The NVIDIA GPU Technology Conference (GTC) opened on Tuesday, with the keynote by NVIDIA CEO Jen-Hsun Huang. The presentation had several points of interest to the vfx and post community, and we highlight those in this recap.
The conference has grown considerably over the years, a reflection of the increasing use of GPU processing. For the vfx and production community, this tech is has become an incredibly important part of the process — one could argue critical part — and its why fxguide is covering the event. This holds especially true for NVIDIA GPUs, being widely adopted across numerous industries. The conference itself has also grown in size and scope, with tracks in industries from design to medical, entertainment & media to finance. This is a high level professional conference for anything NVIDIA GPU.
But we focus on the media and entertainment industry at fxguide, so that’s what we’ll cover here. There are some incredibly positive announcements regarding where NVIDIA is planning to take their GPU architecture. It’s not surprising that our industry is the second largest segment in NVIDIA’s professional graphics business.
NVIDIA Keynote
Our coverage starts with announcements from the Keynote event held Tuesday, March 25.
GPU Roadmap

One of the interesting aspects of the keynote has always been getting a bit of insight into where NVIDIA is planning on heading with their tech and this year was no exception. With each new generation of architecture, the company aims to improve the GPU platform and remove bottlenecks to performance. This future can’t come fast enough for the vfx industry, as issues such as memory and bandwidth impact the ability to widely deploy GPUs for rendering and other tasks. To that end, Huang introduced their plans for the “Pascal” architecture, targeted for a 2016 release date (“Kepler” is the current release and “Maxwell” aims to arrive later this year).
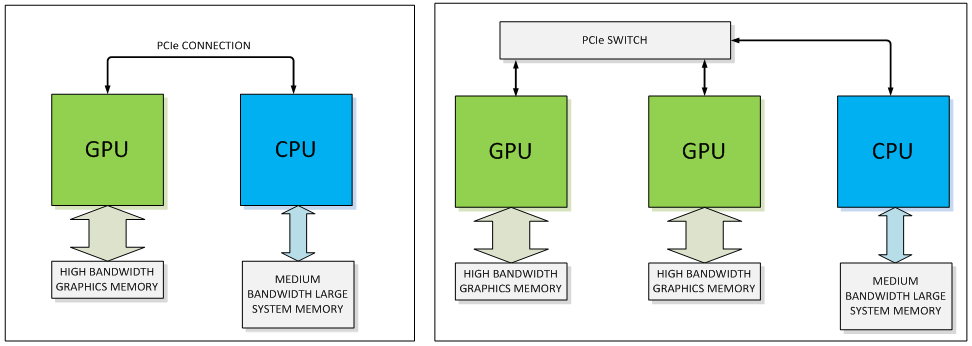
While PCIe is fast, this bandwidth doesn’t measure up when compared to the speed at which the CPU can access memory. This bandwidth can become even further limited if systems use a PCIe switch, which can occur in multi-GPU systems. NVLink is a new high-speed interconnect for CPU to GPU and GPU to GPU communication, intended to address this problem. Co-developed with IBM, NVLink can hit speeds of between 80 and 200 GB/sec of bandwidth, providing very fast access to system memory. It is also more energy efficient in moving data than PCIe.
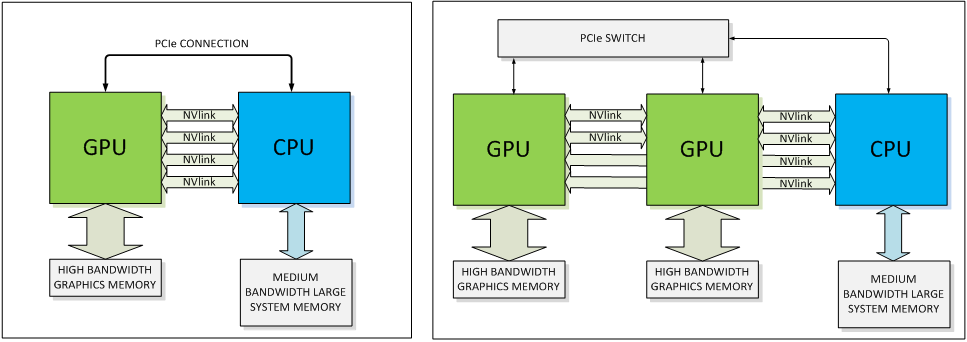
This can become especially critical as the CUDA 6 architecture supports “unified memory”, which makes it possible for the GPU operations to read and see the CPU memory and the CPU to see the GPU memory — without any additional programming hoops to jump through. The media and entertainment field is just one part of the GPU/CUDA market for NVIDIA — this type of fast memory and data access will have huge benefits in data center computational operations such as simulations, data mining, and more.
