
NVIDIA Omniverse is an open platform built for virtual collaboration and real-time physically accurate simulation. It was released as an open beta in Dec 2020. Designers, animators, creators, and VFX teams connect major design tools, assets, and projects for collaborative iteration in a shared virtual space, all built on the core foundation of USD, Universal Scene Description, originally developed by PIXAR but now being adopted across multiple industries using 3D.
“USD provides a common foundation for describing everything in a 3D scene”, according to Richard Kerris, General Manager of Omniverse and Head of Developer Relations at NVIDIA and a former CTO at Lucasfilm. While the Alembic file format (co-developed by Industrial Light & Magic & Sony Imageworks and launched at Siggraph in 2011) contained most of the file information about a 3D model, with USD, “you get all of the elements of the 3D environment”. “You can think of it as the HTML of 3D,” he adds. “It brings with it, the lighting, the shading, the materials, and so on.” Alembic was a step towards that, and a precursor to USD “But what was really needed is the ability to bring everything from one 3D project to another 3D project,” Kerris explains. USD is at the very core of Omniverse, and NVIDIA has built an entire set of tools and core technologies around USD that is truly jaw-droppingly impressive.
NVIDIA continues to advance state-of-the-art graphics hardware, and with their AI R&D strength and the depth of Omniverse, the company is now able to really show what is possible with real-time ray tracing and intelligent systems. “The potential to improve the creative process through all stages of VFX and animation pipelines will be transformative”, comments Francois Chardavoine the current VP of Technology at Lucasfilm & ILM.
Audio2Face (Early access)
 One of the applications built as part of Omniverse that has just been released in open beta is Audio2Face, a tool that simplifies the complex process of animating a face to an audio input. Audio2Face was developed as an Omniverse App, which sits on the platform and brings its capabilities to other applications integrated into the workflow. The input is any popular audio file such as .wav or .mp3. and the output is realistic facial animation – either as a geometry cache or as a live stream.
One of the applications built as part of Omniverse that has just been released in open beta is Audio2Face, a tool that simplifies the complex process of animating a face to an audio input. Audio2Face was developed as an Omniverse App, which sits on the platform and brings its capabilities to other applications integrated into the workflow. The input is any popular audio file such as .wav or .mp3. and the output is realistic facial animation – either as a geometry cache or as a live stream.
Audio2Face is an AI-based technology that generates facial motion and lip-sync entirely from an audio source. Audio2Face offers various ways to exploit the technology – it can be used at runtime or to generate facial animation for more traditional content creation pipelines. Audio2Face also provides a full character transfer pipeline providing the user a simplified workflow that enables them to drive their own characters with Audio2Face technologies.
Above: Fxguide’s Mike Seymour tests Audio2Face with his Australian accent!
Audio2Face simplifies the animation of a 3D character to match any voice/audio track. It is not aimed at the highest end animation of feature films, and yet it provides excellent lip-sync animation characters in games, NPC background characters, or for real-time digital assistants. Users can use the app to make interactive real-time applications or work offline and export caches for use in a traditional facial animation pipeline. Audio2Face can be run live or bake in and exported out, it’s up to the user.

Audio2Face rose from a set of meetings in around 2018 when multiple game developers came to NVIDIA and said “Hey, you know, the scale of our games is now so huge. What can NVIDIA do – maybe with the help with deep learning or other technology, to help accelerate and meet these production demands?”, explained Simon Yuen, Director of Graphics and AI at NVIDIA. At that time it was not uncommon for a game development team to be in motion capture for two and a half years straight, just for one game. These realistic production problems plus the general difficulty (time consuming, labor-intensive process) of creating high-quality 3D facial animation “led us to start thinking about how to solve these problems. We want to come up with a solution that can accelerate and simplify speech-based facial animations.” he adds.
The straight output of Mike’s audio to the default face, note this version does not yet have active eyes.
The application uses the RTX Renderer as Audio2Face is a part of the Omniverse framework. It is not intended as a demo application, it is a tool to allow developers to build serious applications. For example, it is to be expected that this will be integrated with Epic’s UE4 Metahumans, allowing for Audio2face to drive UE4 characters in real-time. Omniverse facilities the round-tripping of assets in and out of programs such as UE4 and Autodesk Maya. Audio2Face can currently export either as a Maya cache or a USD cache. Richard Kerris points out that before committing to specific pipelines with partners such as Epic Games, NVIDIA wants beta customer feedback which plays a critical role in the development of the Omniverse platform. For Audio2Face to succeed it needs to do so by allowing developers to build it into more complex pipelines. Kerris sees this close feedback from customers as a primary goal for the team following the Early Beta release.
