The process of doing high-end facial capture is constantly not only improving but also becoming quicker and more efficient. One of the key papers at this year’s SIGGRAPH that illustrated this was Digital Domain’s Simplified facial capture with head-mounted cameras, by Jose Serra, Lucio Moser, David McLean, and Doug Roble.
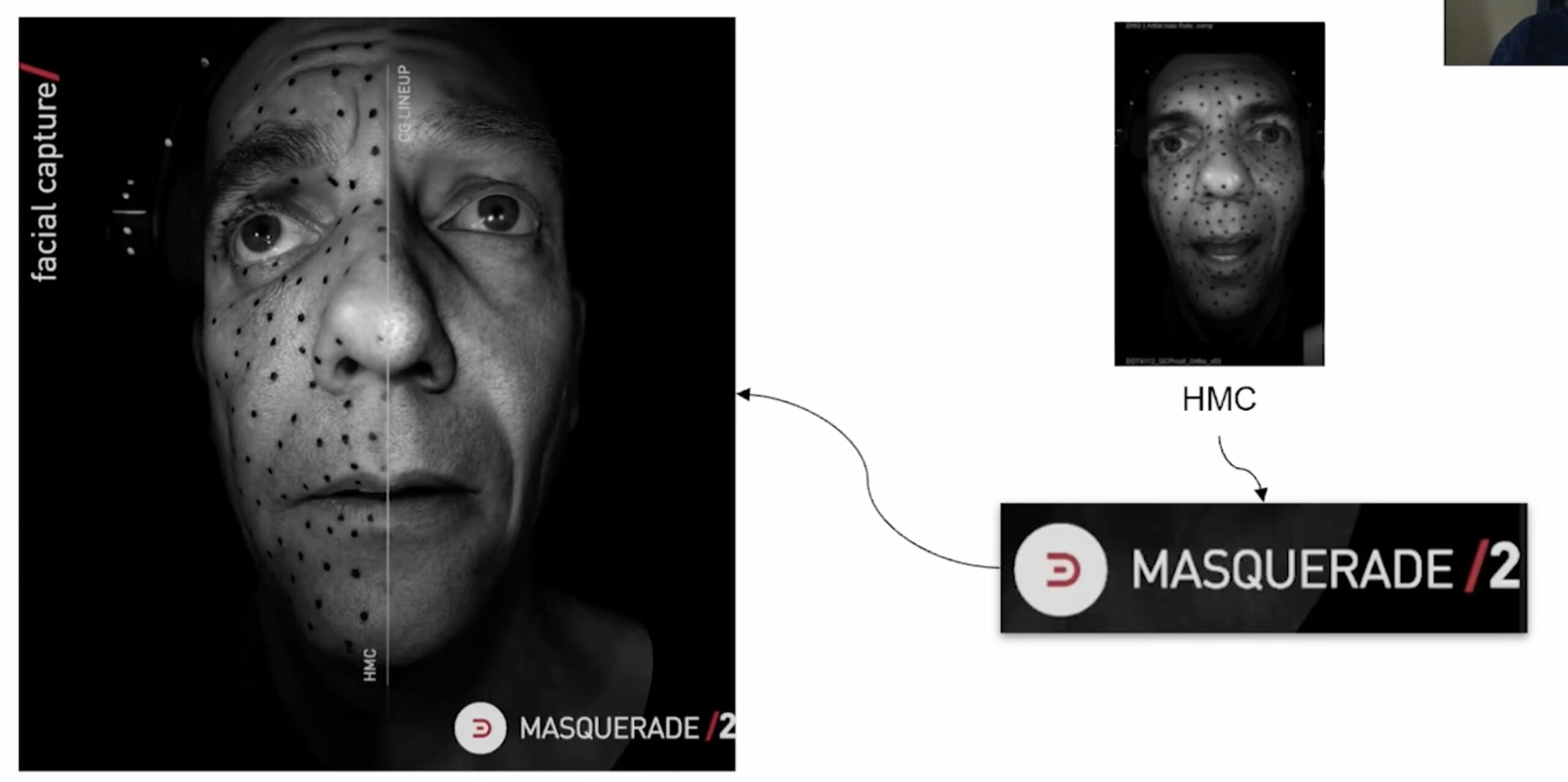
In the paper, the team outlines a new pipeline for high-resolution facial capture that replaces the initial traditional seated capture by using a head-mounted camera (HMC) setup. fxguide has outlined the Masquerade process at Digital Domain before. Masquerade is Digital Domain’s facial capture pipeline built on using HMCs. This new process builds on these rigs and it reduces the complexity of the capture process while still delivering the fidelity of performance Digital Domain is known for worldwide.
