Keynote
NVIDA CEO Jen-Hsun Huang kicked things off at the GPU Technology Conference (GTC) at Tuesday’s keynote address and began with a bit of perspective. The growth of the GPU has been quite remarkable for NVIDIA over the last seven years. The first beta of CUDA was released in 2007, marking a move into high performance computing for the company. In 2008, the year of the first GTC, there were 150,000 downloads of CUDA, 4,000 academic papers published which utilized CUDA, 6,000 Tesla GPUs in the wild, leading to 77 Supercomputing Teraflops.

Over the years, there has been a general trend at NVIDIA of doubling the GFLOP performance per watt every two years or so. This is an important point as they are very much focused on making the processing much more energy efficient over time. This is something that was less important to the CPU developers, though this has been shifting a bit with the introduction of mobile processors. As installations such as large render farms scale in size, this differentiation between the CPU and GPU becomes critically important (it already is). Especially if some of the shortcomings dealing with memory access can be addressed in the GPU in the future.
As of today, there have been over 3 million CUDA downloads, 60,000 academic papers, 450,000 Telsa GPUs, which equates to 54,000 Supercomputing Teraflops. What’s interesting about the growth is that in the last two years, the number of CUDA downloads has effectively doubled, so the growth appears to continue.
Deep Learning
The big theme at GTC 2015 is “Deep Learning”, which the parallel processing general purpose GPUs are especially suited towards. A full discussion of deep learning is outside the context of the article, but in basic terms it is about feeding input into the program and then providing some kind of feedback about this input. Over time, as more and more inputs are entered, relationships between the various inputs are made.
A real-world example of this would be voice recognition or image classification such as AlexNet. As more and more images or sounds are fed into the system, complex multi-level relationships are created which allow the program to identify images or words. These deep neural networks become more accurate as more data is input into them. This allows something like AlexNet to recognize and identify what the content is of an image being fed to it.
Parallel GPU processing is perfect for this type of task, so NVIDIA has introduced new hardware targeted towards researchers called the DIGITS DevBox. It’s a $15,000 plug and play box that comes in one configuration: 4 GPUs with linux and all needed software installed to get researchers quickly up and running on. CEO Jen-Hsun Huang expects fairly low-volume sales, but it’s an important part of the market for them to make it easy for their customers.
GPU Roadmap
In what has become an annual part of the keynote address, Jen-Hsun Huang gave further updates on the company’s roadmap for development. The current generation of GPUs is called “Maxwell”, and this year marks the middle of what is generally a two-year cycle. Pascal, the next-generation GPU, will debut in 2016. It’s main features include stacked (3D) memory, NV Link, and Mixed Precision processing. From a visual effects/post standpoint, the key features are the stacked memory and NV Link.
