Nuke 13 includes Machine Learning (ML), a flexible machine learning toolset. The ML Toolset was developed by Foundry’s A.I. Research team (AIR), it enables artists to create bespoke effects with applications of the toolset including upres, removing motion blur, tracking marker removal, beauty work, garbage matting, and more.
The key components of the ML toolset include:
- CopyCat – an artist can create an effect on a small number of frames in a sequence and train a network to replicate this effect with the CopyCat node. This artist-focused shot-specific approach enables the creation of high-quality, bespoke models relatively quickly within Nuke without custom training environments, complex network permissions, or sending data to the cloud.
- Inference- is the node that runs the neural networks produced by Copy Cat, applying the model to your image sequence or another sequence.
- Upscale and Deblur – two new tools for common compositing tasks were developed using the ML methodology behind CopyCat and open-source ML-Server. The ML networks for these nodes can be refined using CopyCat to create even higher-quality shots or studio-specific versions in addition to their primary use for resizing footage and removing motion blur.
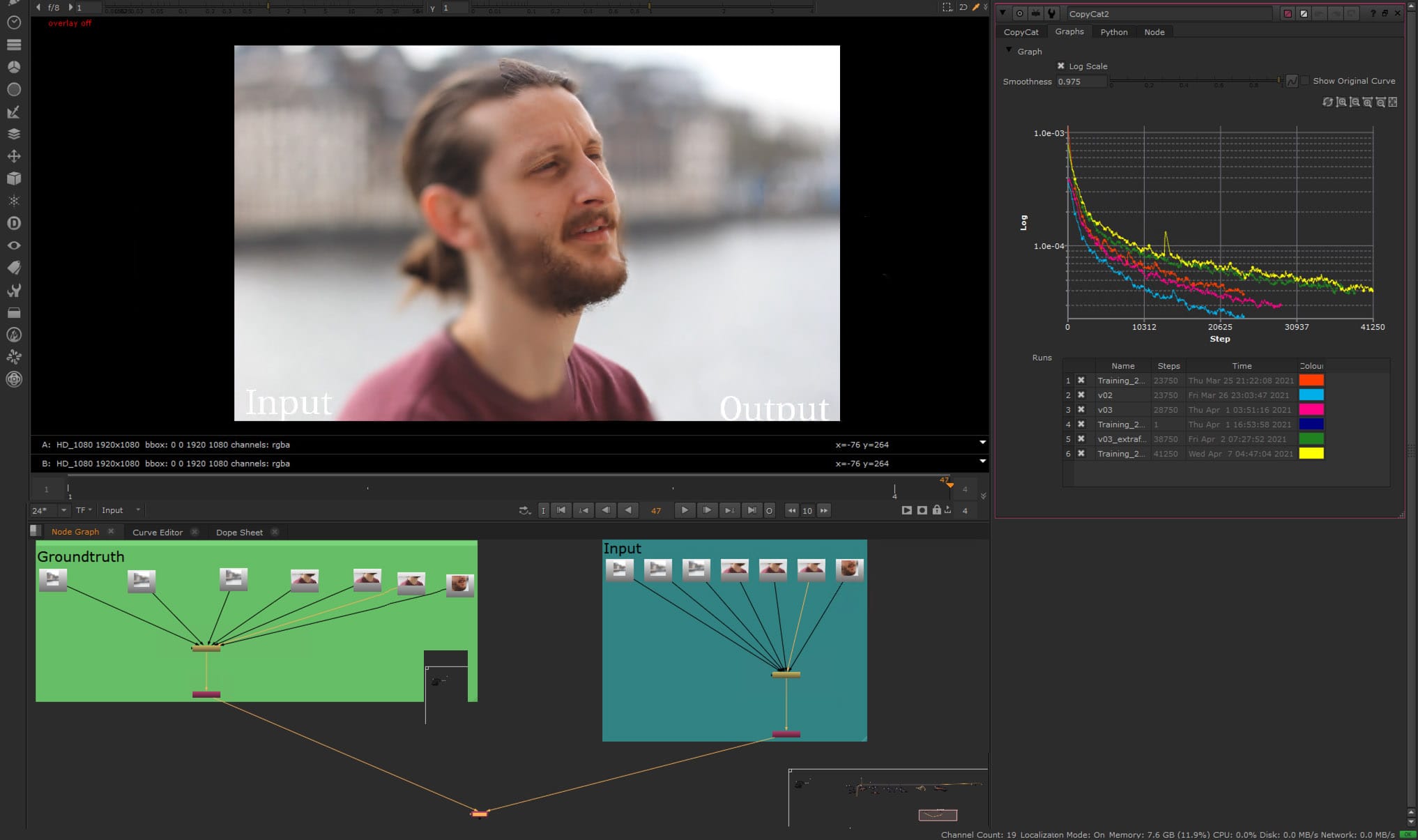
Two years ago, fxguide published a story on the Foundry’s open-source ML-Server client/server system that enabled rapid prototyping, experimentation and development of ML models on a separate server, with the aim of introducing a way to have ML tools in Nuke, but developed in parallel.
