VFX being used to build Machine Learning Training Data
Machine learning (ML) has become a popular approach for solving a wide range of problems in VFX. However, while ML is attracting a lot of attention for what it can do for VFX, there is also a new area of VFX focused on producing training data for ML solutions. Houdini, Nuke, and many other VFX tools are being creatively used to generate training data, and this trend is only expected to grow. To gain a deeper understanding, it is necessary to examine the underlying nature of ML programs.
ML as a learning solution
Before creating a machine learning solution, it is essential to understand the problem that needs to be solved, and what is required for an ML approach to work. Particularly, the nature of what data exists in the world already and the qualities of that data that can be used to solve the problem. At first glance, one might assume you just want the greatest amount of ‘ground truth’ or perfect examples possible, but that is not how one efficiently trains modern ML.
Supervised and unsupervised training data are two types of data used in machine learning. Supervised training data is labeled data that is used to train a machine learning model. This means that the input data is labeled with the correct output, and the model learns to predict these outputs based on the input data. Unsupervised training data, on the other hand, is unlabeled data that is used to train a machine learning model. In this case, that means that the model learns patterns and relationships in the data without any specific guidance as to what it should be looking for.
Both supervised and unsupervised training data have their own advantages and disadvantages, and the choice between the two depends on the specific problem being solved and the available data. But for someone not versed in ML, it is often assumed that more data is just better in both cases. It isn’t.
For both ML models, there is art and science to curating the data. For example, changing the textures on an object to something completely ‘wrong’ can have the effect of curating the training data to focus more on the geometry and bias it away from the surface properties when it builds its neural solution. Imagine you had a classifier that identified leaves on plants, but you know it is really the leaf shape or edge detail that is the best clue to the plant’s particular variety. You could produce a subset of the dataset which ‘devalues’ surface properties, by mixing in a set of leaves with odd surface properties, as if they were made with car paint. Leaves in nature are never grown with car paint so this is clearly false, but from the ML’s point of view, if it can’t rely on surface properties to identify plant varieties, it will lean into leaf shape more. So a VFX artist could be employed to make plants with car paint, to direct or curate an ML solution. This is an example of synthetic data. This particular approach is known as domain randomization using ‘distractors’.

Synthetic data
Creating synthetic data using visual effects tools has become an increasingly popular method for generating large and diverse datasets for ML. This type of data is often used when there is a lack of real-world training data, or when obtaining real-world data is difficult or expensive to obtain. VFX software can be used to create realistic virtual environments, objects, and characters that can be manipulated and filmed in useful scenarios. VFX allows for the creation of data that would be difficult or impossible to obtain in real life, such as rare events or dangerous situations. Additionally, the ability to control lighting, weather, and camera angles provides greater control over the data generation process and variation in likely inputs. It can also be used to create very obviously ‘wrong’ data as a way of steering ML solutions as discussed above. As a result, synthetic data is becoming an essential tool for ML and computer vision applications.
During COVID a lot of companies discovered the benefits of VFX-based synthetic data, for example, there was an agricultural company in the USA that just couldn’t get people out into their crop fields to take photos for their ground truth data, so they trained on synthetic data instead. In VFX, if you want to train an ML to improve roto, you could have human artists annotating and rotoscoping out various individual frames for segmentation maps, but they will have noise in them compared to synthetically making segmentation maps using animated digital humans. Here the ‘roto’ segmentations are faked based on actually having 3D silhouettes, but it will be very accurate. You can create 100% precise and high-quality data that just doesn’t have any of the flaws that you would see with traditional methods.
Synthetic training data is artificially generated data that is used to train ML models at all the major AI companies currently. Nvidia, Google, and many others are using generative adversarial networks (GANs), neural networks, and VFX simulation tools to produce synthetic training data.
Synthetic data can be generated using various techniques, such as
- data augmentation,
- GAN inferences,
- 3D animation,
- simulation,
- distractors,
- ablation,
- synthetic minority oversampling techniques,
- rectifying confounders and
- other many other methods.
