At SIGGRAPH this year (2023), by far the hottest topic was NeRFs, or rather Neural Fields. From the technical papers to the SIGGRAPH courses and the Emerging Tech demos, NeRFs were everywhere.. Most people became aware of NeRFs last year especially due to the popularity of Luma.ai, which allowed anyone to make a NeRF on their iPhone. In short, NeRFs seemed like a way to do ‘better photogrammetry’, but they are much more than that and hold out the promise of being more significant than ChatGPT for the VFX industry. There are many ‘wizz-bang’ fast editing YouTube videos showing ‘cool’ NeRF outputs, but after having covered NeRFs for over a year now, we thought, here at fxguide, we would provide a deep dive into what they are and some of the areas that NeRFs are likely to change in VFX.
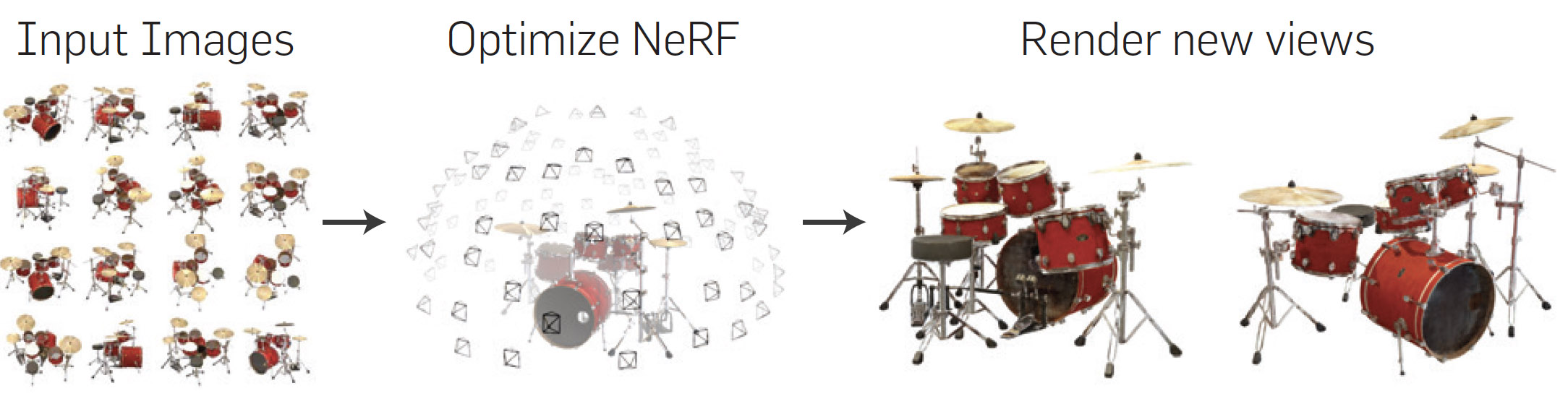
As always SIGGRAPH is the perfect place to learn, and for those who could not attend, here is our summary of the NeRF highlights and insights from SIGGRAPH 2023 in LA. This does not cover all the SIGGRAPH content by any means, but it is a primer on the State of the Art, without the need for any complex maths.
Above is a NeRF captured at SIGGRAPH 2023 (using the Luma.AI App) of Paul Debevec’s Presidential ‘Light stage style’ capture rig. This rig was on display only as part of the 50th SIGGRAPH celebrations, (it is not a NeRF rig).
Neural Fields for Visual Computing (course)
This was ground zero if you wanted to understand NeRFs at SIGGRAPH. The course was one of the best we have attended in years and it provided an overview of the techniques, an understanding of the mathematical properties for practical uses, and examples of how to use this understanding to solve graphics problems. It was led by James Tompkin from Brown University – and he was joined by a great set of speakers including Alex Yu from Luma AI, but it was James Tompkin’s brilliant introduction and the following talk by Towaki Takikawa from the University of Toronto / NVIDIA that we refer to below for an introduction to what a NeRF is. The room was packed when the panel presented and the quality of the presentations was brilliant. We respectfully quote and borrow from their presentation, but link here for their full website. This SIGGRAPH course originated from a Eurographics 2022 State-of-the-art Report called Neural Fields in Visual Computing and Beyond, and an earlier version was presented at CVPR last year.
What is a NeRF?
The term NeRF actually refers to Neural Radiance Fields, which is only one of several terms and labels used to describe what we collectively call Neural Fields. Other terms include implicit representation, neural implicit volumetric representation, and pre-computed radiance functions. For this article, we will use NeRFs, but strictly speaking, this is similar to calling all vacuum cleaners “hoovers” or all neural renders “deepfakes.”
A NeRF (or Neural Fields), can be thought of as a 3D representation inside a neural network. It is a way of having a three-dimensional representation of something or somewhere in an AI system. That representation is not a point cloud or photogrammetry model. It can be turned into a polygonal model but as a NeRF, it is not a classic 3D model, i.e., it is not a polygon thing with textures, etc.
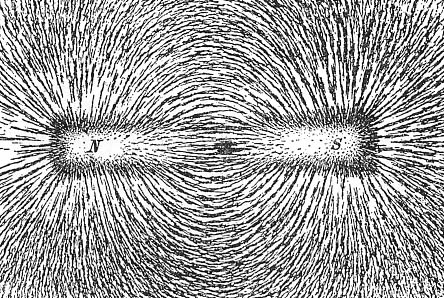
To go a little bit further, we are used to fields generally, magnetic fields for example. If you ever saw iron metal filings sitting on a piece of paper above a magnet in school – you know that from the magnetic field’s lines of force, you could tell the shape of the magnet.
Now imagine that you have a three-dimensional field around the classic CGI teapot. you could define a signed distance field that would be zero on the teapot’s surface, but a positive value if you were outside it and a negative number if you were inside it.

