Wētā FX’s Face Fabrication System (FFS) provides a novel approach to utilizing neural networks for final facial likeness rendering that meets the quality demands and production rigor Weta is known for internationally. The system was designed to execute face replacements using imagery from a stunt performer to generate a similar corresponding image in the principal actor’s likeness, using neural rendering to produce the new image of the principal actor with perspective, lighting, and facial expressions within the specific shot context. It was used extensively on Shang-Chi and The Legend of The Ten Rings, and fxguide spoke at length to both the film’s VFX supervisor Sean Walker and the technology’s lead architect, Pipeline Supervisor, Jonathan Swartz (now Principle Software Engineer at NVIDIA).
For quite some time VFX artists have used 3D digital doubles and complex compositing to replace stunt faces with those of the leading actors. The process is complex due to matching lighting, expressions, skin textures, and other factors. Swartz and Wētā FX set out to provide a more reliable, faster, and visually authentic way of achieving this using the latest machine learning (ML). While many demo and experimental pieces have been done in the past, most require the main actors to be looking at camera in a forward-facing way, they are also not designed around the sort of pipeline issues that Wētā FX commonly deals with such as high resolution, complex visuals, and even high dynamic range.
When Wētā FX joined the VFX crew of Shang-Chi and The Legend of The Ten Rings,” Chris Townsend, Marvel’s senior visual effects supervisor for the show, came to me early on,” recalls Sean Walker. He said, “look, we are going to be dealing with some pretty hefty head and face placement throughout the show.” The issue was not due to the actor’s commitment to performing the fights, many were trained in martial arts in preparation for the film. “They looked great, but yet when we all spoke to the second unit directors and stunt coordinators, they would point out the difference between the great job the actors were doing and the actions of the 20-year trained professionals.” In an effort to get the last 5% to 10% of authenticity the creative team wanted to put the faces of the actors on the bodies of the martial arts experts. Chris Townsend actually brought up the notion of looking at some type of Deepfake technology. “He had seen it online and wondered if Wētā were looking into it or not,” recalls Walker.”We’d thought about it before. It’s just something that everyone in the industry at the time was thinking about. In end, I decided to just go for it.”

This was just prior to the pandemic so any remote working considerations did not factor into Wētā’s plans. Sean Walker brought some previz / fight viz, that the fight co-ordinator had made to Jonathan Swartz, to see if it would work. Jonathan was already looking into the broader issues of machine learning, but he did not have a working solution. Based on prior published papers and surveying open-source solutions, Jonathan then started work on developing Wētā’s own in-house Face Fabrication System. The first stage of his research was inspired by the work Wētā’s VFX supervisor had done previously in this general area, as well as the various strength and weaknesses of other neural rendering approaches. He then arranged with Sean to set up a test shoot with the team members of Wētā’s motion capture group in Wellington. The test had nine different cameras to film training data and some action plates shot handheld, at various angles and framings. To get indicative resolution and colorspace these included Red and Sony F55 cameras.
After a couple of months, the team had the first set of possible shots, and a document outlining the various approaches for capturing training data, FACS poses, and RoMs… “and then everything fell apart because a pandemic happened,” laughingly recalls Jonathan. As Sean did not even get on set, and the production was struggling to film anything given the various COVID protocols, the notion of filming extra training data on set somewhat fell by the wayside. Without training data, Jonathan was faced with two classes of problems. First, while the main actors were not going to be providing any bespoke training data, notionally he could access footage of them in other films and programs. The second problem was more complex. How to solve the stunt doubles’ training data, as there was no chance of accessing their previous work in a form, given the nature of final shots always hiding a stunt double’s face. To add to the problems the team faced, for unknown reasons, (compounded by Sean Walker not being able to be on set), in some scenes, someone thought it would be helpful to put dots on some of the hero actors faces. This is not an unreasonable move for traditional CGI, but worse than useless for ML. The only option was to paint out the dots using Wētā great paint and roto team.

