In addition, the team also created a large-scale image matting database including 49,300 training images and 1000 testing images. This was done as deep learning needs training data and the alphamatting data set, while useful for testing, is only 27 training images and 8 test images. Most of the test images are real objects in front of another image on a monitor, and not natural scenes. Hence most images are indoor lab scenes, with indoor lighting and with no humans or real animals. As deep learning is bounded by its training data, this biased set incentivizes solution to fit to this particular collection of data (and not real world images from production).
Most current algorithms approach matte generation as largely a color problem. The standard approaches include sampling foreground and background colors and solving between them, informed by the choice of the matting colour (spill). This often leading to low frequency “smearing” or high-frequency “chunky” artifacts even when this colour approach has been tried with the addition of deep learning methods. The Adobe method does not work off a ‘matte colour’.

Instead of relying on color information, the new approach can learn the natural structure that is present in alpha mattes. For example, hair and fur possess strong structural and textural patterns. Other things requiring matting (e.g. edges of objects, regions of optical or motion blur, or semi-transparent regions) almost always have a common structure or alpha profile that can be expected. While low-level normal approaches will not capture this structure, deep networks are ideal for finding it. Among the many technical submissions to alphamatting.com since it started, this new Adobe solution achieves the highest score yet on the alphamatting.com challenge scorecard.
The Matte refinement stage is needed as while the first stage produces a good matte, but the team found that the alpha could be sometimes overly smooth. Therefore, they extend their network to further refine the results from the first stage. This extended second network usually predicts more accurate alpha mattes and sharper edges.

A key reason for the success of the Adobe method is the network’s ability to learn structure and semantics, which is important for the accurate estimation of alpha matte when the background scene is complex or the background and foreground colors are similar.