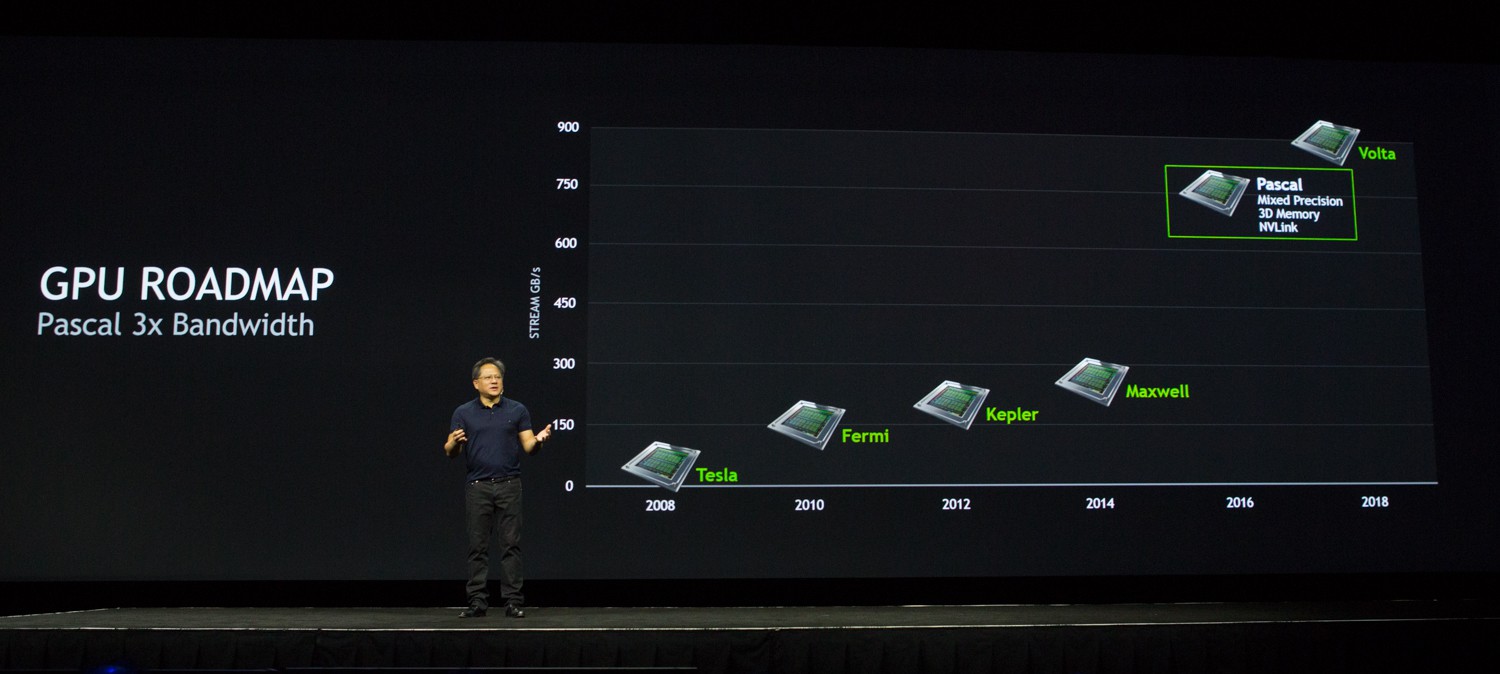
While PCIe is fast, this bandwidth doesn’t measure up when compared to the speed at which the CPU can access memory. This bandwidth can become even further limited if systems use a PCIe switch, which can occur in multi-GPU systems. NVLink is a new high-speed interconnect for CPU to GPU and GPU to GPU communication, intended to address this problem. Co-developed with IBM, NVLink can hit speeds of between 80 and 200 GB/sec of bandwidth, providing very fast access to system memory. It is also more energy efficient in moving data than PCIe.
Stacked memory allows much more memory to be on-board and accessible to the GPU. While the bandwidth of the memory on a GPU is greater than that on the CPU, there simply isn’t enough memory on the GPU for many of the tasks needed in vfx and post. NVLink not withstanding, moving data from the GPU to the memory chip on the card is inefficient as the card itself has speed limitations due to its size and it actually takes (relatively) considerable power consumption to do the move.
In Pascal, the solution is to move the memory and stack multiple memory chips it on top of the GPU on a silicon substrate (a slice of silicon). They then cut through the memory, directly connecting the memory to the GPU. This will solve having to get memory off the actual GPU chip and onto the surrounding board. The new architecture has three times the memory bandwidth of Maxwell, which should be close to hitting about 1TB/sec. That’s welcome news for our industry.

As far as expected speed increases, Huang gave his “rough estimate” of a 10x increase in performance for with Pascal as opposed to the current generation for deep learning type tasks. But don’t get too excited yet. For most visual effects/post/graphics purposes, we won’t see as dramatic an increase since much of this speed is due to improved mixed precision general purpose processing (FP16/FP32) — though sims and other processing tasks could see increases. That being said, he felt that 3D memory could provide a 6x increase and NV Link would provide speed increases as well — so expect to see a significant increase in performance….just not 10x.
Hello, Titan X and DRIVE PX
This year’s graphics card announcement is the GeForce GTX Titan X, a single core Maxwell-based GPU with 3072 CUDA cores and 12GB of on-board memory, providing over 7 TFLOPS of processing power. And it comes at an incredibly sensible price point of $999 USD. Last years’ Titan Z, a dual GPU model providing 8 TeraFLOPS of processing power, cost listed for $3,000 USD.
In the Titan X, NVIDIA have dedicated more of the processing core to graphics performance than they have to general purpose processing power. This means that CUDA type operations won’t see an improvement (hard core parallel processing functions like sims, raytracing, rendering, etc.), but Open GL and other shader-type functions will see an increase in speed.
For more details about the new GTX, AnandTech has an incredibly in-depth review of the card.