At its core, our approach relies on improving a set of roughly personalized blendshapes by fitting handle vertices, in a ‘Laplacian’ framework, to depth and image data. Thus, refining the geometry. Laplacian framework is a mathematical term, a sum of second-order derivatives. That means, in this case, it effectively restores the geometry of the actor’s face without introducing artifacts. Many artists are familiar with the Fourier transform that identifies frequencies, especially if you do any audio work. The Fourier frequency transforms are a ‘slice’ effectively of Laplace transforms. These 3-dimensional complex operations are perfect for dealing with facial meshes.
This pipeline has been used in production to generate high-quality animation to train Digital Domain’s proprietary marker-based solution, leading to large time and cost savings. The new pipeline innovation is to use the same HMC setup used when the actor is actually performing, to create the data needed for training the pipeline, thus avoiding various specialist ROM (range of motion) seated 4D captures. At first glance, this seems odd? How could the HMC provide high-quality data to train the pipeline to later accurately use the same HMC to better capture an actor’s performance? The answer lies in acknowledging that even the seated 4D capture is inaccurate to some degree and does not provide a perfect ‘ground truth’. By using the HMC to improve the later HMC capture the team reduces down the sources of any artifacts. “We actually reduced the number of inherent problems by capturing with exactly the same devices with exactly the same calibration steps and exactly the same geometry that is used to track the actors face when they are performing,” explains co-author Lucio Moser.

Digital Domain has been adding loads of machine learning principles to its pipeline for some time. Since last year’s fxguide story their Masquerade process, a new machine learning approach has been applied to the problem of automating determining the eye gaze of an actor. Digital Domain’s R&D team has been skillful in finding many areas of their pipeline that respond well to AI and machine learning. The process of replacing seated 4D capture with head-mounted cameras (HMC) is another example of this. Specifically, this SIGGRAPH paper is outlining how the team is changing part of the Digital Domain pipeline to facilitate a better way of producing their training data. This data then goes into their Masquerade face pipeline to help solve what’s coming off the HMC when the team is actually doing performances with the actor. This workflow is an extension and changes the way the production team can work. On previous projects, such as Thanos in The Avengers films, the team would “outsource to a service, the process of doing the seated capture, and the tracking itself of that training data,” comments Moser. “And that was a process that was required to be done for shows like, The Avengers. It also required adapting the geometry that we will get from those surfaces onto the geometry that we use to track in Masquerade.” That adaptation stage of the seated training data added the possibility of incurring problems. “So we knew it had to be dealt with, and so it became apparent that that whole part of the pipeline (data gathering) was necessary to be replaced.”