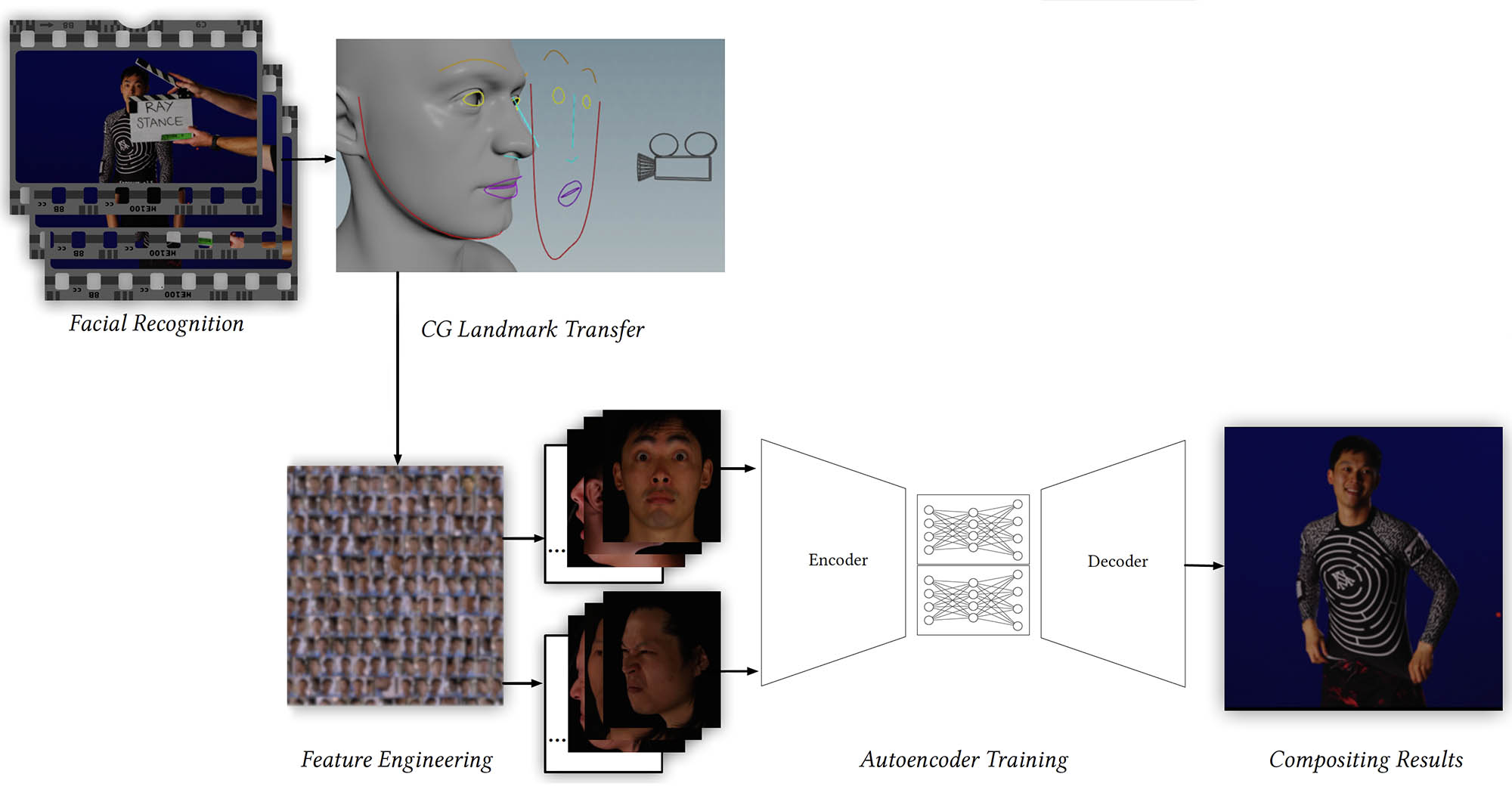
The primary training data solution for Shang-Chi and The Legend of The Ten Rings was for Wētā to use all the other clips they had from things such as witness cameras and match moving cameras, plus all the other out-takes and DLSR reference that is typically shot on any Marvel level film. These clips were in a vast variety of formats and far from the bespoke wish list of material Wētā had compiled in their VFX document prior to the pandemic. With this collection of different formats and sources, the team moved to building another ML tool that sat in front of any actual face replacement process. The new ML face recognition system allowed the team to scan large amounts of unedited and documented footage searching for any clips of the relevant stunt person or actor that was needed for that shot. This was needed as the problem the team faced had moved from, ‘we need this exact training data’, to ‘we need any training data’ to ‘we have too much footage and we now need to find the most relevant footage per individual’.
A common misconception with ML is that ‘more is better’ and this is not true. A key part of the art of advanced ML is providing the right or ‘pertinent and statistically valid’ training data, not just more data. “It went from a desert to an ocean of data,” Jonathan remembers “Initially, we were going to shut the whole ML project down, but by thinking about the problem from a different angle, we realized that there was so much we could harvest.”
