Faceware Technologies is a facial motion capture company that develops hardware and software for real-time and offline facial MoCap. Faceware has been producing facial motion capture pipelines for many years. Initially, the team assumed that their work would be used for pre-viz, but the games community were the first community to really respond to the company’s tools. Today the company offers a range of solutions that marry software and hardware, at a range of price points. As a partner on the new Epic MetaHuman project, users will soon be able to use Epic’s sample assets with Faceware’s software.
Interestingly, the company both rents and sells its high-end gear. The company also supports lower end indie productions. Over the years fxguide has used and tested many iterations of Faceware solutions and the most recent is the Mark IV head gear released last year.
We test drove the Mark IV in our tech lab and it is a really well-engineered system that provides remarkably high quality and reliable data. The software comes in two pipeline forms, both a Maya/Motionbuilder Keyframe offline workflow and a newer real-time workflow built around Faceware Studio.
Hardware
Chris Jones, Director of Hardware and Capture at Faceware Technologies, was the principal lead designer and engineer of Faceware’s last two versions of its hardware. Jones’s background was post-production in AV trucks, he has a very on-air robust approach to facial motion capture. This is reflected in the Faceware solution, it works and it works without a lot of alignment, adjustment, or fiddling. It is tough, stable, and really impressive.
Unlike some solutions through the addition of Machine Learning (ML), Faceware is able to provide high fidelity facial responses with only one camera, and not a stereo pair. It also does without infrared, which in theory makes solving faces much harder, due to natural shadows cast by the head unit’s camera arms or support. “I wanted to design this system to be as on-set and bulletproof as possible,” comments Jones. “It is just an HD-SDI that is just ‘on’ – all the time. Once you put the battery on, there are no camera settings, you can’t accidentally bump it off or change its settings or rebooting needed.”
 The mono camera solution uses machine learning to infer the jawbone position, something other systems try to solve from a pair of cameras or a stereo pair at the front of the helmet. Having one camera should not produce such good results, but the ML elevates the results impressively. Another advantage of having only one camera is reduced weight. In our various fxguide and fxphd projects, we have used a range of camera head rigs from bespoke to mass-marketed and there is genuine user fatigue that comes from wearing a heavy head rig. Heavy rigs cause increased neck strain, and the extra weight mandates a higher helmet to combat the swinging of the laden camera arm. We have had skull blisters from wearing head rigs for long periods, day after day. The newer Mark IV is both lightweight and comfortable. We had a choice of three sizes and while our thick skulls required the largest rig, Faceware is confident that the vast majority of adult skulls can be serviced in one of the three standard helmet sizes.
The mono camera solution uses machine learning to infer the jawbone position, something other systems try to solve from a pair of cameras or a stereo pair at the front of the helmet. Having one camera should not produce such good results, but the ML elevates the results impressively. Another advantage of having only one camera is reduced weight. In our various fxguide and fxphd projects, we have used a range of camera head rigs from bespoke to mass-marketed and there is genuine user fatigue that comes from wearing a heavy head rig. Heavy rigs cause increased neck strain, and the extra weight mandates a higher helmet to combat the swinging of the laden camera arm. We have had skull blisters from wearing head rigs for long periods, day after day. The newer Mark IV is both lightweight and comfortable. We had a choice of three sizes and while our thick skulls required the largest rig, Faceware is confident that the vast majority of adult skulls can be serviced in one of the three standard helmet sizes.
Remarkably the video from the camera is provided as low distortion colour video, even with the close proximity that the camera has to the artist’s face. This is very important for any later validation work. The recorded video becomes very useful reference footage for animators seeking to tweak or check expressions in offline pipelines. Nearly all other rigs provide a widely distorted monochrome, ghostly IR image as standard, which is very hard to judge performance from when later it is used as a reference.

The Faceware system when being used for live productions streams its output back to base, and does not record on the operator, it has around a 500ft (150 m) range, with a sub-1-millisecond delay at HD video stream resolution. The Mark IV records color HD video with Prores or DNxHD compression in a .MOV file. The Mark IV headcams do not come with a built-in microphone, but audio can be embedded in the same source face video by connecting an audio feed to the audio inputs on the back of the AJA Ki Pro Rack that makes up part of the workflow of the system. Importantly the timecode of the video can is also integrated along with any audio at the AJA Ki Pro Rack when it is recorded.
While we roadtested just the one system, in a live setup one can capture up to 5 actors wirelessly. For wired setups, there’s no limit other than the number of digital video recorders available. We had earlier tested a GoPro Faceware solution, and while today that option is still supported and sold (with the GoPro7), Jones believes the new system is less prone to operator errors, with high rigidity “the new system has longer battery life, better fit and finish and full-resolution live streaming.” The MarkIV camera records up to 1080/60 fps but the team often recommends that 720/60 is adequate for good capture. “It provides as detailed a tracking solution as you can really get with any rig,” Jones comments. The Faceware software is not bound or limited by the resolution of the cameras it seems. “We are just not seeing the gains you might think, from going to higher resolutions,” he adds. It is worth noting that the camera shoots portrait not landscape so the actor’s face is captured ‘sideways’ so as to get the most use of the resolution that is used.