Of course, at this point we don’t know how many PC manufacturers will adopt NVLink. But the good news is that even in systems without NVLink to the CPU, the GPUs can still use NVLink to communicate between cards. This will allow for incredibly fast sharing of data and processing between cards in the future.
Having tremendously fast transfer speeds between cards is great, but if you’re memory limited on the cards then it’s not going to be as great a value. Developers in the vfx industry frequently hit the limit on memory ceilings on the GPU, as even the new 12GB card limit isn’t enough for numerous applications — especially rendering applications. That’s where “stacked memory”, another tech which will debut with Pascal, comes in.
We covered this a bit last year, but it basically allows much more memory to be on-board and accessible to the GPU. With the current Kepler architecture, the GPU chip is surrounded by the memory. And while the bandwidth of the memory on a GPU is greater than that on the CPU, there simply isn’t enough memory on the GPU for many of the tasks needed in vfx and post. NVLink not withstanding, moving data from the GPU to the memory chip on the card is inefficient as the card itself has speed limitations due to its size and it actually takes (relatively) considerable power consumption to do the move.
In Pascal, the solution is to move the memory and stack multiple memory chips it on top of the GPU on a silicon substrate (a slice of silicon). They then cut through the memory, directly connecting the memory to the GPU. This will solve having to get memory off the actual GPU chip and onto the surrounding board.
When we wrote about this tech last year, we commented that while stacked memory was great “getting the data to the GPU is another matter, – but at least it appears as though the GPU itself will no longer be a bottleneck.” Well, it’s a year later and NVIDIA has announced NVLink to help address this issue. That’s good news for the industry.
Enter the Titan Z
 There’s been another leap forward in the Titan line, with the announcement of the GTX Titan Z. This is a beast of a card, with 5760 CUDA cores and 12GB of memory, providing 8 TeraFLOPS of processing power And by beast, we mean good beast. This is *double* the number of cores in the current GTX Titan or the flagship K6000 Quadro card. Not surprising, since it’s basically two Kepler GK110 GPUs in a single enclosure.This is an important distinction, because applications that use CUDA will be able to use all 5760 cores for insane processing speed. Yet apps that use it as a GPU (for instance, with GLSL shaders) will effectively treat it as two separate GPU cards so the speed increase won’t be doubled.
There’s been another leap forward in the Titan line, with the announcement of the GTX Titan Z. This is a beast of a card, with 5760 CUDA cores and 12GB of memory, providing 8 TeraFLOPS of processing power And by beast, we mean good beast. This is *double* the number of cores in the current GTX Titan or the flagship K6000 Quadro card. Not surprising, since it’s basically two Kepler GK110 GPUs in a single enclosure.This is an important distinction, because applications that use CUDA will be able to use all 5760 cores for insane processing speed. Yet apps that use it as a GPU (for instance, with GLSL shaders) will effectively treat it as two separate GPU cards so the speed increase won’t be doubled.
Further details are slim at this point, but based upon what we do know, expect a maximum power consumption of 400W. It’s always hard to tell from photos, but the card looks physically quite large as well. Gamers will probably balk at the $3,000 price tag, which is well over double the cost of a single Titan. But for post pros looking for more CUDA processing power, that’s chump change. Needless to say, we want one.
Iray VCA
Last year, we covered the introduction of the GRID VCA. This year, NVIDIA announced a flavor of the VCA targeted specifically towards rendering: the Iray VCA, which is a GPU rendering appliance running NVIDIA Iray. It is effectively a GRID enclosure with 8 Kepler-class GPUs, each with 12GB RAM, providing over 23,000 CUDA cores. It also has GigE, 10 GigE, and 1 Infiniband connection.