Part of the ingest face-tracking program Jonathan built also allowed for metadata to be created which identified what colorspace each clip was in, the names of all the actors in the shot, etc, and catalog the information into a format for easy access when the production needed it. In many respects, this approach was at odds with the way a Wētā project normally works. Wētā is normally very exact in documenting and cataloging on set imagery and having everything extremely well organized. But COVID-19 circumstances turned this into a process of just grabbing anything and worrying about solving it later, which is a very un-Wētā like approach to VFX. It also challenged even the internal data structures for storing footage, which assumes relevant footage is stored on a scene or shot basis. With FFS, the process cuts across all those film-making assumptions. Nor is ML training data concerned with temporal consistency, it may use 10 frames from one shot, 2 frames from another, and 1200 non-continuous frames yet another, etc.

Having gotten the facial recognition ML working, Jonathan returned to extending Wētā implementation for the primary face replacement. The basic original algorithmic approach in Shang-Chi and The Legend of The Ten Rings project was very similar to DeepFaceLabs. It used a similar Variational Autoencoder (VAE) model, but Wētā’s own ground-up implementation of the principle, – further extended to build on the additional data that Wētā’s VFX pipeline had available.
In contrast to the more standard uses of neural networks as regressors or classifiers, VAEs were at the core of many early ML face replacement approaches due to their powerful generative models. A VAE network is a pair of two connected networks, an encoder, and a decoder. An encoder network takes in an input and converts it into a smaller, dense representation, (a continuous latent space) which the decoder network can use to convert it back to complete the inference. See our fxguide story for more on the history of VAEs here.
A lot of the open-source implementations using VAEs are gathering face data by using another ML model to identify a face and to produce an alignment of the face, which is one of the key early steps. A problem is that this approach often fails as soon as the face turns side on to the camera. “They often don’t have enough training data for some of the ways they align the face, so their solutions become very unstable,” explains Jonathan. “We improved the stability of our process, as we have our own VFX toolkit for the shots that match moves as a normal part of our VFX pipeline.” Part of the FFS project became working out how to blend this traditional pipeline into the new FFS ML process and utilize all the information that Wētā current VFX pipeline generates as data about facial alignments. With this additional traditional data, Wētā’s FFS can align and solve a wider range of face positions than most open-source solutions. “In order to do any facial recognition, we need the faces aligned in the consistent space, similar to most neural rendering approaches. Our process produces landmarks of important facial features to aid in orientation”. The Wētā FFS solution added other innovations in this regard. For example, it compares facial markers between frames and if the markers have moved a lot, then it is likely that the faces would be blurred due to motion blur. Thus not only does FFS recommend frames as training data but it also culls out frames that would negatively contribute to a ML solution space.

To aid in this, the team built a node graph database, built on variant of the open-source Neo4j, that stored not only the location of all the relevant frames but all the important metadata with the source colorspace, spatial identification and recognition tags, orientations, and everything else required to easily build training data sets. “We would look into this database for the correct faces that are similar in orientation to the ones we’re interested in replicating for a shot. We would overfit a model to train, based on that training data set, that would service that shot or group of shots.
Even with the complex data management that was implemented, the demands on getting adequate training data were harsh. The workaround was to produce an interim step. In the simplest terms, the FFS produces a 3D face using the normal non-ML Wētā pipeline. Using their normal complex tracking and compositing, this 3D face was positioned appropriately in the shot and then the FFS trained on this 3D head rather than the actual person’s face.
In this approach, the 3D head does not need to be perfectly lifelike in texture and render qualities as the ML inference will replace it anyway. But if the 3D head is used appropriately, the ML can be very high quality, as it is easy to produce as much 3D head training data as is wanted. In effect, the approach deemphasizes the training requirements on the stunt actors’ faces as it uses what is referred to as ‘synthetic data’ to produce ample training data. Not forgetting that the 3D face it will be replaced in the final shot anyway. The CG digital double in this approach is only used as an interim stage. Plus it can also be rendered or inferred without motion blur, which produces a clean high resolution new output face, ready for motion blur to be added in comp.
Another Wētā refinement was the precise nature of the blur a face might have in any shot. As a rule, ML can train on blurry faces and infer new blurred faces, but as any high-end compositor knows, motion blur is a very specific type of blur. Inferred motion blur tends to produce a blur that is more akin to a convolution filter (or an averaging) blur and not the highly accurate directional motion blur that perfectly matches a 180-degree camera shutter artifact.
It is often difficult to avoid inferred ML faces from being perceived as soft anyway and not as sharp as one might like. Sean and the team, therefore, decided to try and produce all the inferred faces as sharp imagery and then accurately blur them to match the plate photography in comp. An additional benefit is that this allows for additional VFX control on the performance of the stunt person. Their final performance can be tweaked or adjusted via the interim CG face. As once a technical match is made, there is nothing stopping the face from being animated for additional performance characteristics. The synthetic training data approach with digital doubles is extremely powerful in a face replacement pipeline.
