Until recently Neural Rendering (NR) discussions were dominated by ‘Deep Fakes’. The notion of fave swapping that first appeared with fake celebrity porn clips on Reddit and then moved to political satire. Quickly the term DeepFake grew to encompass not only face-swapping with Machine Learning (ML) but a whole raft of problems including fake news, and general misinformation none of which had anything to do with the underlying brilliant advances in Variational AutoEncoders (VAE) and Generative Adversarial Networks (GANs). Neural Rendering bridges the domain gap between CGI faces and photo captured imagery. While leading VFX companies are producing exceptional work, traditional technology often relies on expensive and dedicated 4D capture devices, such as Medusa, Light Stages, etc, as well as talented and complex human artistry. By allowing for digital human performances or ‘inferences’ at scale, NR is well suited to solve real-world problems and applications.
While the popular press may have focused on this broader and frankly unrepresentative use of Neural Rendering, the actual adoption of AI-generated video has skyrocketing especially in the enterprise or organizational context. Synthesia has successfully placed conceptual distance between themselves and the morally and ethically questionable Deep Fakes of 2016/2017. This year, mainly since May, Synthesia in the UK has generated more than 6 million unique neural rendered videos for thousands of clients, ranging from global corporations to small businesses. (Update: as of 2023 this is now 12 million videos). Perhaps then it is no surprise that the company has just secured another massive round of finance.
Synthesia now operates the world’s largest AI video platform and has just secured a $50M Series B financing round led by Kleiner Perkins with participation from GV (Google Ventures) and all existing investors. The round is the largest investment to date in the synthetic media space. This builds on their $12.5M Series A financing round in May 2021. (Update: In 2023 the company received $90 million in round C funding).
Synthesia’s clients include EY, who use Synthesia for client communications, and WPP, who use Synthesia for personalized training for their 50,000 employees. Synthesia also powers celebrity campaigns such as Malaria No More with David Beckham or Lay’s Messi Messages. The latter is shown below. In this Lay’s campaign, every video is individualized to the names of the viewer. The footage looks so real it is hard to not believe it is traditional video.
Traditional methods of producing video and audio are expensive, cumbersome, and require specialists. It is impossible to keep the content library up to date, Synthesia closes that gap. “With Synthesia, anyone in the enterprise can generate video directly from their browser. No need for cameras, studios or actors. You simply select an avatar, type the script, hit generate and the video is ready in a few minutes,” comments Victor Riparbelli, Co-Founder and CEO of Synthesia. “For our thousands of customers, it is transformational to enable anyone in the company to produce uniform, on-brand video content for everything from internal training to personalized sales prospecting.”
One of the most popular features of Synthesia is the ability to create one’s own AI avatar by submitting roughly 5 minutes of video content. More than 35 partners at EY now have their own avatars that they use for both internal communication and as a part of the customer-facing process.
In the test demo above, fxguide’s Mike Seymour introduces two fully digital versions of himself. The videos were authored in his office, on a laptop, and were based on training data we shot a couple of days ago. For the training clips, Mike was filmed delivering the same short script several times. The actual production of any new neural rendered clip is then inferred from this training data in a couple of minutes. Backgrounds, animation, and even music can be added as part of this process. The final output clip is pre-comped and ready to be used immediately.
Synthesia’s first commercial product, Synthesia STUDIO launched in public beta in the summer of 2020 and it has seen several significant upgrades already. The company aims to replace cameras with code and scale its AI video generation platform. Their focus is not on high-end M&E but rather they are aiming at producing vast amounts of video content without needing to film actors. When the company started in 2017 however most investors and people only saw the potential downsides of AI video. “The term ‘deepfake’ comes mostly with negative connotations. In the last couple of years, we – and other great companies, have proven just how beneficial this technology is in both consumer and enterprise applications.”Riparbelli adds. While Synthesia recognizes the potential risks of AI video, they are committed to the ethical implementation of synthetic media. The company doesn’t synthesize anyone without explicit consent and the technology is only accessible via an on-rails experience that is fully controlled by Synthesia.