With Nuke v13 the Foundry’s AIR team now offers native nodes inside Nuke. Primary amongst these is the CopyCat node. As with the ML-Server, the core ML tool is a Multi-Scale Recurrent Network (MSRN). “We do believe that the MSRN is a magic network, it solves a huge variety of challenges, and it does it well,” comments Dr. Dan Ring, Head of Research at the Foundry. There is no doubt that ML brings to Visual Effects a whole new world of solutions to visual effects problems. What makes it so exciting is that ML represents a new way to solve problems not just a new tool or node in Nuke. The approach of providing training material to a ML node which then infers a result is truly revolutionary and exceeds even the current hype surrounding the general AI buzz in the press. There is now little doubt that while such AI tools will not replace artists, those who fail to understand them may fall away as a new generation of complex AI solutions are deployed.
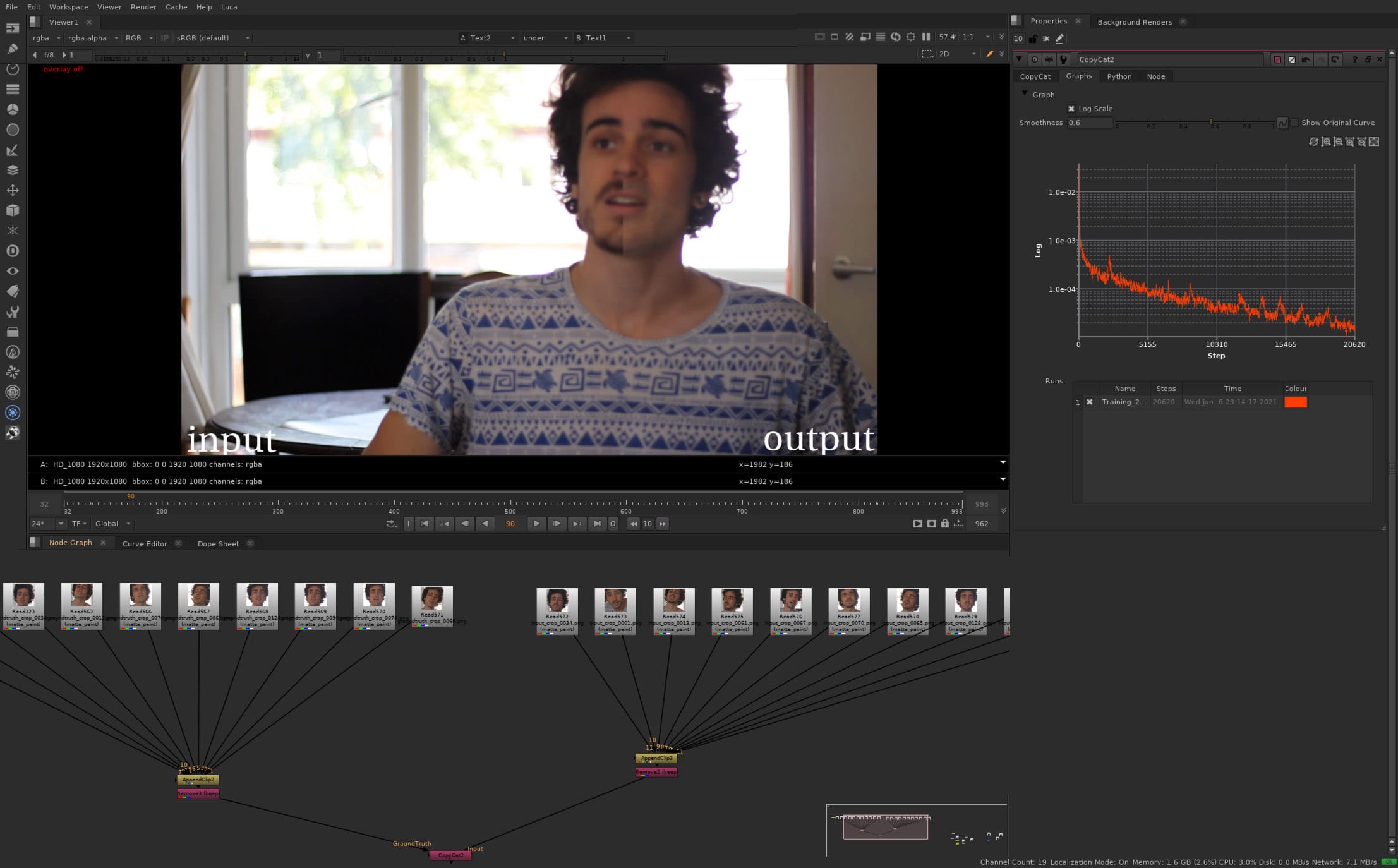
Supervised Learning
Not all AI or ML requires training data examples, but the CopyCat node does. This is because it is part of a class of ML called supervised learning. Importantly there are also ML solutions that are classified as Unsupervised and Reinforcement Learning, more on those below.