The goal of synthetic training data is to create a large and diverse dataset that can be used to train a machine learning model and improve its accuracy. This is because synthetic training data is often just more efficiently generated and provides more corresponding additional metadata that can be helpful. For example, digital human faces can be used to train certain applications, not because they look more accurate or realistic but because they can provide highly accurate surface normals, – much more easily than trying to derive them from actually photographed still images.
More is not better
Creating and especially curating an ML solution requires a deep understanding of the problem being solved, the data being used, and the ML algorithm being applied. This can be a highly skilled and demanding (human) role. By following a structured approach and continuously iterating and improving, ML solutions can be a powerful tool for solving complex problems and driving innovation, but only if the underlying data and assumptions are fully investigated. Just because an ML has vast amounts of data, it isn’t necessarily more accurate. Academy Award winner Ryan Laney explained this to fxguide back in 2021 about filming training data for his documentary feature Welcome to Chechnya.
Bias
When making the feature film, Laney found that a key step was focusing on selecting the right training clips. From the large library of possible training material for any witness face replacement, only a carefully curated sub-set was used. The process deployed several machine learning tools to keep track of the training data and automatically produce a set of frames/clips based on matching head angle, color temperature, and lighting. Specific training data was pulled from the master database using a NumPy – Euclidean distance, ‘big table’ lookup approach based on the data set’s ‘face’ encoding. The face encoding was based on face angle and expression.
 Each actor was filmed with multiple cameras placed around them to capture multiple angles of the same performance. During the setup of the cameras, the actual shutter control could not be controlled synchronously. As a result Ryan just let the cameras run and he did not cut between takes. This resulted in training footage of both the deliberate takes and all the random in-between recordings of the actors talking to the director, who was off to one side. The result was that the training data as a whole had a bias to one side of the actor’s face, (the side shown to the cameras when the actor turned to talk to the director). Ryan pointed out this is exactly the sort of unbalanced or training data bias that one needs to avoid.
Each actor was filmed with multiple cameras placed around them to capture multiple angles of the same performance. During the setup of the cameras, the actual shutter control could not be controlled synchronously. As a result Ryan just let the cameras run and he did not cut between takes. This resulted in training footage of both the deliberate takes and all the random in-between recordings of the actors talking to the director, who was off to one side. The result was that the training data as a whole had a bias to one side of the actor’s face, (the side shown to the cameras when the actor turned to talk to the director). Ryan pointed out this is exactly the sort of unbalanced or training data bias that one needs to avoid.
While Ryan’s example is having an unwanted bias in the training data, it is also just as valid to introduce control biases if you are skilled in the art of ML training. It is important to approach ML solutions with a critical eye, and not simply believe that a solution is correct or superior just because it is high-tech and uses AI. It is essential to investigate the underlying data and assumptions and consider the limitations of the training data being used.
To understand more we spoke to ML experts at NVIDIA and Google.

NVIDIA
Paul Callender is a technical artist on NVIDIA’s Replicator Team. NVIDIA is arguably the world’s most dynamic company right now in the area of Machine Learning, – a fact reflected in their rapid revenue and share price leaps as a listed company.

NVIDIA has a whole set of developer tools for producing SimReady assets. SimReady, or simulation-ready, assets are physically accurate 3D objects that have accurate physical properties, behavior, and metadata to represent the real world in simulated digital worlds (and/or digital twins). SimReady assets are built using Universal Scene Description (USD), and built to behave as they would in the real world for maximum accuracy with PhysX, NVIDIA’s open-source, scalable, multi-platform physics simulation solution.
NVIDIA’s SIM Ready assets go beyond normal VFX requirements. SIM Ready assets are interesting, believes Paul Callender, because with assets “you want to be able to randomize a lot of properties or attributes of those assets and so we can’t easily take simple game assets or VFX assets because they’re not necessarily built in a way that’s we’re able to modularly swap things out.” Some aspects of VFX assets are able to be easily varied such as material properties but in general “if you wanna do things like have your meshes separating or segmented into different pieces, etc, – it’s ideal to have everything completely parameterized.” With Sim Ready assets one is able to randomize as many properties procedurally as possible.