Jen-Hsun Huang also introduced NVIDIA’s new car kit, DRIVE PX which aims to augment automobile’s autonomous driving functions. Based on two Tegra X1 processors, it can process AlexNet at 184 million frames a second. To close out the keynote, Tesla’s Elon Musk joined Huang on stage to discuss the future of driverless cars.
OTOY
Jules Urbach, CTO of Otoy, took the stage at the GTC keynote back in 2013 to show off their new Octane renderer. This year, he used a session at GTC to make several announcements.
First, he announced Octane VR, a free version that offers all features of Octane 2.2. It is not a demo version, it contains no watermarks, and can even be used for commercial purposes. However, it’s only available for a limited time, between April and July. This is an experiment of sorts for OTOY, as they wish to both expand use of Octane as well as make a push into VR since the renderer has easy output into the format that can be viewed on the Samsung GALAXY Gear VR. The plugins for various DCC packages will continue to be paid products, so you’ll need to purchase them in order to use the free Octane VR.
Next, Urbach revealed plans for the next major release(s) of OctaneRender. While the early releases of the renderer have been much about creating a nice final image, this release looks to shore up the software with respect to integration in a facility workflow. With support of PTEX, FBX, OpenVDB, and OSL, the renderer becomes a much better “citizen” within the walls of a post house.
Here are the main features, some of which will be part of the initial 3.0 release, and others which plan to be rolled out over the next year with dot releases:
- Volumetric rendering: OctaneRender 3 supports the ability to render particulate matter such as clouds, smoke, fog, and fire with varying densities and introduces a unique native primitive type for incredibly detailed micro-surface displacement volumes and surfaces required to render photorealistic natural and organic materials. Dreamworks’ OpenVDB is also supported for direct in-camera rendering of particle simulations.
- Open Shader Language (OpenSL) support: Through OpenSL, content creators have the ability to build their own materials, procedural textures, and shaders, taking advantage of what is quickly becoming an industry standard while maintaining the exceptional performance OctaneRender is known for.
- OpenCL support: OctaneRender 3 will support the broadest range of processors possible using OpenCL to run on Intel CPUs with support for out-of-core geometry, OpenCL FPGAs and ASICs, and AMD GPUs.
- Deep pixel rendering: OctaneRender 3 adds deep pixel rendering support, as well as live connecting of DCC and compositing apps through Octane plug-ins for Pixologic’s Zbrush and The Foundry’s NUKE. OctaneRender 3 will also ship with a built in plugin for Adobe Photoshop that will properly handle multi-layer EXR files and support live deep pixel layer composting within Photoshop. Artists can open, create, and save ORBX media files introduced in OctaneRender 3, including planar and volumetric light fields, directly within Adobe Photoshop.
- Advanced live texture baking: A feature that’s most beneficial for use in real-time game engines, OctaneRender 3 supports unbiased GPU texture baking (UV or volumetric) of global illumination, spherical harmonics and 8D light fields in Unreal Engine 4 and Unity plugins.
- Infinite mesh and polygon sizes: OctaneRender 3 removes all limits on the maximum allowed primitive and triangle count.
- FBX and PTEX support: OctaneRender 3 supports importing data from Autodesk’s FBX file format and Disney’s PTEX texture file format.
- Split render passes, advanced per object reflection controls: OctaneRender 3 allows artists to split render passes into raw lighting and albedo passes, and adds fine-grained reflection, shadow and illumination casting controls per object or layer. These elements can also be built into the export, whether it is a light field, VR scene, or a movie file.
- Fully configurable: OctaneRender 3 allows fully configurable UI, transform gizmos and dockable windows.
- New plugin APIs: While previous versions of OctaneRender have support LUA plugins through scripting nodes, OctaneRender 3 adds C plugins and portable LLVM-based API support in ORBX packages.
Urbach also announced a new ORBX Media Format which, in theory, will help ease moving between various packages, especially when dealing with virtual and augmented reality applications. It builds upon the .ORBX container which was introduced to facilitate moving between various Octane DCC plugins. The new format is targeted towards rendered output, and supports movies, caching of FBX, light field and spectral render, and deep data.
Here are the main bullet points from the OTOY press release:
- First-of-its-kind container: The ORBX media format is the first of its kind, containing pre-rendered data in the form of light field render target caching for VR, AR and portal materials, supporting movie and audio textures such as MP4 or HEVC for use natively inside of OctaneRender as a texture or a procedural, and storing node timelines.