To use CopyCat is relatively easy, sample frames of roto or beauty work are provided as before and after frames to Nuke. The system then infers what has been done and applies it to a clip. To really master ML it is worth understanding how this works and what is really happening under the hood. It is easy to anthropomorphize the actions and imagine the computer ‘sees’ the frame as we do. The output seems so logical and sensible that when it does not work, (and it most certainly can fail), such failures seem to make almost no sense.
The first thing to understand is that the computer has no understanding of the image, it appears to, but it does not. It works on statistical inference and while we clearly see a person or a car, the computer never does, it just sees pixels and it tries to reduce errors so it’s output aligns mathematically with the training data. The further you ask the computer to infer outside the examples of training data space, the worse the results. It infers best inside the space not extrapolating from the examples. It also does not view the whole frame as one thing, it works in patches.
What makes the computer so powerful is its ability to try things a million different ways and if it starts getting better results it continues with that line of inference. In maths terms, this is directly related to the reduction of errors in the ML network. The network is called a Deep Network as it has layers. To reduce the errors, it ripples back through the network improvements to its’ approach, changing the weights of nodes inside its neural network. This rippling back is called backpropagation. If the error is high then via backpropagation it is reduced, this declining error rate is mapped visually in Nuke and is called gradient descent. As with most things in life, it is easy to take a wrong turn or ‘bark up the wrong tree’. In maths terms, this means that there is a local minima, and one of the greatest technological feats of CopyCat in Nuke is how the AIR team have produced a general tool that overcomes wrong turns or local minima and manages to drive the gradient descent effectively on a host of different visual problems. While Foundry did not invent Multi-Scale Recurrent Networks (MSRN) the AIR team have produced a remarkable implementation that produces better results over time, in a variety of non-task-specific applications and avoids many possible problems and divergent results during the gradient descent or error reduction.
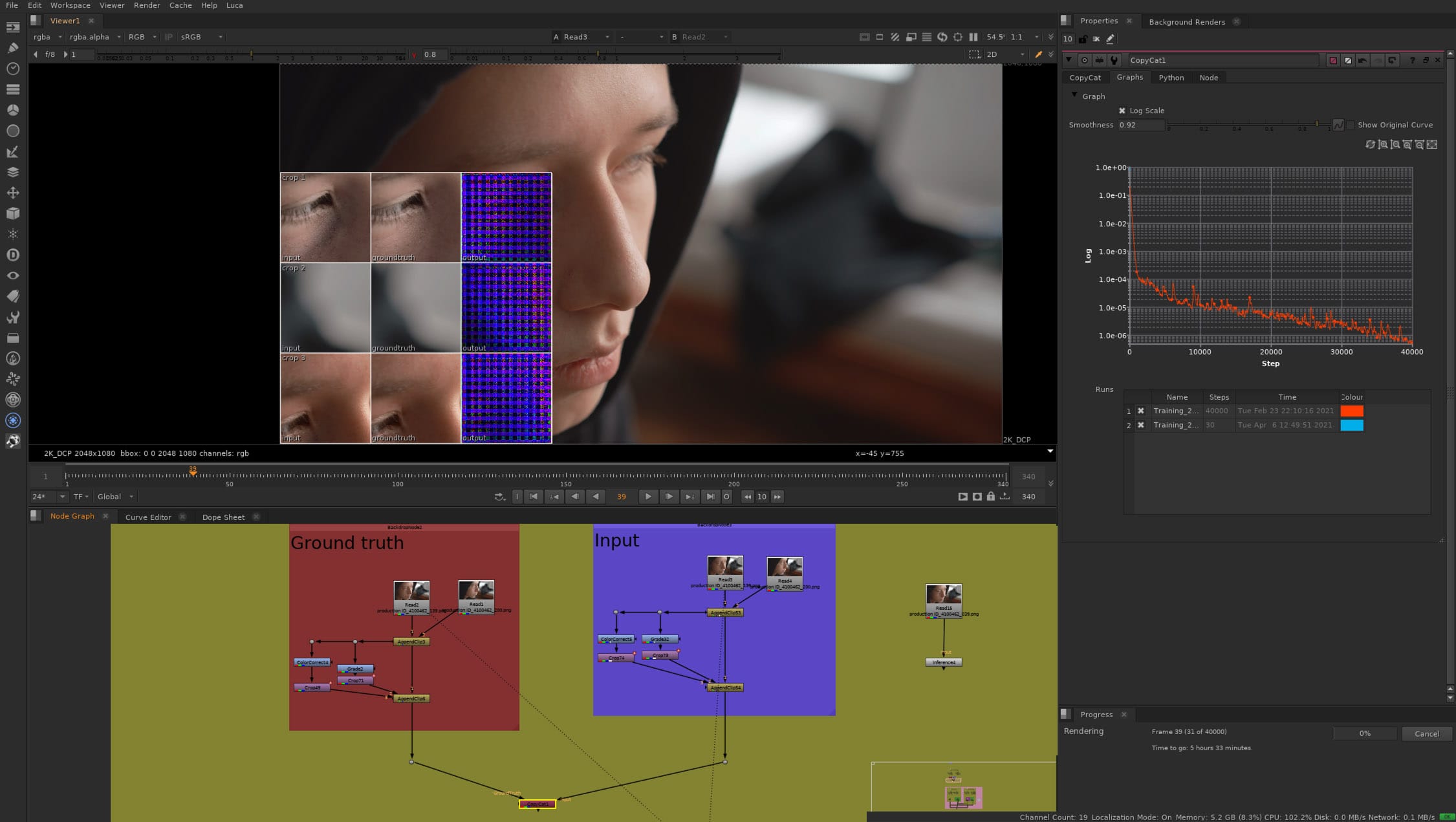