As part of the company’s Omniverse tool kits and SDK, there is a specific synthetic data generation called Omniverse Replicator. This is an extension of Omniverse that deals specifically with synthetic data generation. NVIDIA’s Omniverse Replicator is a core part that enables researchers and developers to generate physically-accurate synthetic data, and easily build custom synthetic data generation (SDG) tools to accelerate the training of ML networks. Paul Callender comments, “it is all Pythonic and it integrates with all of the other aspects of Omniverse for creating the SDG simulations, and it can be used to generate synthetic data.”

There are many common ML VFX ‘tricks’ such as creating partially hidden versions of visual objects since more items in the wild are not clearly and cleanly seen. Another interesting ML concept is called ablation, explains Paul Callender. “Datasets are generated with some set of variations, such as texture randomization, lighting randomization, adding noise or other aspects. Ablation creates sets, removing one randomization type in turn, in order to test how much effectiveness in performance that randomization has. This is one such tool that helps SDG teams understand what and how variations affect the datasets.”
In terms of VFX being used in synthetic data, Callender breaks down the stages for SDG (synthetic data generation) into:
- assets,
- scene building,
- simulation and
- data generation.
“Asset generation is the biggest area for traditional VFX since there’s an insatiable need for a variety of assets and environments to “close the domain gap” and get closer to ground truth,” he explains. “Houdini and Blender are of particular note because they’re procedural.” Proceduralism and SimReady assets are part of the solution to creating and parameterizing variations for SDG. “We need to lean on programmatic approaches to grabbing assets and populating scenes. In order to do that, all assets need to “know” what they are with classifications, so they can be queried for and then be placed or randomized in some way.” Ideally, one wants to do this during the running of the generation of the scenes and capture, and not rely on hard “baked down” assets that can’t be altered. “This is one reason that real-time solutions are so desirable”, he adds. “Their rate of modification and the rendering and generation of the SDG is potentially so much faster.”
Traditional VFX concepts like compositing, also have an analog in SDG. “Matching sensor noise, and pixel gamut, even matching blowing out of light can be important if your ground truth includes those artifacts.” Such artifacts can be applied during compositing or grading, often in real-time, or as a post-process. “Post augmentations are usually done with libraries like OpenCV or other python friendly image libraries to achieve the needed effects”. Usually, NVIDIA tries to match the major variations, such as lighting variations within the scenes themselves “because simulating everything gets us closer to reality, matching the photometric properties of lights in a scene so that tweaking the numbers programmatically gives consistent results that make sense”.
SDG is very important as it solves things one can’t do otherwise. “I saw an example where vehicles in images were very small, and the people annotating weren’t able to discern what class of vehicles they were, since they were a handful of pixels in the images at distance,” Callender recalls. “SDG knows those classifications, regardless of the size of their rendering in the images.” In this case, the AI models were able to squeeze out more performance of recognition of distant vehicles when SDG was included.
Paul Callender points out that far from ML being dull data wrangling or mundane work, SDG is akin to ‘sleuthing and alchemy’. “AI doesn’t perceive or detect features like people do. So simply following our own preconceptions of what something looks like isn’t always the way.” Because of this, he believes generating good SDG is an iterative process between the artists who generate the scenes and the ML engineers who test and train the models on the data.
“Our team is sleuthing the essential aspects of a scene, and reconstructing systems synthetically to procedurally build large quantities of data. I always felt VFX (and game development) has a long history of exactly this, creating visuals from reference, and devising systems, often procedural, often as simulations, to achieve a result.” – Paul Callender.
In the end, artists like Paul Callender, are deeply using tools common from the VFX and gaming industries to create successful SDGs. “It’s an exciting space and the skills map over very well,” he concludes.

Google’s Synthetic Team uses many of the common VFX tools used in production. DCC tools such as Houdini, Blender, Maya, Nuke, etc. “Pipelines and workflows are inspired by our VFX past but integrated in an environment that is not identical to a VFX house,” comments Google’s Luca Prasso, Senior Technical Artist ex Dreamworks. “We add to the mix lots of custom and proprietary tools and code, where Tech Artists work alongside our engineering staff.”