Neural Rendering

In the CVPR State of the Art on Neural Rendering paper (2020), NR techniques are defined as ‘deep image or video generation approaches that enable explicit or implicit controls of scene properties such as illumination, camera parameters, pose, geometry, appearance, and semantic structure.’ NR goes beyond simple ML approaches and encapsulates controllable digital human generation. The ability to direct the rendering process with artist control allows for a huge range of applications beyond just face swapping, such as dialogue replacement, look manipulation such as digital makeup/de-aging, facial and body re-enactment, relighting, and free-viewpoint videos. Many of these we have covered in previous fxguide stories such as Welcome to Chechnya. Ryan Laney in that documentary feature worked with the filmmakers to use NR as a novel technique to protect the identities of members of the LGBT population filmed in the Russian republic of Chechnya.
It is easy to imagine that companies such as Synthesia would have possibly been funded to a much greater extent even sooner if it were not for the problem of people thinking their technology is somehow related to DeepFakes. This is grossly unfair to the company and its researchers. Naturally, the company uses NR to produce digital humans, but the results are inferred from very specific training data of an actor and not based on swapping identities, scraping data from social media, or targeting people unknowingly. Their solution is used to infer entirely new performances. The end goal being to make films using just code, and not cameras. While this goal may seem far off a narrative film, it is already very viable for a simple speech to camera, such as used in training videos. But the company already offers APIs to allow companies to produce their own version of something similar to the Messi campaign.
Background: Deep Fakes AE and VAEs
The earliest approaches to automatic face replacement used ML to just find the best match to a single image and then blend it, and incorporated 3D morphable models, but this all changed in 2016. We spoke with a range of experts about the background of this technology, including Johnathan Swartz and Andrew Glassner at Weta Digital, Hao Li and Zejian Wang at Pinscreen, Thiago Porto in NY, Koki Nagano at NVIDIA, and others for this article. All these professionals, who are involved with the ethical use of Neural Rendering, contributed to piecing together how the original work unfolded. None of these experts use or publish malicious Deep Fakes, they are all just experts in Machine Learning and Neural Rendering approaches.
The original term ‘deepfakes’ comes from a machine learning engineer whose avatar name was DeepFakes. Only one journalist is known to have directly spoken to Deepfakes, Samantha Cole. She wrote the original VICE article about the phenomenon entitled “AI-Assisted Fake Porn Is Here and We’re All F*cked“. In that article and subsequent TEDx talks, she outlined how the ML engineer thought there are nothing wrong with stealing the identities of people and placing them in porn. She also somewhat implied his original work was based on that of a paper from NVIDIA. It was not, the original Deep Fake post, if you examine the (non-deleted) code uses autoencoders (AE). The NVIDIA work points to Generative Adversarial Networks (GANs) and other technology that has only more recently been heavily adopted by NR researchers. In fact, many general NR researchers still believe the original approach involved Variational Autoencoders (VAEs), which only become popular over a year later.
The original approach is believed to be based on Korshunova et al (2016), which used a convolutional neural network (CNN). A CNN is based on a convolution which is a mathematical operation on two functions that produces a third function expressing how the shape of one is modified by the other. Central to AEs is the idea of finding the ‘latent space’ which ‘hidden’ from view but allows an image to be encoded and then plausibly decoded (lossy). The Korshunova et al paper (see below) is based on this idea of encoding and decoding, inside a system of facial identification and transforms.