One key part of the Foundry’s highly effective solution is over-fitting. Essentially, overfitting a model for a VFX task exploits the massive within-shot redundancy while side-stepping significant inter-shot differences that traditional ML aims to capture. Although the MSRN network is not task-specific, Nuke’s encoder-decoder networks have proven themselves very effective in a wide variety of tasks. “But in each case where they excel, it’s because they apply domain-specific knowledge, and that’s precisely how we tuned our MSRN,” points out Ring. The AIR team tunes their MSRN not for a task, but for VFX, where the demands for pixel accuracy, color fidelity, and performance are very high. One of the interesting challenges Foundry faces is that while ML is a hot topic in academic research, the focus of general researchers is not a great match to the demands of the VFX world. “There are so many areas that have been completely ignored by academia. And I think that is because they’re just different objectives between an academic paper and getting a shot finished and delivered on time. They are so very different,” reasons Ring. “A prime example is that we applied the same process needed to make SmartVector useful; we paid very close attention to filtering and preserving information between filters. This is crucial in mitigating the typical artifacts you get in a lot of ML models when you stop training too soon,” he adds. Pre-processing the data is also vitally important to Nuke’s ML tools, particularly for HDR imagery, which needs special attention. “We still have more to do here: ML frameworks have been historically focused on 8-bit sRGB images and shifting to production-level images is not trivial.”

One impressive aspect of the ML nodes such as CopyCat is just how few training frames they need to be effective. Once again this is due to the computer not working in whole frames but patches. While a user may only offer 5 or few frames of supervised ‘correct’ training frames, this is enough to train and improve the inference given enough time.
The MSRN is a layered network with a set of weights, adjusting these weights is at the core of ML. The default network is roughly 42 layers deep, which is ~7M weights. You can vary the size of the parameters in CopyCat. There are other network sizes, depending on whether one wants to prioritize speed, quality, or complexity. The default 7M weights are adjusted and this is what is stored in a .cat file (which is typically about 26MB per .cat file).
What matters to the ML is the pixels vs parameters ratio. If CopyCat uses ~10 patches, where each patch is at most 256x256pixels (262,144 floating values). “For ~10 patches, we’re talking of a total of ~2M floats, which is dramatically lower than the 7M weights,” explains Ring.