The Audio2Face program is now in open beta, but this is only a preliminary preview, there are many features still to come or just about to be released. For example, Audio2Face has a set of post inference controls that allow you to adjust the resulting poses of the output animation based on trained data, this allows you to fine-tune the amplitude of your performance among other things. There will also be ways to allow the user to change or combine different emotions to fine-tune the character’s expressions and responses. These will all be able to be animated on a timeline allowing users to fade in and out of emotions such as amazement, anger, disgust, joy, pain, etc in a future release.
Later releases will include more detailed audio-driven features including:
- eyes and gaze
- teeth and tongue
- head motion (nods etc), using a joint structure – all driven by audio.
- Plus, high-level controls so you can quickly direct the mood and emotion of the character.
All driven by audio with additional user controls. The goal is to use a very simple interface to get a complete high-quality performance without a lot of the work you have to do traditionally in CG.
Some of the leaps of plausible behavior are nothing short of remarkable. Just to underscore this point: NVIDIA Research is using machine learning to produce plausible animation of what a character’s eyes are doing based on audio waveforms alone! “We’ve trained the eyes so that they do a natural saccadic movement, and you can then both control or amp that up if you need. You can have offsets if you want on top of that to control where the character looks,” explains Yuen.
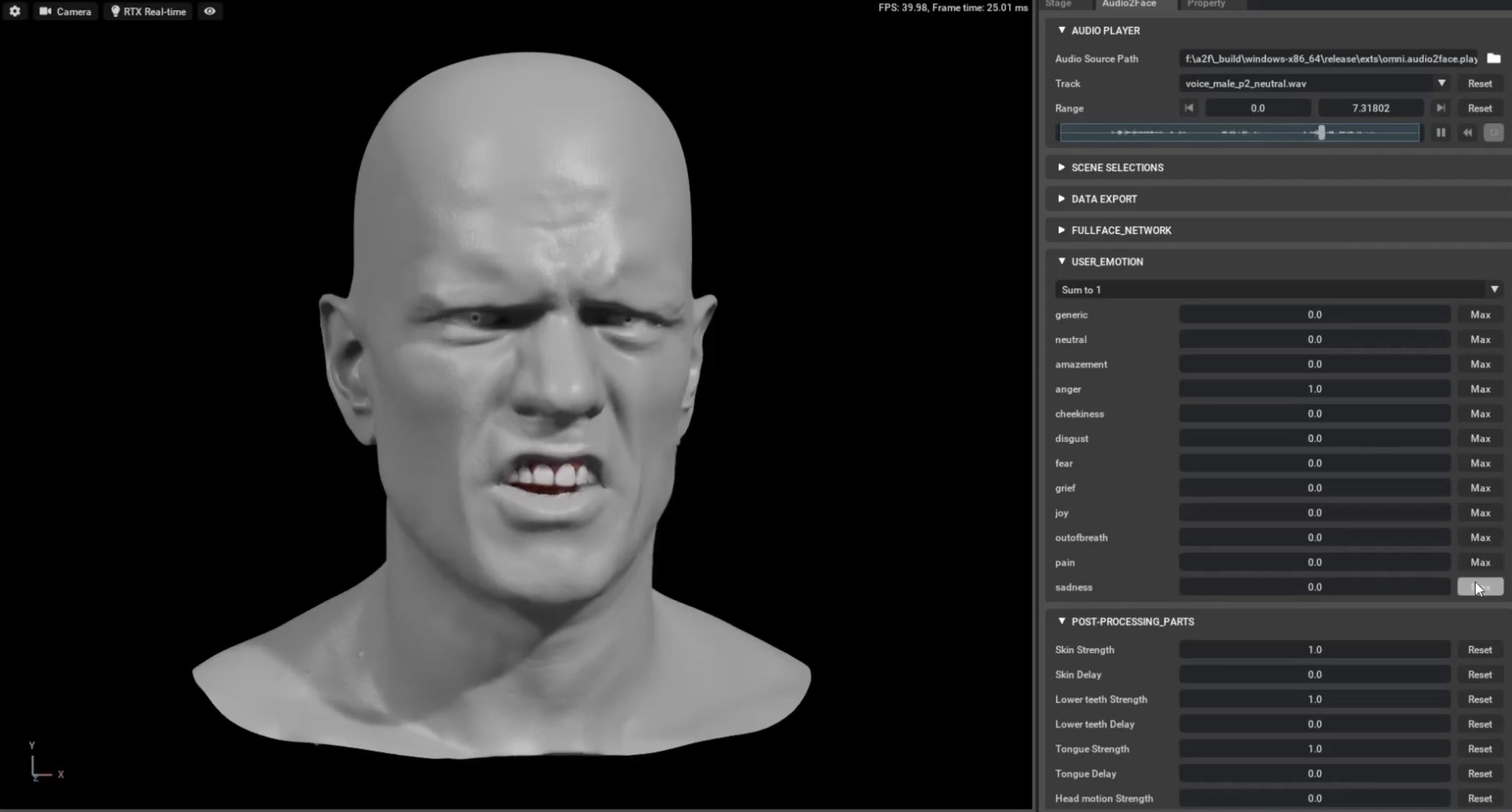
In a future release, the emotions of the characters can also be mixed. “Think of a combination of FACS poses embedded in a neural network so you don’t have to drive each FACS shape individually for the common laborious and expert required workflow,” says Yuen. “We are looking at how we can mix and match emotions to get the performance we need.” The system animates not just the face skin of a character but the full face, eyeballs, eyelids, head motion, teeth, tongue, and neck. All of these aspects are controlled by the audio-driven animation and moderated by the emotional vectors.
 Yeongho Seol, Senior Developer Technology Engineer, demonstrated emotion control at GTC 2021. The data collection for the ML training data was based on 4D facial performance capture with synced audio. This included speech performances with various emotional states. Along with reference images and casts of the actor’s teeth, the NVIDIA team built a complex high-end 3D baseline 3D model to train the deep neural network.