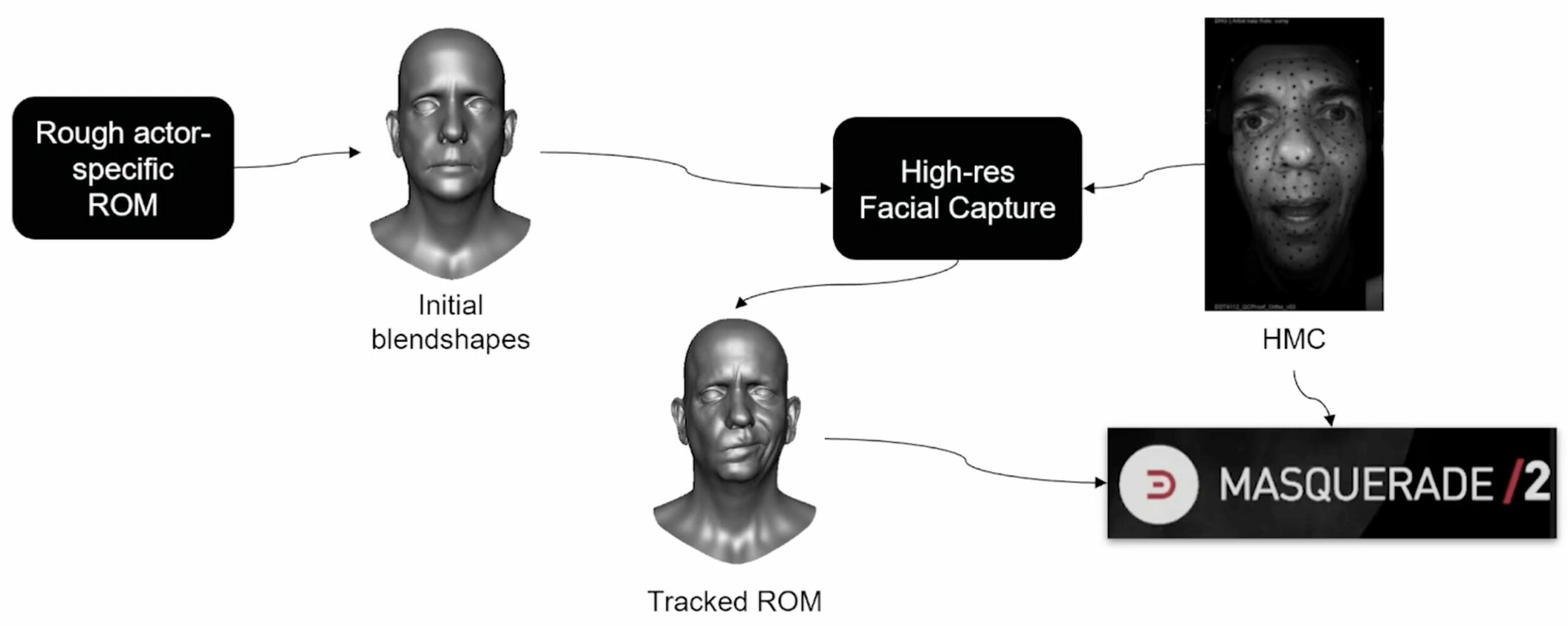
The new approach starts with a ROM recorded with the HMC, a depth map is computed for each frame, using 3D reconstruction and personalized blendshapes, obtained by interpolating multiple identities and blendshapes from Digital Domain’s extensive proprietary database. With this data, the team does an optimization of the blendshapes to match each frame’s depth map and video.
The optimized blendshapes are normally fairly good, but perhaps have lips that don’t quite match. The next stage is a Laplacian refinement which optimizes not the blendshape but tunes the surface via handle vertices. Laplacian matrix is calculated on a per-frame basis, and the process solves frames in batches, instead of one at a time. This produces a more temporally consistent result by reducing noise or jitter from the depth and optical flow. Then an artist can make corrections using WPSD (Weighted Pose Space Deformations).