GPU card advice
The ML tools work well using modern GPUs, the internal workhorse used by the AIR team is the Titan RTX NVIDIA cards for development as “the extra memory has been great,” Ring comments. Generally, users need a minimum amount of memory to run the inference, “at the moment you need about 7 or 8 Gigs VRAM in order to do anything, that’s the minimum. We haven’t used the 3080, but we have been using the A6000 and that has been phenomenal for our performance transfer work. The sweet spot is 24Gig/ Titan RTX for training … as we move forward, we are seeing the need for a lot of VRAM…I think if you’re thinking about trying stuff now, then the current level of cards, like, the 2080s, are great. If you’re looking forward the 3080 is going to be great, or the 3090, if you can get your hands on it – absolutely. ”
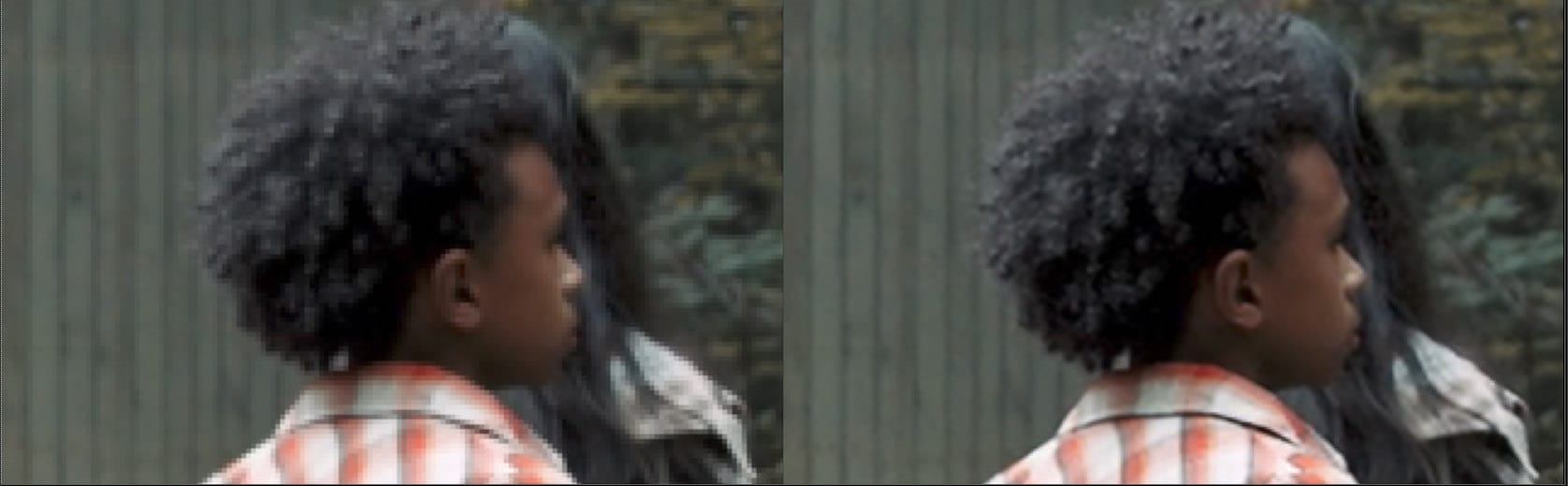
ML Server is not dead (just yet).
Nuke is a platform as much as an application. Many facilities build out from the core of Nuke using C++ SDK and Python. It is Foundry’s desire for this to extend to ML. High-End users are encouraged to build ML processes that create their own .cat files that feed the Inference node. In five years from now the Foundry expects teams to build their own models and share them on something like Nukepedia. Already a user can take a model from CopyCat and extend it with their own work. This does not however exclude the use of the ML-Server.
The ML-Server has been providing a lot of offline support to customers who have been working with it and using it in production. Ring points out that “if you look at the open ‘issues’ re ML-Server, you can see what has been done extends far beyond the original remit of ‘experiment with ML in Nuke’ and is precisely why our focus has transitioned to our Inference tool.”
For Inference and custom .cat files, Foundry has already started sharing a script that allows teams to package their PyTorch models into a “.cat” file, but there are some limitations. For example, there can only be 4 channel images and the same image dimensions for both input & output. “The plan is to add support for a wider variety of models and include the conversion script and training templates natively. This will be part of the next release, likely Nuke 13.1,” Ring explains.
If one looks at the Github for the ML-Server, the software has not been updated for 11 months so the current development is less than active, but the AIR team themselves still use it to quickly share models and ideas with customers and prototype their own internal investigations. “I’m not ready to pull the plug on it just yet,” jokes Ring.

Unsupervised Learning and Reinforcement Learning.