Yeongho Seol, Senior Developer Technology Engineer, demonstrated emotion control at GTC 2021. The data collection for the ML training data was based on 4D facial performance capture with synced audio. This included speech performances with various emotional states. Along with reference images and casts of the actor’s teeth, the NVIDIA team built a complex high-end 3D baseline 3D model to train the deep neural network.
Audio2Face is one of many applications of NVIDIA’s AI SDKs. Another team is working on new advanced text to speech (TTS) APIs and building blocks which NVIDIA CEO Jensen Huang flagged in his keynote address at the 2021 GTC conference, commenting on no more computer-sounding voices. NVIDIA has an entire framework for conversational AI from Automatic Speech Recognition and Natural Language Processing to Text-to-Speech (TTS) with voice synthesis using Mel Spectrograms. NVIDIA released Jarvis 1.0 Beta which includes an end-to-end workflow for building and deploying real-time conversational AI apps, such as transcription, virtual assistants, and chatbots at the end of February 2021.
NVIDIA GANverse3D
Developed by the NVIDIA AI Research Lab in Toronto, lead by Sanja Fidler the GANverse3D application inflates flat images into realistic 3D models that can be visualized and controlled in virtual environments. This new deep learning engine for creating intelligent 3D object models from standard 2D images recently brought the iconic car K.I.T.T. from Knight Rider back to life in NVIDIA’s Omniverse. This research is from the same team that last year presented GameGAN (see our fxguide story), an AI-powered version of PAC-MAN that can be played without an underlying game engine.
Differentiable rendering has paved the way for training neural networks to perform “inverse graphics” tasks such as predicting 3D geometry from monocular photographs. The single jpeg does not produce a highly complex model by VFX standards, but it does produce a fully 3D car, with no 3D modelling software or experience required. As it is done via machine learning, the model has moving wheels and one can animate or ‘drive it’ around a virtual scene, complete with realistic headlights, taillights, and blinkers (note: headlight effects were a post-process step). The process of going from images to 3D is often called “inverse graphics” since the problem is inverse to the process of rendering a 3D scene by taking into account the geometry and material properties of objects, and light sources present in the scene. This means the certain properties of the car are inferred, even when not seen. For example, the hidden side of the car is plausibly created even though the far side of the car is hidden in the photo.