Software
The Faceware software runs off the single camera, and has traditionally. The team has explored stereo and depth cameras but the team believes the single-camera solution is more robust. The most noticeable example of this is how short the initialization process is. Not only does the software do an excellent job at locking onto the features of the face and tracking them but it even worked well when tested with glasses.
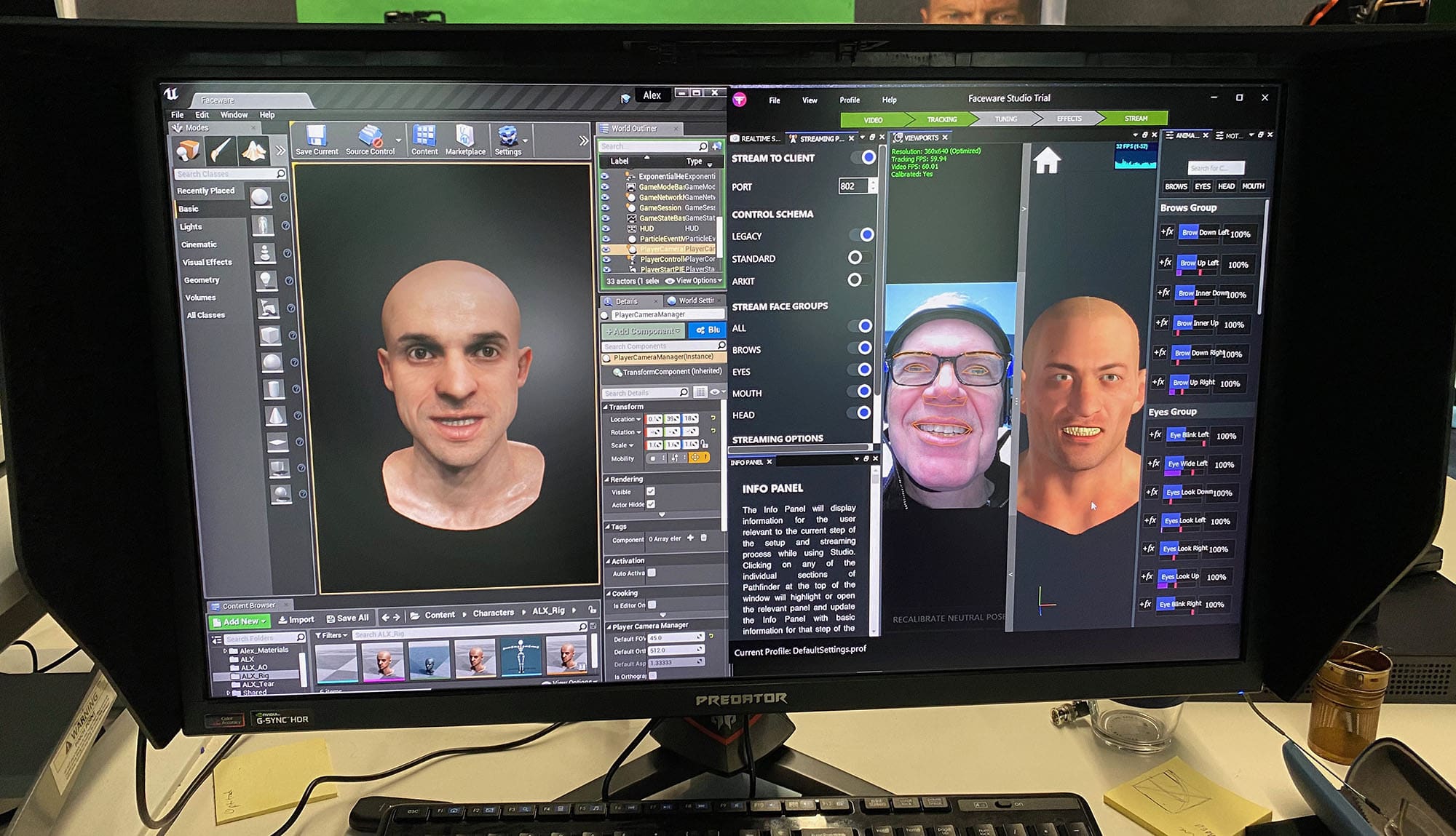
The initialization reduces the need for the actor to re-align the helmet each time with the same precision as some other systems.
Unlike iPhone face capturing apps, the Faceware software has offsets that allow tuning of how the actor’s input expressions translate to the output character. These deltas or offsets are invaluable for tuning lip-sync and they are easy to tweak and well laid out on the screen.
Faceware Studio
This is Faceware’s live or streaming option.
The real-time tracking is primarily focused on the actor’s facial features, but there are also special allowances for the teeth, “and it’s solving for head position in the frame and the jawline, – actually there’s even ear positioning. So a lot of things that contribute to the tracking performance,” explains Josh Beaudry, Technical Account Manager at Faceware. Many of these specialist algorithms contribute to the jaw solution along with the ML, as it is so critical to producing good lip-synced animation.