As with any face replacement pipeline Wētā needed to deal with occlusions and obvious things such as hands or props going in front of faces during fights. This is an issue for both the training data and for inferring a final shot. FFS has a mask that moves with the shot, that way the neural network can “identify pixels that are components of the face versus components of a hand or a sword or hair, -things that might come in front of the face,” comments Jonathan. And for the final actual shot, “the final hero neural rendering network is learning both how to reproduce the face, but also how to segment the image of the face into pixels that it knows we’re going to be replacing.” this means the compositors don’t have to take the raw neural network and paint out elements or manually roto everything.
The team that took Jonathan’s ML work into production was critical in producing the actual shots in Shang-Chi and The Legend of The Ten Rings. Karl Rapley was the Animation Supervisor and he worked closely with Sabine Laimer, the Compositing Supervisor, and the film’s compositing team. “Everyone was great, – I particularly collaborated with Alex Berson on validating the approach and with Simon Coles who assisted training models and running the shots,” Jonathan recalls.
For the majority of shots, the work could be characterized as ‘face’ replacement, but Sean Walker noted the importance of not only considering the face region but the person’s entire skull shape. “This was a huge reason for us to implement the ‘digi-head’ approach,” he remarked. “We had two main stunt performers, Sunny and Zach. Zach had a reasonable match in regards to skull shape, and he is who we used a lot in the bus fight.”
Sunny however had a different facial relationship between face and forehead and overall head shape. “It was Sunny who was used a lot in the final battle and when you have someone with a relatively small face compared to the source actor you get problems. The difference between Sunny’s large forehead and Tony’s evenly proportionately face meant that you sort of shrink down all the landmarks during landmark matching. This then gives a result that essentially looks a bit like a shrunken head.”

Some of these facial differences are just related to age, human faces change over time in terms of the relative size of key facial features as someone ages. For example, someone’s nose and ears get larger relativity, compared to when they are younger. In this case, actor Tony Leung Chiu-Wai is 59 and his stunt double was a much younger man. To solve this, the team came up with a type of 2D warp “that moved the image between the facial features of our stunt double to the facial features of our hero guy,” Jonathan explains. “We jokingly called this our SnapChat filter – but we will definitely need to come up with a much better name for that!”
Essentially the ‘SnapChat’ process adjusts the features of the stunt double to look more like the hero actor “and immediately their ‘looks-like-them’ meter goes way up, even before the neural rendering. In the case of the end fight shots of Tony, it moved his chin in, his mouth around somewhat, and when we feed that into the neural network and the new ML results look much better.”
Another change in work practice is how different ML is in inferring work-in-progress results. There are no temp versions that look correct but are still un-textured like with CG, there are no old school wireframe or grey-shaded OpenGL versions to evaluate along the way. “I just couldn’t show Sean anything. I couldn’t show him progress faces or if I did, -it would just look just looked pretty horrible. Until things lock into place, and I have trained the model correctly, there is nothing helpful to look at,” Johnathan points out. “Working with ML requires the VFX supervisor to view incremental work from an entirely different perspective.”
While the work was rendered on Wētā’s Renderfarm, it was rendered on the GPU section of the farm, and shots were not split across computers. The shot work was distributed for training but with one model per machine. While some processes could run on CPU, for Shang-Chi and The Legend of The Ten Rings, the team used, “very big NVIDIA cards in our farm,” Jonathan comments. He personally used a 48Gig, A6000 NVIDIA card for his development work.
Not all the training models had to work from scratch in production. “We were not training them from noise to faces. We would pre-train a model with the settings that we anticipate using in production on a bunch of random research data faces, from a public data set of faces,” explains Jonathan. Wētā’s FFS would pre-train the network with the settings for approximately a week to get the activations of the convolution layers to at least understand features of human faces, generically. At this stage, the process ‘understands’ eyes and mouths approximately. “Then that would allow us to take that pre-train model and sort of birth little baby models from it that could be trained for specific pair of identities for a specific shot in a day or overnight.” So the FFS would pre-trained a model for weeks, but the process from a production perspective zeros out the bottleneck of the autoencoder, and the production team can just train on the faces for the shots they need.
The process ended up working extremely well. In filmmaking, the process delivers something that is plausible and has fidelity to the performances and respect for the performances but cannot be considered a perfect mathematical solution. the performance the audience sees is extremely realistic, but it is a combined interpretation of two performers inferred to look believable.
“I’m really digging this new FFS. It’s something that we’re looking into further for the next couple of shows that I’m working on,” says Sean Walker “I really feel there’s something there that will really help, just get through the sheer amount of work that we need to do these days. Actually, I’m banking on it and I think the technology is just getting better and better.”
Wētā FX will be presenting their work on FFS at SIGGRAPH 2022 in Vancouver in August