For example, above the “Troll” image has very similar colors of the hair and the bridge. While below it, the “Doll” example has strong textured background. The best results of previous methods all tend to fail in these examples, and have very obvious mistakes in these hard regions. In contrast, the new Adobe method directly learns object structure and image context. As a result, their method not only avoids the similar mistakes made by other methods but also provides more detail in the matte.
To make sure this was more than just test results in a lab, Adobe used real images and then had normal people (users) state their preference for the results. In this user survey, more than 4 out of 5 users preferred the new Adobe method over all other the prior approaches.
It is unknown when this technology will actually ship in Photoshop, but with such strong results, both this static keyer and a moving keyer for Adobe Premiere/AfterEffects must surely be planned for release in an upcoming version of the Creative Cloud Apps.
Paper by Ning Xu, Brian Price , Scott Cohen , and Thomas Huang.
Photoshop
Released a while ago, Adobe pointed to the Face aware tools in Photoshop as an example of deep learning computer vision already at work in Photoshop. These tools are not new, but they show how the Adobe Sensei can detect faces and parts of faces for computer assisted facial editing.
Premiere Pro
In Premiere Pro CC editing software, Adobe has introduced a Color Match feature, powered by its AI engine Adobe Sensei. Color Match is able to take the color and light values from a reference image and then apply them as editable color adjustments to the current shot, all while intelligently adjusting for skin tones. The program also uses the Sensei-powered face recognition by default to aid in matching and grading.
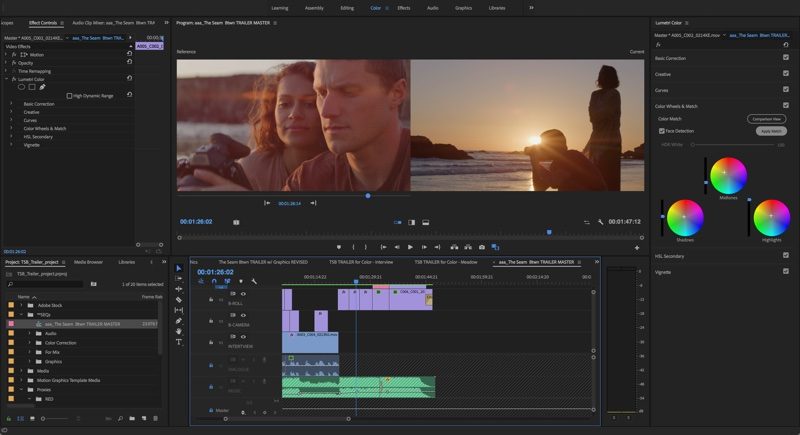
With Color Match, it takes just a few clicks and adjustments to match the colors of various video clips. For broadcast-quality content, the Video Limiter ensures color grading adjustments meets broadcast standards.
According to Adobe, from Hollywood films to Sundance Indies and premium television programs, a growing number of professional editors are using Adobe Premiere Pro CC to bring their stories to life. Projects that premiered this year include The Florida Project, The Square, Only the Brave and 6 Below; indie hits RBG, Clara’s Ghost and Search; and award-winning series MINDHUNTER and Atlanta.
Also new in AE…
Stacked behaviors and effects in combination with timeline-based animation are now easier to reuse. This allows the use of multiple variations of a single composition via the new Master Properties. An artists can apply changes to individual effects across multiple versions of a composition with a single adjustment using the new Master Properties.
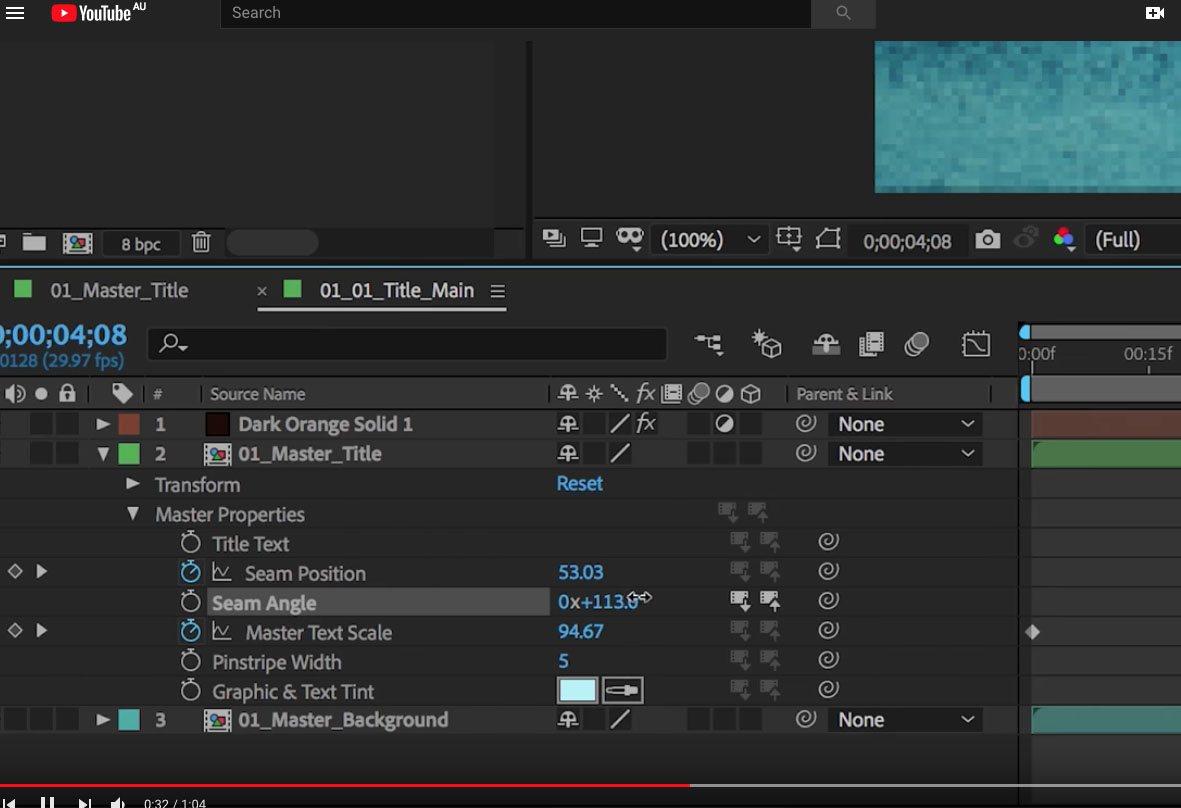
The ever growing Character Animator application has gained further improvements. It is now easier to create characters with the new option to drag layers from the Puppet panel into the Triggers panel to refine existing behaviors or create new ones. This program, which started as an experiment is growing into a very real tool for 2D stylised animation.
While the Matte/Alpha isolation research above is yet to be included in a product, the other tools are all now released and able to be immediately downloaded from Adobe.