To generate a dataset for training, the researchers harnessed a generative adversarial network, or GAN, to synthesize images depicting the same object from multiple viewpoints — like a photographer who walks around a parked vehicle, taking shots from different angles. These multi-view images were plugged into a rendering framework for inverse graphics, the process of inferring 3D mesh models from 2D images. NVIDIA GANverse3D uses the previously published NVIDIA StyleGAN as a synthetic data generator, and the process labels this data extremely efficiently. This “dataset” is then used to train an inverse graphics network to predict 3D properties of the objects in the images. As it uses StyleGAN, this approach produces higher quality 3D reconstruction results while requiring 10,000× less annotation effort for the training data, making it very useful in production.

To recreate K.I.T.T., the researchers simply fed the trained model an image of the car, letting GANverse3D predict a corresponding 3D textured mesh, as well as different parts of the vehicle such as wheels and headlights. They then used NVIDIA Omniverse Kit and NVIDIA PhysX tools to convert the predicted texture into high-quality materials that give the digital KITT a more realistic look and feel allowing it to be placed it in a dynamic driving simulation sequence.
Once trained on multi-view images, GANverse3D needs only a single 2D image to predict a 3D mesh model. This model can be used with a 3D neural renderer that gives developers control to customize objects and swap out backgrounds. For example, the tool has been used to produce horses (quadrupeds) and birds. But the program has limits, it would not be able to produce a complex quadruped walk cycle for example. “We would have to infer a bone system to do that,” explained Professor Sanja Fidler who worked on the project and leads NVIDIA’s Toronto Research. Fidler also outlined that the team is looking next to do a similar process for human faces, “but that problem is considerably more difficult.”
The ability to infer 3D properties such as geometry, texture, material, and light from photographs may prove key in many domains such as AR/VR, computer vision, and previz/scene mock-ups. The current system was trained on 55,000 images of cars, with fewer images for the birds and horses.
 Given input images (1st column above), GANverse3D then predicts 3D shape, texture, and renders the object from the same basic point of view (2nd column). The image is now 3D as shown in the Multiple Views (3rd) column. The process is able to reconstruct hard surfaces with specular highlights and also more difficult articulated objects, such as birds and horses. But while some spec highlights can be accounted for, some StyleGAN-generated images can contain advanced lighting effects such as complex reflections, window transparency, and shadows, and the spherical harmonic lighting model is incapable of dealing with all cases successfully.
Given input images (1st column above), GANverse3D then predicts 3D shape, texture, and renders the object from the same basic point of view (2nd column). The image is now 3D as shown in the Multiple Views (3rd) column. The process is able to reconstruct hard surfaces with specular highlights and also more difficult articulated objects, such as birds and horses. But while some spec highlights can be accounted for, some StyleGAN-generated images can contain advanced lighting effects such as complex reflections, window transparency, and shadows, and the spherical harmonic lighting model is incapable of dealing with all cases successfully.
When imported as an extension in the NVIDIA Omniverse platform and run on NVIDIA RTX GPUs, GANverse3D can be used to recreate any 2D image into 3D. Users can both use it to create objects that the program is already trained on, such as cars, or use GANverse3D to train on users own new data sets.
The research papers supporting GANverse3D will be presented at two upcoming conferences: the International Conference on Learning Representations(ICLR) in May, and the Conference on Computer Vision and Pattern Recognition (CVPR), in June.
Creators in gaming, architecture, and design rely on virtual environments like the NVIDIA Omniverse simulation and collaboration platform to test out new ideas and visualize prototypes before creating their final products
Omniverse Enterprise
NVIDIA also announced the coming general availability of the high-end NVIDIA Omniverse Enterprise platform that enables globally distributed teams working across multiple software suites to collaborate in real-time in a shared virtual space.

NVIDIA Omniverse Enterprise makes it possible for virtual production teams — which are often large, diverse in skills, and geographically dispersed thanks to COVID— to work seamlessly together on complex projects. Rather than requiring in-person meetings or exchanging and iterating on massive files, designers, artists and reviewers can work simultaneously in a virtual world from anywhere, on any device.