Support for rendering will need to be provided within the native 3D app (or by plugins), but this week they are already showing support in a variety of apps such as Bunkspeed Drive, from RTT; Iray for Maya, from 0x1 Software; and Iray+ for 3ds Max, from Lightwork Design.
One big feature of the VCA is the ability to link multiple VCAs together to act as one virtual device. At the keynote, Huang showed a very impressive demo of the ability to chain together multiple Iray VCA systems, using 19 appliances together to render a full resolution model of a Honda with impressive speed.
Iray VCA is priced at $50,000 USD
There was some other cool stuff covered at the event, from an Audi self-driving car to machine networks and neural learning. Check it out yourself by watching the full keynote presentation on NVIDIA’s YouTube channel.
OTOY Octane 2.0 announcement
It’s been a year since Octane was demoed as part of the keynote presentation, and at a presentation at this year’s conference OTYO CEO Jules Urbach revealed plans for version 2.0, due out this year. The goal for the next version is to both improve stability as well as provide user-requested features such as displacement mapping, motion blur, and more.
OTOY provides plugins for a variety of products, from Maya to MODO to Blender. New for 2.0, OTOY will be introducing new plugins for both Photoshop and After Effects, allowing rendering using Octane right in the viewport. This is a pretty exciting development for users of After Effects — and we’ll be meeting with the team at OTOY later this week to get more details.
In the meantime here are some bullet points of new features planned for inclusion in version 2.0:
- Displacement mapping – Used to give objects depth and detail, displacement mapping allows the height of points on a surface to be adjusted based on an image value.
- Object motion blur – The blurring effect that simulates motion of inanimate objects in a rendered scene will be supported and can be applied independently of the camera movement.
- Hair and fur – An optimized hair render primitive is now available to allow rendering of hair or fur while reducing memory usage by 20 times compared to previous processes. OctaneRender™ 2.0 will also simulate the distribution and fluidity of movement of those primitives.
- OpenSubDiv surfaces – Pixar’s powerful library for fast refinement of subdivision surfaces using the capabilities of graphics processors will be integrated within OctaneRender™. This useful technique in animation will conveniently be integrated into OctaneRender™’s user interface, allowing subdivision surface refinement specifically based on Pixar’s OpenSubDiv implementation.
- Rounded edges – Artists will have the ability to easily and efficiently round the sharp edges of geometric objects without modifying and reloading the geometry. The process is done during rendering by special shader algorithms that recalculate normals near the sharp edges and corners to make them appear smooth allowing for the tuning of edge sharpness in real-time throughout rendering.
- Random color texture for instances – Useful for easily modifying the colors of instances which otherwise have the same material.
- Improved sky rendering – Using HDRI + Sun, OctaneRender™ 2.0 will enable the use of textures as sky backgrounds, and ensure that objects in the scene accurately reflect the loaded sky texture.
- Node folder structure – OctaneRender™ 2.0 will facilitate a cleaner, more organized workspace with a new folder structure that allows users to create packages of nodes, node graphs, and node trees, and organize them in folders along with thumbnails for easy identification.
- Region rendering – To save time on test renders, this feature will allow users to specify a region in the scene and partially preview rendered results in real-time.
- Network rendering – The rendering process can be made faster than ever by leveraging remote GPUs on render slaves connected via the network.
- Support for new display types – OctaneRender™ 2.0 will support new presets that can be used to render scenes directly for new display types including VR devices such as the Oculus Rift.
- Compatibility with Brigade – OctaneRender™ 2.0 will further expand its integration with Brigade, OTOY’s cloud rendering technology for photorealistic next-generation games. Within Brigade, users will be able to open scenes created in OctaneRender™ and walk through those scenes in real-time over the cloud.
Pingback: NVIDIA GPU Tech Conference: Day 1 Report | Occupy VFX!
Pingback: Octane Render WARNING RENDER IS FAILED for 3dsmax - taukeke