This ‘field’ would define the teapot not by polygons and coordinates but by the field. If you think about any surface in the real world, it has a radiance value. Radiance refers to the amount of light that is emitted or reflected by any surface in a particular direction. In NeRFs, radiance is used to model how light interacts with the 3D scene being ‘modeled’ by the neural network. In the same way, all points in a scene have a density. The density field is trained alongside the radiance field for NeRFs, and it helps to model the likelihood of a point being occupied by an object or being an empty space. The combination of the density field and the radiance field allows NeRF to accurately model the appearance of objects in 3D space.
A NeRF is just a machine learning technique used to generate (or volume render) a 3D representation of something from a set of 2D images. It works by training a neural network to predict the 3D position and appearance of each point in space. The network is trained on a set of images taken from different viewpoints. Once the network is trained, it can generate new views of the object or scene from any viewpoint, without the need for expensive traditional rendering techniques.
Why do I care?
First, it is not photogrammetry.
Photogrammetry works by taking a large number of 2D images of an object or scene from different viewpoints, and then using software to reconstruct a 3D model from these images. It does this by triangulating a point, so it needs the point to be very similar from different viewpoints. If it sees a white dot on the floor – it aims to find the same white dot in multiple other images.
If that white dot is a specular highlight or reflection then it won’t be there when the floor is viewed from different camera angles. Highlights and reflections are view-dependent. As such photogrammetry will produce a fixed ‘view-independent’ render of the floor. If you fly around the 3D scene the textures don’t change. A NeRF produces a view-dependent output, as you fly around a NeRF room, the lighting on the floor changes – and not because you relit it, the NeRF just shows you what it did look like from that new angle – highlights and all. As a viewer, this is a much more rich and realistic representation than a frozen ‘baked’ 3D scene.
Secondly, NeRFs are small – insanely, stupidly, small.
NeRFs are compact, they are computationally expensive, hence the use of GPUs with NeRFs. They are not easy to animate or edit but they also don’t care what they represent, and they are tiny. Towaki Takikawa had an excellent example as an analogy at SIGGRAPH: The original Gameboy from Nintendo.
The original handheld device below had 8 kilobytes of on-device memory and 128 kilobytes of cartridge memory. By way of reference our compressed Jpeg on the fxguide server for this image below is 177Kbytes, (so this one image of a Game Boy would not even fit on a Game Boy. Yet thanks to loads of sprite ingenuity, millions of people played Super Mario Land happily on a Game Boy. Things looked 3D or a series of animated frames but they were 2D sprites.

Similarly, NeRFs achieve incredible compression by not storing 3D models and textures but implicit surfaces – which is to say, mathematical models that define things found in the real world, or 3D signed distance fields that could later be converted to geometry if desired. It is complex maths but the ‘formula for a scene’ can be vastly smaller than a point cloud sampling or polygon version of the scene.