Unsupervised Learning is another extremely powerful and popular area of ML. It has wide and impressive applications in classification problems for example. Reinforcement Learning (RL) is a third area that can be powerful in improving and personalizing processes. And perhaps RL could be applied to the issues of Nuke User Experience, – in other words, there could be a role for RL in how Nuke presents itself to the user. We put to Dan Ring that RL could be a tool for personalizing one’s Nuke workflow based on understanding the tasks a user does. The challenge for the AIR team would be overcoming what is known as the Alignment problem, which means NUKE may have too much variation in tasks for RL tools. “We’re very keen to explore RL for VFX, and two of our recent hires have RL backgrounds! It is certainly on a longer timeline for us, but we (and our customers) are starting to think about what it means,” he responded.
Two examples often come up – the first is what Ring called the artist’s “MS Clippy / auto-comp my shot” task. Can a system see what a user is trying to do and ‘auto-complete’ the shot? “This is where your Value Alignment problem crops up immediately. In the artist’s case, it’s often hard to come up with the ‘real value/reward’ signal without the artist (supervisor) imparting knowledge or direction. Ideally, you want to know how well an artist or a system pulled a key from a green screen, and it’s not objective,” he explains. “There’s a lot of value in that sort of online semi-supervised learning, but it’s not strictly RL. One objective signal we can measure is time, or ‘time spent in a node’. An RL system could use that to decide an optimum set of knob values to minimize the time spent tweaking a node. Again, it’s hard to say whether a system that reduces the artist’s time spent aligns well with the task the artist is doing, but I’m looking forward to finding out!”
The second possible application is not focused on helping the Nuke artist but helping the VFX Producer answer the question “how much is this shot going to cost?” The general bidding problem is based on having several shots, and each shot requires a variety of tasks at various quality levels. The AIR team is asking now “can a system infer a list of steps to deliver your shots and reduce your costs? The alignment here is much clearer and can be measured objectively.” But Ring is also very quick to point out that this is to help producers not replace them. “A good VFX Producer is more than the sum of their experience and ability to process data.”
The volume of work a single artist has to accomplish has exploded over the last year. To help artists, things need to be faster, and that means scaling. Either across more machines on-premises or more use of processing in the cloud. “Once you start getting into serious competition for resources, your studio’s performance suffers. We’ve started thinking about how Q-learning (a branch of RL) could help,” says Ring. “In particular: for a given compute environment with a given load, can a system be used to infer the best order of Katana’s compute and data transfer operations to minimize graph evaluation and render times?” The AIR team is still investigating this, but already it seems to the team that any large-scale or out-of-core compute-heavy application should be designed with clever AI or ML scheduling.
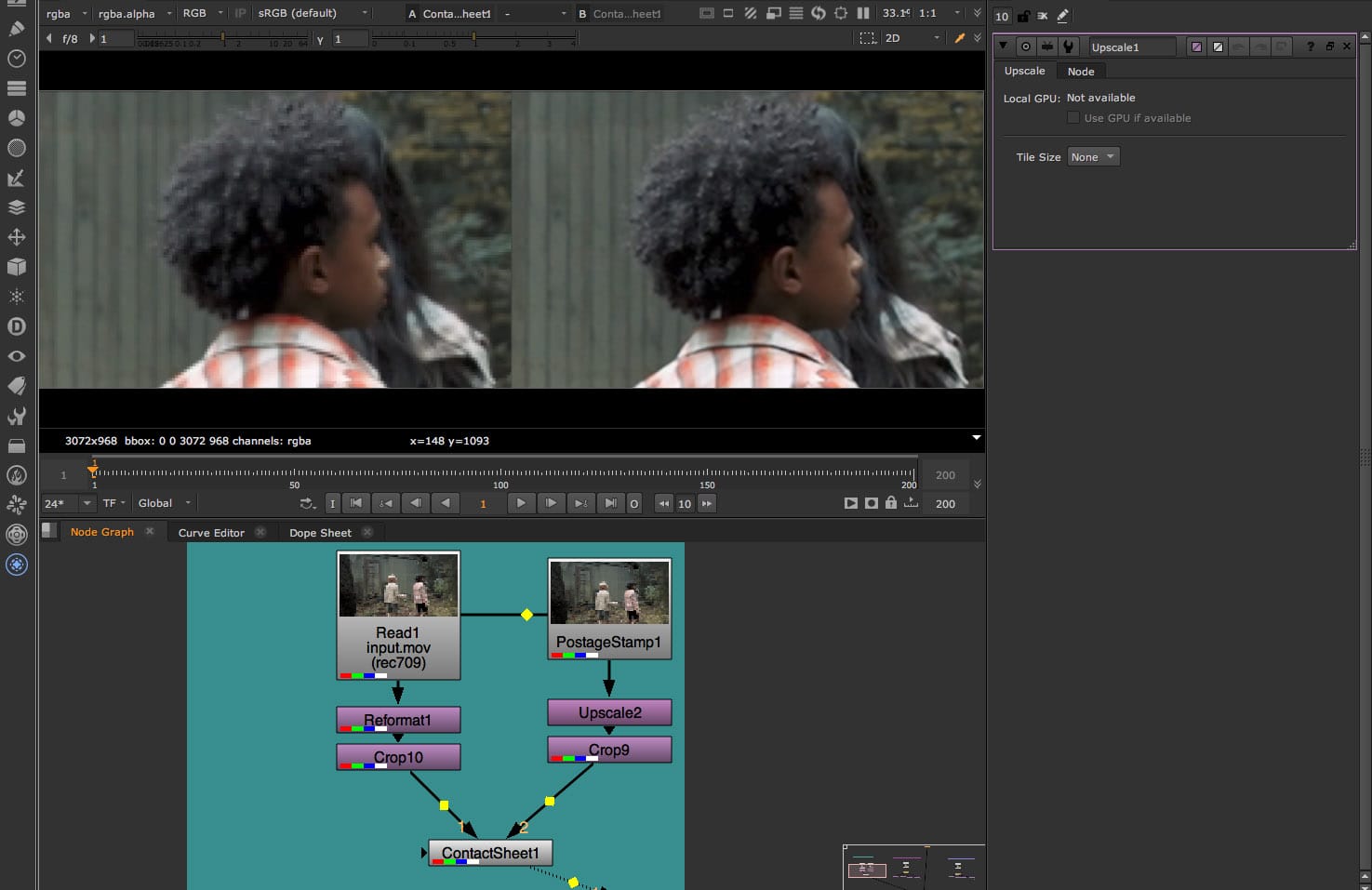
Roto.