Google’s synthetic team uses many of the common VFX tools used in production. DCCs like Houdini, Blender, Maya, Nuke, etc. Pipelines and workflows are also inspired by past VFX work but integrated into a new environment that is not identical to that of a VFX house. “We add to the mix lots of custom and proprietary tools and code, where Tech Artists work alongside our engineering staff,” Luca Prasso points out. “The role and use of synthetic data in Machine Learning is evolving daily and the way data is generated and consumed varies depending on the project.”
Google’s team focuses on generic synthetic 3D scenes that are used to train algorithms to “see and understand” the world. Often this world is complex, tridimensional, animated, and made of many layers of information that a GAN or similar algorithms cannot reproduce yet. “At the same time, new techniques find a place in our “traditional” pipelines. For example, motion can be synthesized instead of being simply produced via mocap. Relighting and rerendering a scene or a photo can be done in new exciting ways with NeRF algorithms for example.” (For an explanation of NeRFs see our fxguide story)
The challenge within a challenge for the team is to be able to keep up with these rapid changes while developing a synthetic pipeline at scale. Synthetic data is useful in ML because it produces data that cannot be easily captured in the real world at the scale required. The synthetic data is precise, annotated, and detailed, without suffering from the “noise” introduced by a human annotator.
“Often synthetic data can unblock the design of a new algorithm even before we start collecting data from the real world,” he explains.
One of the challenges in designing synthetic data systems is how we deal with bias. “When we need to teach an algorithm to recognize a pen for example, we design procedural systems that are capable of generating every possible pen ever produced, controlling shape, materials, look and feel. In designing these systems we need to be sure we don’t introduce bias, designing for example: only ball pens. As we start capturing real data we need to constantly reevaluate design choices to remove such bias and produce something as close as possible to real data.” Procedural VFX tools like Houdini are well suited for many of the tasks the team has to tackle. “Often our team is asked to create data before new hardware sensors are available. These approaches unlock research and development, simulating what is possible using traditional DCC tools.”
“A joke that I used to make movies at PDI/DreamWorks for an audience of kids and parents and now we make movies that only algorithms will watch…I make movies for an algorithm, fortunately, the algorithms are not picky when we produce sequels!” – Luca Prasso
Design at scale is also another challenge. Some ML algorithms are extremely data-hungry. “We don’t need just a few thousand images/scenes/variations, we sometimes need millions and millions. In those cases, we can take a VFX-like pipeline designed to create a feature film clip of 7 minutes and then we duplicate it for every dataset we need to produce.”
Google also has its own proprietary pipelines and technologies that they have been implementing and working on for some time, but their ML Engineers tend to publish their research work at conferences like SIGGRAPH or CVPR. “Ground truth real data is critical in designing most of these systems. It grounds our work and prevents artists from introducing unnecessary bias in the workflow. If we do our job well our data is as close as possible to the ground truth (within the limit of quality and scale required).”
Google also curates training data is a key part of their machine learning process. “Curation has a lot to do with measurement and accurate labeling of synthetic and real data. This allows the ML Researchers to identify the data they can safely use in their training, to compare and contrast, and to find the right “ratio” between real and synthetic in order to achieve better algorithm performance.”
Simplest forms of Synthetic Data.
Synthetic data can be used in one of two ways it can be used to create new original imagery and data that stands in for ground truth data captured in the real world or it can be used to augment, supplement, or build upon original ground truth training data. The second case is quite standard in fact there exists automated processes for taking imagery that might be used as training data and flipping it rotating it and adjusting it in ways that seem trivial to the human eye but in fact provide a vast multiplying effect to training data. It’s not uncommon in various machine learning tools such as PyTorch to have this as an automated feature that would multiply the training data by a factor of 9. Often times this is done by just performing affine transforms. Affine transforms are geometric transformation that preserves lines and parallelism, but not necessarily Euclidean distances and angles, like flipping (mirroring) the image.