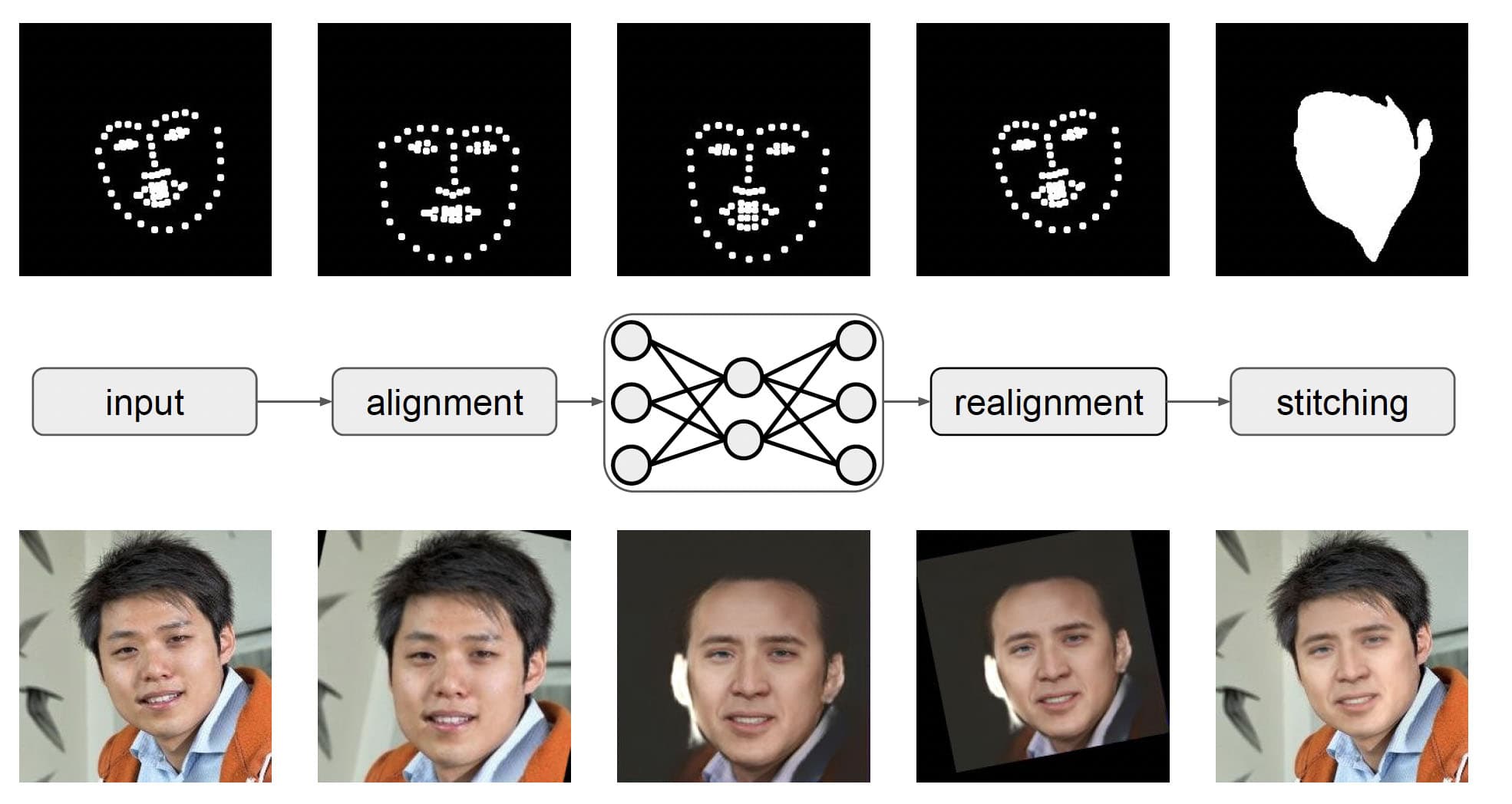
Many of the basic ideas in use today in newer NR face-swapping techniques share basic characteristics from this work. The original research was subsequently extended, and an open-source platform for practical deepfakes, called Faceswap. Faceswap was a more packaged version intended to be OpenSource and aid in the wide distribution of NL face-swapping.
 From the original AE approach, the focus shifted due to researchers such as Pushmeet Kohli, to variational autoencoders (VAEs). Faceswap forked on GitHub into DeepFaceLab, released by Ivan Petrov in 2018. It is believed that most celebrity face swaps in circulation on platforms were created with DeepFaceLab, Petrov himself estimates that 95% of Youtube face-swaps use DeepFaceLab. There is no question that for facing the camera NR face swaps, DeepFaceLab can produce outstanding results, with perhaps the popular example being the Deeptomcruise series by Chris Ume, which we featured earlier this year.
From the original AE approach, the focus shifted due to researchers such as Pushmeet Kohli, to variational autoencoders (VAEs). Faceswap forked on GitHub into DeepFaceLab, released by Ivan Petrov in 2018. It is believed that most celebrity face swaps in circulation on platforms were created with DeepFaceLab, Petrov himself estimates that 95% of Youtube face-swaps use DeepFaceLab. There is no question that for facing the camera NR face swaps, DeepFaceLab can produce outstanding results, with perhaps the popular example being the Deeptomcruise series by Chris Ume, which we featured earlier this year.