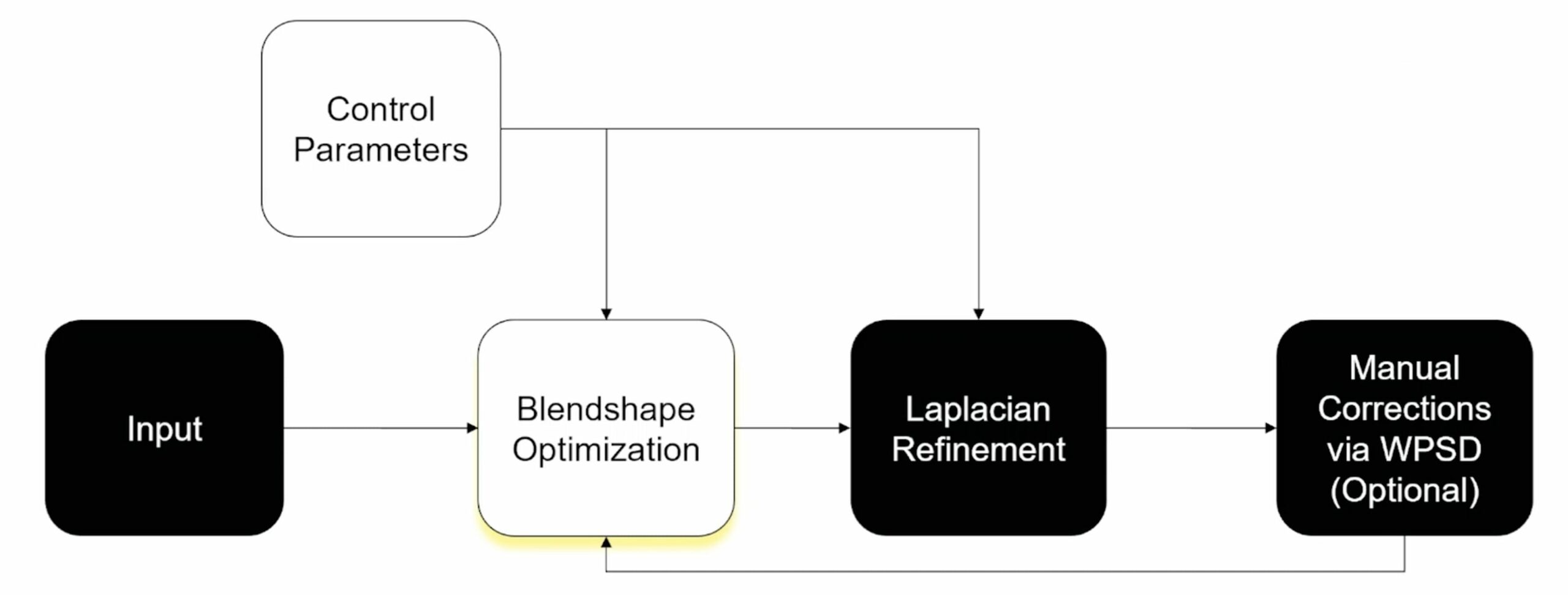
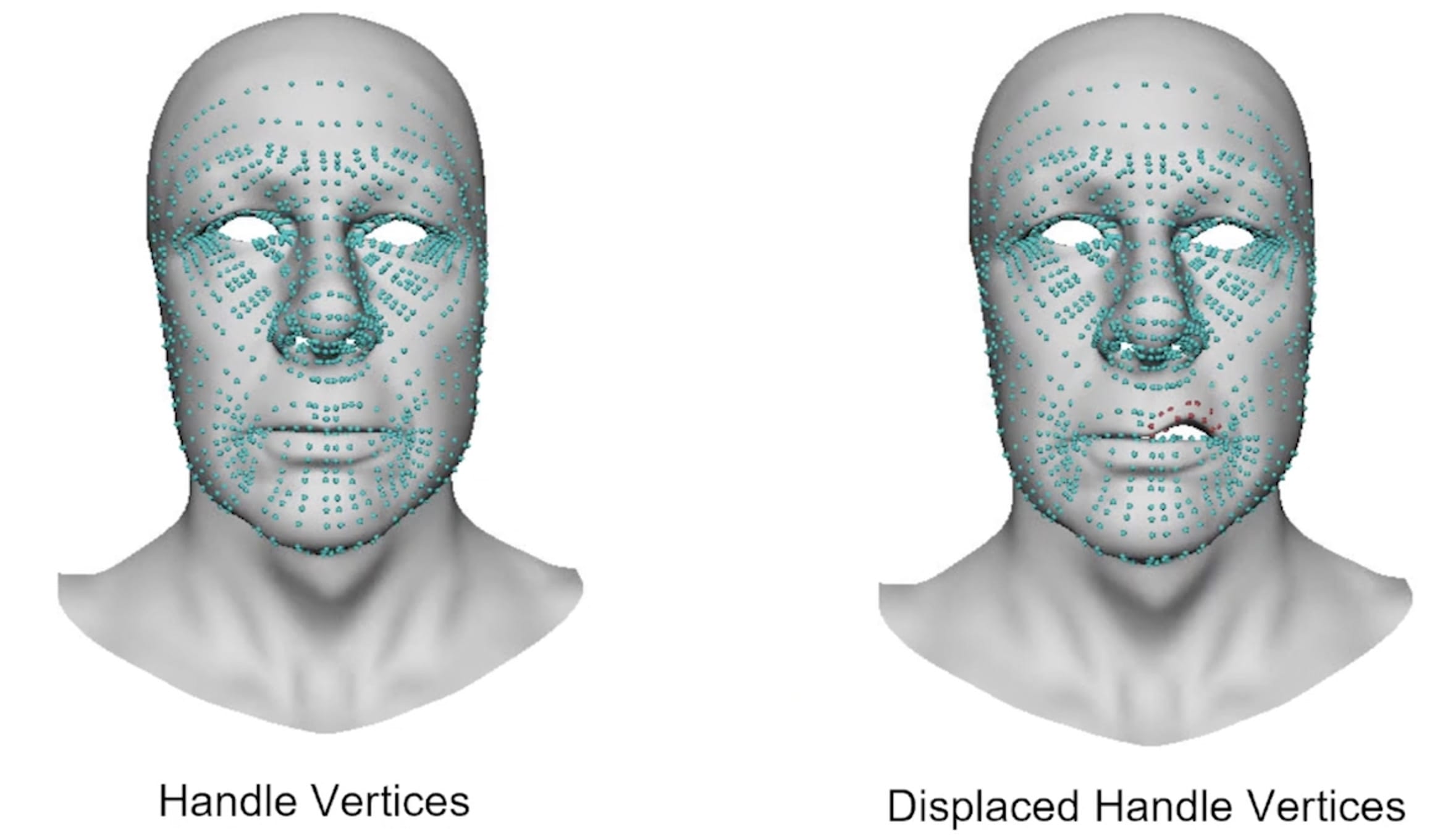
Far from being a fully automated process, “there’s also a step there where an artist is involved. They can check what is the quality of the data that we are getting from HMC,” adds co-author José Serra. “Instead of just being a purely automatic method that runs everything, and then there might be an error that is propagated throughout the rest of the pipeline.” Instead, the Digital Domain artists are able to contribute and supervise. “I think it’s really good that artists are in the middle of the conversation and the evaluation of the methods so that they can prevent the propagation of errors,” he adds. The artist input improves the process by tweaking the default input control maps and by applying example-based corrective. Once the artist is happy, the process extracts the principal components of the sequence (with PCA) and replaces the initial shapes with this new basis. Then the team can repeat the full process.
The system is built to be flexible and agile. As with agile s/w development, the system can quickly create a version of the training data that, while still not final, is enough to start with Masquerade in production and see results. Seeing something quickly for real shots in production is important. But it is also possible “to iterate our new method, improving the training data over time and then feedback that to production,” explains Moser.
The system that the team used to capture the SIGGRAPH data was done using an HMC with 2 Ximea MQ042MGCM cameras running at 48fps. Processing each frame took, on average, 45 seconds on a dual Intel Xeon Silver 4210/Nvidia Quadro RTX5000.
It might seem like if the new pipeline can produce such great training data, why not use it immediately but the process is not developed for a production Masquerade workflow. The new early-stage requires iterations and there is a significant computation cost. It is better to use the new innovation in generating training data. Then the final result can use the best of both worlds and produce larger volumes of high-quality output quickly.” To give some background, we had aimed originally to use this sort of technology to replace a marker-based workflow, but that proved to be quite a challenge to actually make work on all scenarios, without a lot of human intervention,” says Moser. David McLean, a co-author of the paper, realized the potential of just using the new approach for training data. It was McLean who created a prototype, tested it, lead the adaptation that the team ended up adopting.
The system can be made to support markerless capture but typically Digital Domain has used facial markers to help the process. What is important about the new process is the minimal configuration changes between actors. It is also not the case that Digital Domain would not still be open to using specialist 4D scanning capture, especially if the production required an exact replica of the actor.