NeRFs exhibit what has been called an “unreasonable effectiveness of optimization”. But the various forms of Neural volumetric approaches go much further and address computational speed not just compression with additional innovations such as Wavelet NeRFs 9CVPR 2023) and Triplanes – which uses a set of axis-aligned feature representations (see NVIDIA’s Live 3D portraits in Part 2 of this series).
Thirdly, it is what you can do with them(!)
Neural fields let us solve difficult problems in recovering complex realistic models of the real world with great geometric accuracy, appearance, and motion.
There are so many things NeRFs allow. The first papers on approximating reflectance functions with Neural Networks date from early 1998, (Gargan and Neelamkavil, 1998) but the actual NeRF paper that coined the term ‘NeRF’ was in the first half of 2020, NVIDIA’s Ultra fast NeRFs was just in March 2022, yet at the CVPR 2023 two months ago, there were 170 papers on NeRFs or Neural Fields. That is more than all of this year’s SIGGRAPH 2023 Technical Papers program combined!
 Accurate 3D mesh reconstruction.
Accurate 3D mesh reconstruction.

NeRFs are very successful in showing a new novel view of something but NeRF pipelines often fall short of accurately outputting the underlying geometry, if exported to a polygonal mesh. There have been some great advances such as Neuralangelo from NVIDIA which we wrote about in June and there’s also recently been a new approach ‘NeRFMeshing’, which seeks to extract precise 3D meshes from NeRF-driven networks.
Luma AI
Luma AI has released V 0.3 of their Unreal Engine 5 plugin for NeRFs.
This provides real-time neural volume rendering in UE5. It has
- Distilled NeRF models running in the fragment shader
- 100s of FPS on NVIDIA GPUs, (much faster than OSS rendering) and often acceptable on Apple (Non-NVIDIA) M1/M2 hardware.
- WebGL rendering is available but not deployed.
- Performance can be scene-dependent and it will likely run poorly on low-end devices
Luma AI has released ‘Flythoughts‘ which is an app to show off interior spaces with AI-generated cinematic videos. No need anymore for drones, LIDAR, or gyro-stabilized cameras.
Luma AI now has a range of state-of-the-art tools for VFX artists and TDs.
Live Holograms: NVIDIA
Perhaps the most impressive live demo at all of SIGGRAPH was NVIDIA’s live NeRFs used to show video conferencing. It got our vote as the most impressive implementation of real-time live NeRF + (no special glasses) holograms. It was remarkable. We will have an in-depth interview with the team from NVIDIA and Looking Glass here on fxguide soon in Part 2 of this series.

Technically… This is the General NeRF Framework.
The general framework for using neural fields to solve VFX problems is :
- First sample the coordinates which are the inputs of the neural network.
- The neural network predicts the reconstructed signal.
- The reconstruction is then rendered or inferred into what we can measure in the real-world

- With the inverse problem, we are given sparse, noisy, and constrained information from real-world sensors. And we want to recover a rich vivid representation from these limited real-world observations. For example, how can we reconstruct a 3D geometry from a limited set of images? We need a differentiable function, mapping the reconstructed signal to sensor input. This is the differentiable forward map. In visual computing, this becomes a differentiable renderer. With that, we can now achieve the reconstructed scene, with just limited input.
More problems that are being addressed…
Relighting of NeRFs has been very hard, since in theory NeRFs, can be thought of as individual particles that emit rather than reflect light, making a NeRF extremely difficult to easily relight, unless you convert it and export it as a set of polygons. A new dataset called Relight my NeRF (ReNé) has been introduced to try and help solve this. ReNe aims to begin solving this problem with the introduction of their research, building upon a multi-resolution hash grid, also known as Instant-NGP.
Stitching NeRFs and mixing them up with Stable Diffusion. Just prior to SIGGRAPH 2 papers with similar names using the term ‘NeRF2NeRF’ came out. The papers are unrelated but both really useful. The first of these can stitch together NeRFs. The second opens the door to generative AI combined with NeRFs and both are in Part 2 of our The Art of NeRFs series – along with the NVIDIA real-time NeRFs for holographic video conferencing.