- Fully navigable: ORBX media files support web and mobile viewing of interactive content and texture baking directly from an Octane scene node, without the need or mastery of real-time game engines. Artists can bake their 3D scene for mobile, TV, VR, AR (light fields) and HTML5 playback.
- Versatile rendering: The ORBX media format stores spectral film buffers allowing artists to pause and resume renders from disk.
- Plans for open source: OTOY intends to open source the ORBX media format. It will be available on GitHub when OctaneRender 3 is made available. The format works in JavaScript and LUA – no native code is required.
- ORBX Media Viewer: The first app that will support the ORBX media format will be the ORBX Media Viewer. The ORBX Media Player is already used for enjoying studio VR experiences such as the upcoming Batman: The Animated Series project OTOY is building with Warner Bros., or live streamed VR events like the hockey game OTOY recently produced in cooperation with the NHL. The ORBX Media Player will work with the Samsung GALAXY Gear VR, as well as Android-powered phones, tablets, and set-top boxes, with support for Microsoft HoloLens and HTML5 WebVR to come after launch.
In addition to the OctaneRender 3 and ORBX announcements, they also announced that the OctaneRender cloud will be entering a beta phase early this year. The cloud-based rendering service will have feature parity with OctaneRender 3. It can be accessed for live authoring using an HTML 5 web browser, or maybe used for cloud-based rendering of ORBX scenes. The service is powered by Amazon Web Services and OTOY’s GPU clusters.
V-Ray and GPU Rendering
Chaos Group founder Vladimir ‘Vlado’ Koylazov and GPU programmer Blagovest Taskov spoke at a session covering their latest advancements towards making a full-fledged GPU production renderer. They needed to improve memory handling for the GPU, especially dealing with textures. The system for dealing with these more complex things in terms of memory is similar to CUDA API tools but actually uses Chaos own system and thus also works for OpenGL.
Vlado commented on how in the early days of GPU that if a single line of code that was wrong, it would lead to BlueScreenofDeath. Today things are much improved, but it is still difficult to debug on the GPU, so Chaos designed things so that development work would be similar in complexity to developing C++ on the CPU, and today they can use the same code to compile for the CPU as for say CUDA or OpenCL. These simple debugging coding tools -break points, examining variables etc have made the development environment that the team works in more productive
This all comes at the cost of the actual test rendering running much slower, but this is of course only a factor during development testing on the CPU and overall the code is now more robust and faster. “it is slower than the actual code running on an actual GPU when you are writing code,” says Vlado, “but it is so useful I cried a little when I saw it running, and it s really helped with our development.”
A lot of improvement for the GPU renderer is the licensing of QMC sampling from NVIDIA. The QMC (Quasi-Monte Carlo) method uses low-discrepancy sequences instead of pseudorandom number generators. In layman terms this means the distribution seems more random – while not being – but avoids the clumping that is natural in random or pseduorandom sequences. The more evenly random the samples, the less samples for the same perceived anti-alising or noise for example. Chaos licensed this from NVIDIA (which uses it in Mental Ray/iRay). This is important for Chaos as the GPU renderer uses random sampling much more than the CPU production renderer, and thus uses the QMC to produce – in some cases – a better noise floor than the main production renderer.
Global illumination has also had its Light Cache improved, which with the latest hair shaders has improved the realism in the GPU interactive renderer which now supports hair and hair material. This includes importance sampling, (which is only uploaded to the GPU if hair is in the frame).
Along with the hair there is the sub-surface scattering shader (SSS) which is a modified dipole model with a diffusion kernel. On their CPU renderer this is helped with a pre-pass, but this can’t be done in the GPU as there is no pre-pass just the GPU ray tracing. The solution is to take a point beneath the surface and then tracing out a set of rays, “until they hit the surface of the object, this is one of the few cases where we simply had to use recursive calls – because we had to potentially calculate the illumination at many points along the same ray,” explained Vlado. “Because of the the recursive calls this only works in CUDA so this does not work in OpenCL.”
In terms of textures, the GPU now supports UDIM textures in addition to UV textures. Textures is a key aspect of balancing memory requirements in GPU, as part of this texture extensions texture baking was also added. Interestingly, while most users are fine with using 24GB of memory, Chaos was keen to also serve the 10% of their customers who have a need for over 24GB, and sometimes even 100GB, 200GB of memory or more.