Perhaps the most sought after ML solution is the one that would solve Roto. CopyCat can produce a very good Alpha or matte, although as Ring points out, you still need a good artist, to generate the high-quality training example for the Network to learn from, CopyCat ” won’t make a bad matte better, it will just give you more bad mattes sooner.” While CopyCat mattes can be brilliant, fully solving Roto requires genius-level AI. Foundry’s launch demos include CopyCat processing several roto shots to B/W mattes but a general solution to Roto is still a little way off. The reason that Roto is so complex comes down to three key points:
- Most ML solutions such as segmentation assume the output is a B/W matte. CopyCat can be used effectively to produce a matte, but the Roto problem is not targeted at a matte as the final output, but rather an editable splined shape that artists can adjust and vary. As such, the matte is expressed as a keyframed spline shape that sensibly moves over time. For the Nuke artist to be able to adjust the roto, the solution cannot be just a pixel mask matte output nor can it be a stand-alone spline keyframed on every single frame.
- Most ML solutions are not temporal. This may not seem obvious from the brilliant digital makeup examples, but the solution is not tracked patches but frame by frame independent solutions that just happen to be so close to each other that they don’t flicker. But the ML logic is not to solve a clip it is to solve a series of frames. This is not a great match to the roto problem. Good roto places keyframes on the correct apex of a motion, not just say every 10 frames.
- Roto artists don’t just want the current silhouette or outline as the roto output. The roto of someone walking has shapes overlapping as arms move over the body. Any good roto artist animates shapes that make sense to the object even on that frame the outline of the combined rotos is an odd-shaped blob.
Some good news is that Foundry knows that to solve roto fully requires a holistic picture; an ability to produce a spline tool that artists can manipulate. It has an internal project called the Smart Roto (Roto++) that is a funded research program with the University of Bath, University College London and DNEG since 2019. For now, CopyCat does a great job but it is very much a pixel solution. There are advantages to such an approach. As CopyCat does not care about smooth temporal splines, it is easy to make synthetic data for training. Synthetic data is when a roto is hand created for a frame and then just duplicated on a frame at random angles over different possible backgrounds. Since the ML node is just looking to learn about the transition from matte to non-matte, it can learn from fake frames which make no sense to the sequence but provide more matte vs. non-matte training data.
Roto temporal shape animation may benefit from other areas of AI. The Foundry’s own research has identified that it is estimated that just over half of all roto involved people. People are also hard to roto due to limbs and especially finger and hand occlusions along with issues related to hair and loose clothes. As such it is worth considering developing special case people roto tools. There are already some great research papers on estimating 3D human bone and joint movement from just flat 2D video. There is also strong work in ML volume reconstruction, both areas may end up as additional inputs to a more powerful people-specific roto AI solution in the future.