Dimensions and Depth
In machine learning, dimensions refer to the number of features or variables used to represent a data point. For example, a data point may have three dimensions, representing its height, width, and depth. The number of dimensions in a dataset can have a significant impact on the accuracy of the ML model, as more dimensions can lead to increased complexity and longer training times. Depth in machine learning refers to the number of layers in a neural network. A neural network consists of multiple layers, each containing neurons that process information. The number of layers in the network determines its depth, and this can have a significant impact on the accuracy of the model. Deeper networks can model more complex relationships in the data, and can therefore produce more accurate results. One of the key aspects of curating training data is providing the right amount and type of data based on the dimension and depth of your ML pipeline.
Rectifying Confounders
A key insight in ML is confounding factors can adversely affect the predictive performance of neural network models. ML is powerful for solving complex problems, but it is not without its drawbacks. One of the biggest challenges with ML is the presence of confounding factors. Confounding factors are variables in the data that can have a significant impact on the accuracy of the ML model but are not directly related to the model’s output. For example, in an ML model that is trained to identify cats in images, the color of the cat’s fur may be a confounding factor, since it is not directly related to the task of identifying cats, but can still have an influence on the model’s accuracy. To address this, it is important to identify and account for any confounding factors in the data before training the model. This can be done by using techniques such as feature selection, data pre-processing, or data curation.
One of these challenges is about removing the ‘false signals’ extracted by deep learning methods due to the existence of such confounding factors. Acknowledging these recognition mistakes, the empirical evidence is that deep neural networks can learn signals from confounding factors such that a seemingly well-trained deep learning model will exhibit limited predictive performance on external data sets, – despite having a highly predictive power on lab-collected/lab-controlled data sets.
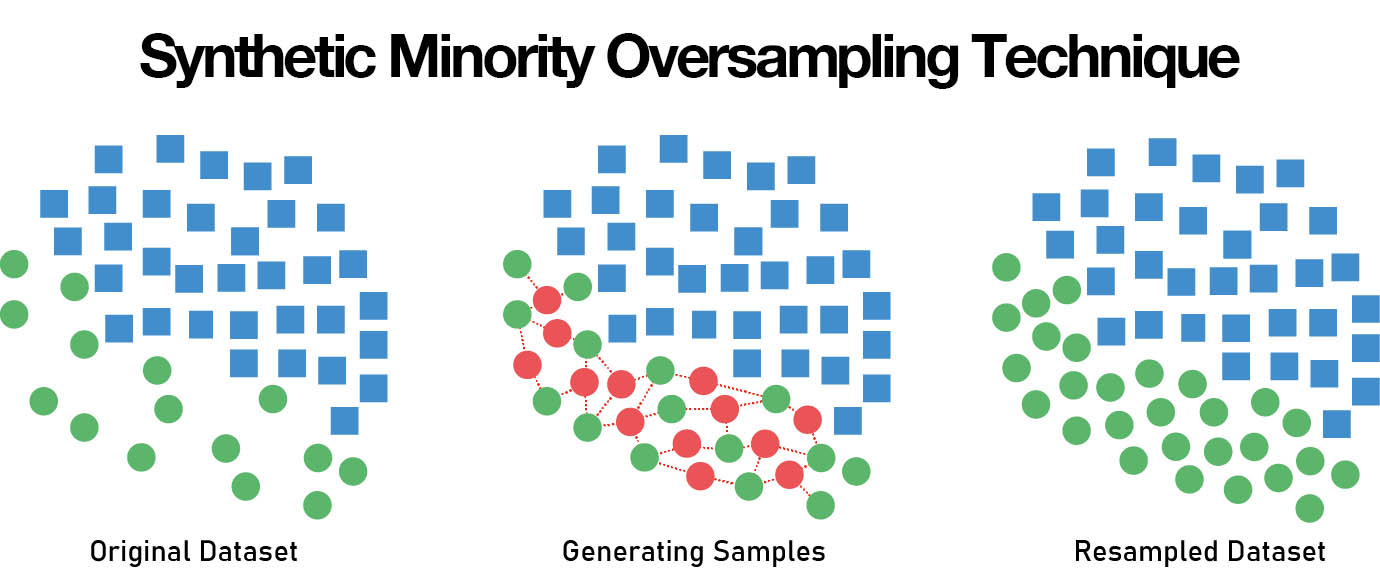
Minority Features and SMOTE
In ML, minority features are features in the data that occur in small numbers relative to other features. These minority features can have a significant impact on the accuracy of the ML model but are often overlooked due to their small numbers. It is important to identify and account for minority features in the data before training the model, as they can introduce bias and lead to inaccurate results. Techniques such as oversampling and undersampling can be used to balance the dataset and ensure that minority features are not ignored. Additionally, data pre-processing techniques such as feature selection can also help to identify and account for minority features in the data.