In the past they joked that hitting memory issues with very complex textures and files was like falling off a cliff, as it killed you in production. Chaos aimed to make it more like falling down the stairs: sure it may hurt you to render vast scenes with hundreds of gigabytes of data, but it won’t kill you! With GPUs some 10 to 20 times faster than CPU, if it slows down by a factor of say 5, it is still faster, just not by such a great amount. Chaos has done this with a new pixel texture system rather than tile texture system which has resulted in a valid speed improvement. In other words: that render cliff is avoided!
In the future the team is looking to expand this to remote cloud rendering or a cluster of machines over a public network. In this model, it is not just a matter of using distributed rendering (due to traffic bandwidth). Instead a better cloud strategy is required with a head node in the cluster, and other browser support.
V-RayRT in Motionbuilder with V-Ray Cloud
One big point that was left to later in the presentation was the addition of GPU rendering right inside Autodesk Motion Builder. This will be very popular for motion capture stages seeking higher realism on real time preview and the model presented is very scalable depending on the range from single machines with a GPU to some form of cluster you might have on the stage. This could potentially be very powerful for Chaos moving forward and it will be interesting to see the customer reaction to this.
Redshift
One of the sessions in the Media & Entertainment track was a presentation from Redshift, makers of a relatively new GPU-based renderer. What is interesting about the team is that their background is in games, with the realtime GPU rendering requirements inherent in the medium. Instead of approaching the problem of GPU rendering from a production CPU renderer perspective, they come at it from the GPU at the start.
Robert Slater, one of the co-founders of Redshift, says that it’s not just another GPU renderer. The aim is to create a final frame production ready renderer that “brings the flexibility of biased CPU rendering to the power of the GPU.” They have a flexible material system, multiple biased global illumination modes for diffuse bounces and caustics, and have full sampling controls for cleanup of noise.
A spot created by Glassworks and rendered in Redshift
Unlike most GPU renderers, limited available VRAM is not a problem for the team. They support a virtually unlimited number and size of bitmap textures, which means an artists can render scenes containing a terabyte of textures without running out of memory or crashing. They do this by using out of core paging technology, meaning that all assets don’t need to be in VRAM at once. They also have built-in UDIM/UVTILE texture tile support, which allows artists to efficiently texture tiles without having to rely on complex shader node graphs to do so.

Panos Zompolas CTO and co-founder, went through various rendering challenges and how Redshift deals with each.
First off was the challenge of dealing with out of core memory, allowing the scene data size to exceed the GPU memory limit by accessing the CPU memory. They looked at a lot of potential solutions, but ending up designing their own caching system because of limitations in direct CPU memory reads and because unified virtual addressing (UVA) needs pinned memory. They found that blocking/granularity of the data is super important, using tiled mipmaps for textures and local primitive groups for geometry. In the end, they found their GPU caches work really well with textures, getting good cache-hit ratios for the mipmaps. Even if you’re using 10s of gigabytes of memory, you don’t actually need all that.
A second challenge was the material and shading system. Redshift supports more than 200 shading nodes, with many possibilities of combinations. Their original solution was to recompile on shader graph edit, but what this meant was that every time an artist updated the scene — there would be a hitch/delay before the visual result was updated.
Finally, even though it is a GPU renderer, the team needed to consider CPU Performance. The GPU can’t currently do everything by itself as it is slowed down by tasks such as scene extraction from the 3D app, disk/network loading, tessellation, and saving the final rendered images to disk (deep images are especially huge). Their solution was fairly straightforward, which was to speed up CPU processing by multithreading as much as possible as well as caching and re-using the data. They could also render a few frames at once, but this consumes more main memory.
Moving forward, Redshift plans the following features/improvements for the future:
- 3ds Max plugin is currently in alpha testing
- Adding support for more apps like Cinema4D, Houdini, Modo, Blender, and more
- Linux support is in progress
- Ray marching (non-homogenous volumetrics)
- Single scattering
- Shave/Yeti/XGen support in Maya
- More BRDFs (GGX)
- User AOVs (regular AOVs already supported)
- User-defined shader nodes (creating a shader SDK)
- Continuing optimizations
Some of Alf Martin Løvvold’s work, using Redshift for final rendering