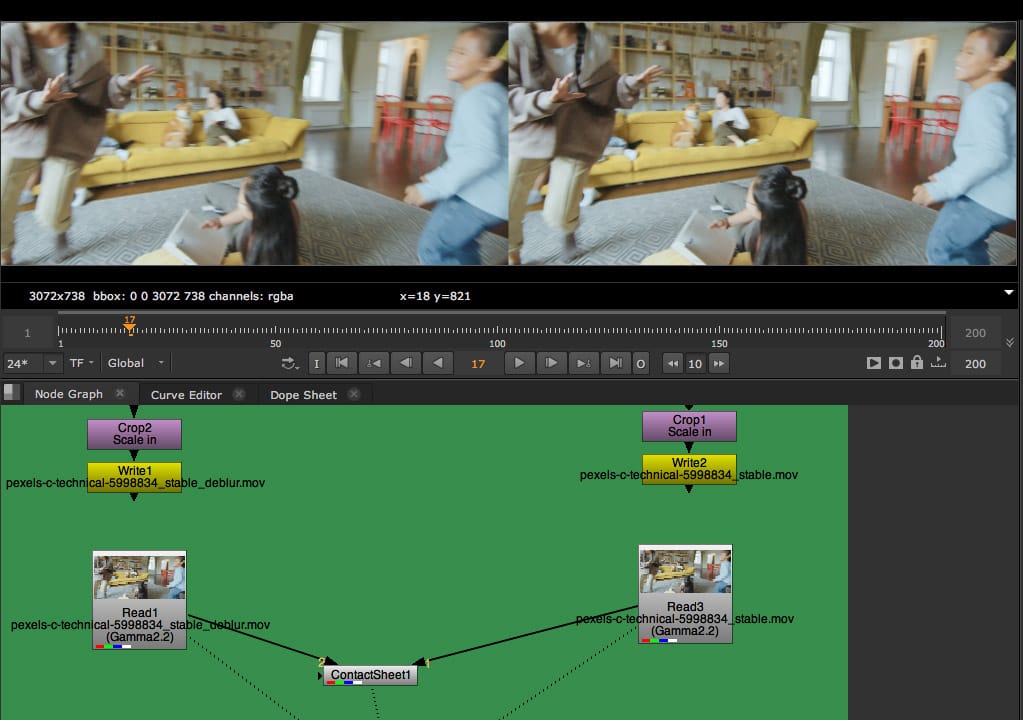
Helping Artists (not replacing them)
Thinking longer-term, CopyCat is a powerful tool for Nuke artists, and it also helps lay the foundations and set expectations around ML. The vertical headroom for ML in VFX is very high, and the impact that things like RL and Q-learning can be huge when applied to the right task with the right thinking.
It is also important to remember that the nature of ML is that it takes time to train, but often the solutions, the inference can be lightning fast, which opens up Nuke to more use in the real-time space. People are starting to use CopyCat for solving the whole host of new comp problems generated by in-camera VFX, such as fixing moiré, removing rigs in the shot, grazing angle color aberrations in LED capture volumes, and other real-time related virtual production work. Due to the nature of the LED screens themselves such as limited dynamic range, and interactions between physical lights & walls, etc, there is a host of areas in VP where Nuke is not being used. “Studios, VP (Virtual Production) & VFX vendors have been promised they can ‘take it home on the day, but these new problems mean shots need to go to post,” points out Ring. “We’re investigating toolsets to mitigate these problems as close to set as possible. We’ve already started this with our GENIO (Nuke / Unreal bridge) work, allowing you to easily pull UE render passes and cameras into Nuke, and you can also imagine a world where a real-time CopyCat is trained during the wall set-up and used to generate live mattes. All with the shared goal of giving you your final image that day.”
Foundry is also looking at workarounds for VP & Nuke around: ‘persisting’ decisions, wrangling on-set data, and conforming to a master shared timeline (“Timeline of Truth”). “As you might imagine, assembling and managing data is a more challenging problem than ML (possibly one of the most difficult problems in our industry) and is farther off, Ring concludes.
For more…
Ben Kent – Research Engineering Manager is presenting Machine Learning for VFX with Nuke and CopyCat, – Apr 15, 2021 @ 3:00 PM – 3:40 PM BST as part of GTC. Dan Ring will also be presenting at the RTC conference later this month more on Nuke & ML.