It is worth noting that early face replacements often had often difficulty generating high-resolution imagery due to memory limitations, lack of high-res training material, or failure to blend lighting and skin texture, with the results appearing blurred or lacking in matching skin tone. DeepFaceLabs has been successful at addressing these issues, but it is still primarily beneficial when the source and destination actors are facing the camera. Other versions that have been published have exhibited temporal instability, meaning that they looked acceptable on still frames but showed flickering on moving clips.
The original DeepFakes used a traditional AE architecture trained on pairs of images of two identities, in a stunningly simple but effective way. DeepFaceLab’s approach uses a dual Y-shaped autoencoder implementation. In its most recent network design, DeepFaceLab uses LIAE (Lightly Improved Auto Encoder) incorporating two distinct latent space constraints, that have the features of both faces fed to it and the other of only the destination face. These approaches share both encoder/decoder (InterAB).
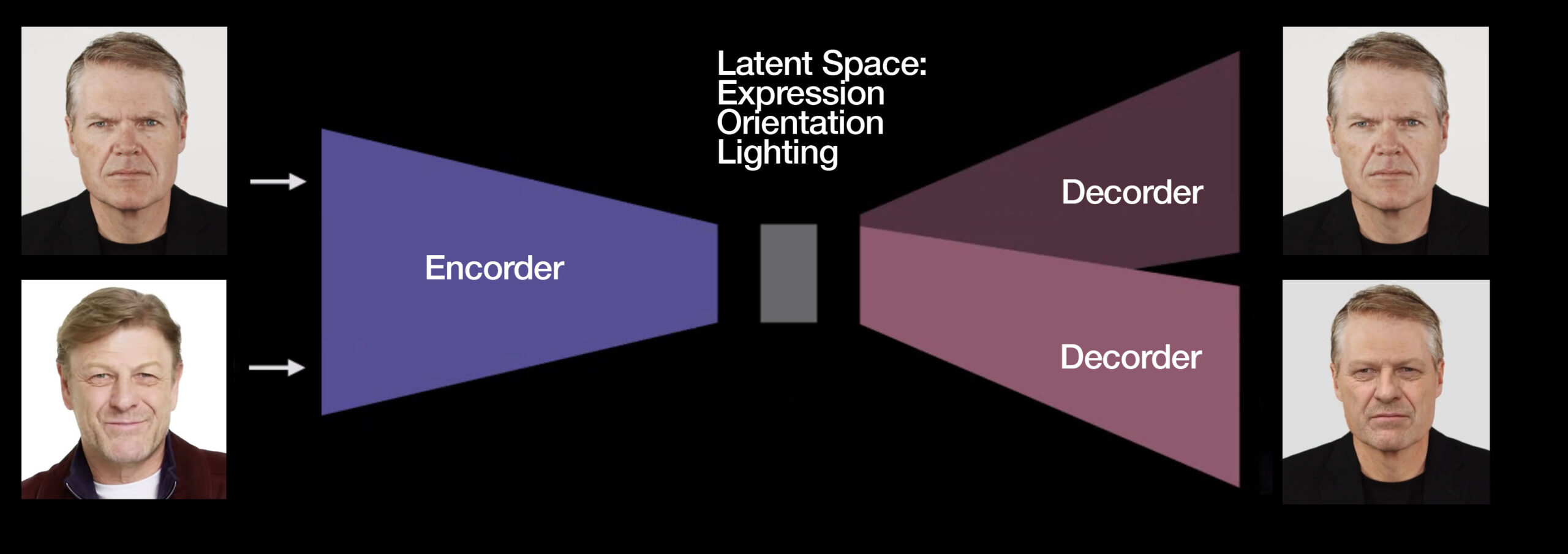
Today VAEs are used with other things such as GANs but the concept and approach are primarily based still on finding the latent space that describes the face and assigning characteristics from the underlying face to the new face layered on top. Note, in face swapping, the faces are statistical inferences from two very specific people. The ability to perturb the feature vectors in some way that produces a continuously interesting result is not their goal. These approaches seek to match like-for-like lighting, orientation, and expression of one face with the identity of another.