SMOTE (Synthetic Minority Oversampling Technique) is a ML technique used to address the problem of minority features in datasets. It works by creating synthetic data points that are similar to the minority features in the dataset. This allows the model to better learn from the minority features, resulting in a more accurate model. SMOTE is particularly useful when there are few minority features in the dataset, as it helps to balance the dataset and ensure that these features are not ignored.
As data scientist Joe Cincotta explained to fxguide, “SMOTE uses clustering to approximate values in the vicinity of the under-represented samples, and this works for a simple numeric value.” For complex image datasets, a generative model is closer to what is likely to be wanted. He explains further, – “in fact, this is very much what GANs can be good for – if you identify minority features in an imaging dataset, you can try to perform minority oversampling by using the output of a GAN or diffusion model that has only been trained on the minority images.”
Dropouts
Dropouts are a technique used in ML to prevent overfitting. Overfitting occurs when a model is too closely fit to the training data, and is unable to generalize to unseen data. Dropouts work by randomly “dropping out” neurons from the neural network during training. This forces the network to learn a more general set of features that can be applied to unseen data. Dropouts can help to improve the accuracy of the model and reduce the chances of overfitting.
Overfitting can be good.
At SIGGRAPH in LA, the Wētā FX team spoke of overfitting when populating the sea bed near the reef village of the aquatic Metkayina clan, on Pandora.

Overfitting can be used deliberately to generate synthetic data for specific use cases. By allowing the model to overfit on a small dataset, you can capture intricate details of the data distribution. Then one can introduce controlled variations and perturbations to create new synthetic examples that still adhere to the characteristics of the original data. This technique is particularly useful when you have limited real-world data, but want your model to generalize better. The overfitting at Wētā FX for example is carefully controlled and purposeful. Their goal is not to create a model that performs poorly on unseen data, but rather to leverage the model’s ability to capture intricate details from the training data and then use this knowledge in a controlled manner to produce a large amount of similar but original underwater plants and seaweed.
Making Movies To Teach ML Algorithms About The World.
NVIDIA’s new Magenta Green Screen approach was also highlighted at SIGGRAPH this year. The research was covered in some of the popular press as just a new approach to keying a green screen. But this missed the main point: that this is a new way to produce very high-quality mattes for use as training data. By recording the color image of a foreground actor with a simultaneous high-quality alpha channel (without requiring a special camera or manual keying techniques), it provides an automated way to produce extremely accurate mattes quickly.
The team set up the new approach to record an actor on a green background and light them with only red and blue foreground lighting. This works very well due to the separation and the way modern CMOS cameras are designed. In this configuration, the green channel shows the actor silhouetted against a bright, even background, which can be used directly as a holdout matte, the inverse of the actor’s alpha channel. They then use a completely different AI to restore the green channel of the foreground using ML, but only for the recolorization of the foreground. To do this, they trained the colorization model with an example sequence of the actor lit by white lighting, which gives a convincing foreground result. The real issue is not that ML is used for recoloring, but the quality of the mattes.

The team actually went further and time-multiplexing the lighting between the special magenta green screen which makes the actual studio environment appear to be mostly lit with normal lighting. However, the real importance of this technique is that it yields high-quality compositing results. The high-quality alpha channel data output with their technique provides a significantly better set of training data for the new generation of natural image matting algorithms which will be made with future ML matting research.
And it is only going to expand.
One thing everyone we spoke to agreed, especially with the rapid developments in generative models, synthetic data generation is only likely to grow as we move forward, and this is the start, not the end, of the opportunities in this space.