GANs
Another highly successful NR approach has been to infer people based on the brilliant work of Ian Goodfellow. In 2014 Goodfellow wondered what would happen if he designed a network that pitted two neural networks against each other? The idea is that one AI engine is a ‘counterfeiter’ and the other a ‘Cop’. The two are adversaries, with the counterfeiter trying to beat the cop in detecting a ‘fake’ but also importantly learning from what works and what does not. Reportedly, Goodfellow coded into the early hours and then tested his software. It worked the first time. The GAN technique he invented that night has sparked huge excitement in the field of Ai and ML and turned its creator into somewhat of an AI celebrity.
NVIDIA has done exceptional work with GANs and produced remarkable results. Both StyleGAN and StyleGAN2 are landmark papers that show the power of being able to infer a completely new person from a statistical training data set.
Adobe is also a key user of GANs and ML, and the company is now constantly adding new Neural Rendering or Sensi additions to programs such as Photoshop.
ADR
Founded in 2017 by technology entrepreneurs Victor Riparbelli, Steffen Tjerrild, and professors Matthias Niessner and Lourdes Agapito, Synthesia today is focused on reducing the friction of video creation and making it possible for anyone to create professional-looking videos in minutes, directly from their browser.
When Synthesia first came out of stealth mode as a startup in 2018, they offered their services for professional face replacement to seamlessly change a presenter or actor’s expressions and dialogue. Synthesia wasn’t aiming to produce throw-away or comic illusions, they are seeking to address existing production problems in language dubbing and Automatic Dialogue Replacement (ADR). ‘Native dubbing’ was their initial method of translating video content that utilized ML to synchronize the lip movements of an actor to a new dialogue track.

This work built on the breakthrough research of co-founder Prof. Matthias Niessner who was one of the key researchers behind Face2Face: Real-time Face Capture and Reenactment of RGB Videos, a landmark face replacement tool that many saw as a key point in digital facial ‘puppeteering’ technology.

This was first shown in the Emerging Tech Hall at SIGGRAPH 2016 and it immediately captured huge interest. The initial results in the academic literature showed the potential but didn’t match the visual fidelity or reliability required to be production ready.
To show the power of this technology Synthesia embarked on a program of producing one bespoke project a year as a part-promotion, part-technology test. The first of these was an Anti-Malaria spot with David Beckham.
This spot had Beckham speaking in a variety of languages and proved the quality of Niesser’s work could be of the highest broadcast quality. The Synthesia process at this time was based on ML with Convolutional Neural Networks (CNN) and the training alone could take 12 hours or more. The exact internal technical approach was not published but the Synthesia ADR process did employ a GAN, using CNN Deep Learning.
This original focus however shifted from face replacement to the creation of full digitally inferred people, although other companies are now separately establishing processional pipelines for film ADR – AI Dubbing. From this original ADR Sythnesia has moved to generating completely new clips of people and actors, believably delivering lines directly to camera.
“We’re already hosting thousands of custom avatars and are seeing this number rapidly increasing. Just like most of us are now accustomed to being on live video calls, we’re certain that in the next 5 years we’ll see AI avatars become more commonplace in business communications,” said Riparbelli.
With the new funding, Synthesia will focus on accelerating commercialization while also investing heavily in the long-term research required to fully realize its vision of synthetic media over the next decade. “In the short term, we’re focused on building out functionality to help our customers create and distribute content at lightning speed, either via our web app or API,” Riparbelli explains. “Ultimately, we’re an AI company. Looking into the next decade of Synthesia, we’re building for a future where you can create Hollywood-grade videos on a laptop. On our way there we’ll be solving some of the hardest and most fundamental problems in AI and computer vision.”
With the new funds, the team will be investing deeper in advancing their core AI research while in parallel slowly opening up some of their research to the world and beginning to actively contribute to the broader research community.
The company is now building a London-based studio to capture detailed 3D human data at scale. This will be the first step towards expanding from the front-facing video content its platform can generate today, to building a platform that eventually will enable the creation of full scenes and movies.
Ethics.
While Synthesia recognizes the potential risks of AI video, they are committed to the ethical implementation of synthetic media. The company doesn’t synthesize anyone without explicit consent and the technology is only accessible via an on-rails experience that is fully controlled by Synthesia. The company is also a signatory to Adobe’s Content Authenticity Initiative, to ensure that synthetic media is deployed ethically.