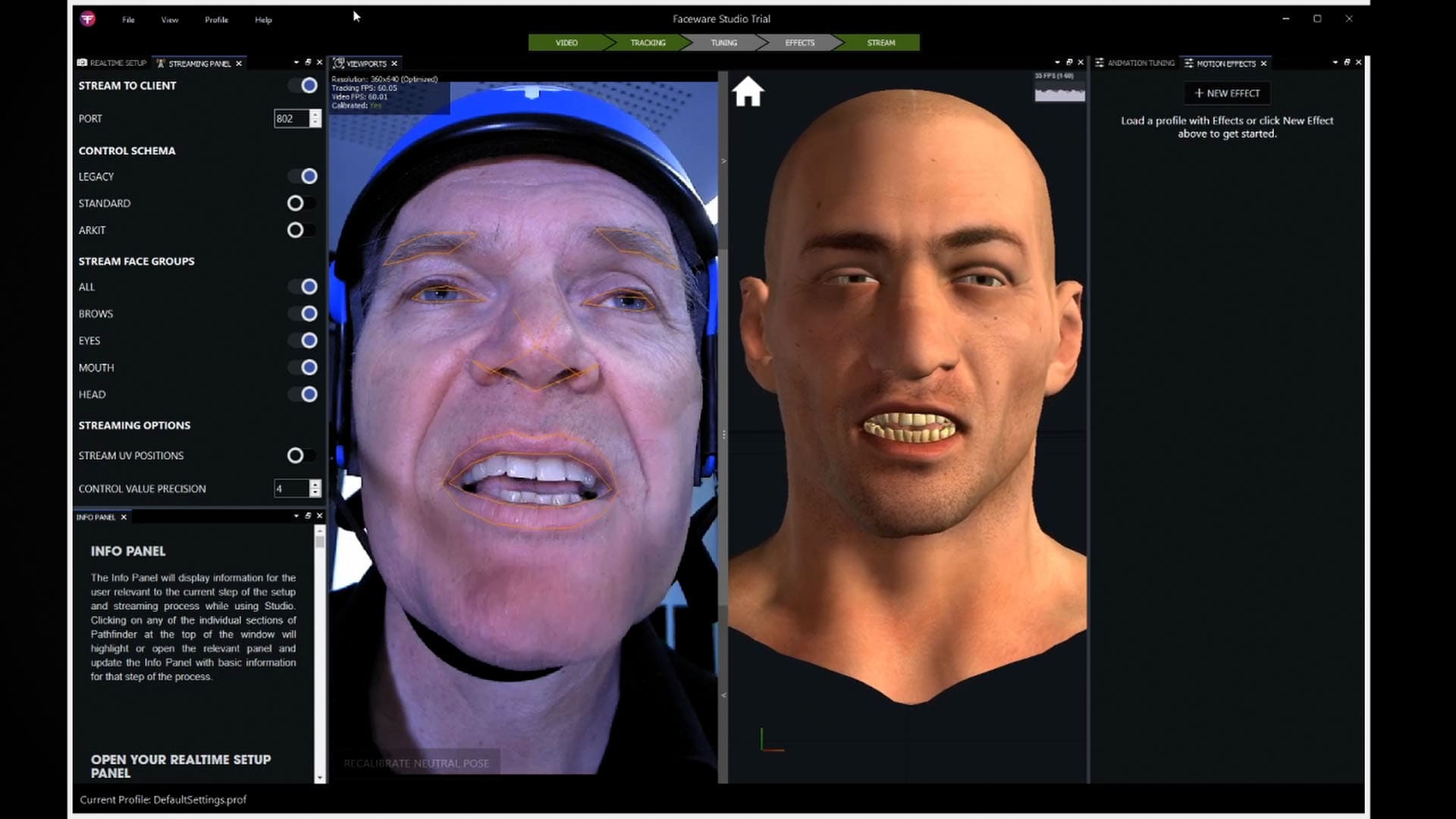
The new system is more non-linear and predictive in its solution. This can be seen if one is mid-shot and the actor actually slides on reading glasses. In this case of partial occlusion from the frames, the system continues to track. “What you’re seeing when you put your glasses on is the neural network initialization,” says Beaudry. “On every frame, it’s finding the head, it’s finding the face, it’s placing the landmarks based on what it knew before, but if it doesn’t see something, it is making its best guess and adapting. So there is a lot fewer errors in this version of the technology than there were previously”.
The use of ML does not mean lengthy training sessions to create specific training data the program is using a broad generic set of annotated data and then drawing conclusions from that based on what it’s seeing in the moment, informed by what it has seen before in the session. That training data included people with glasses.
This ML approach avoids widely inaccurate tracking when partial occlusion occurs. The program remains with a plausible track estimation rather than suddenly assuming the actor’s eyebrows have shot off their head. “This latest technology is also especially good with people who have a mustache or a beard. It provides greater fidelity around the lips,” says Beaudry. “You don’t have the kind of popping or system confusion,… it gives you a lot more flexibility and forgiveness when you’re in a scenario where you can’t have someone clean-shaven.”
Currently, there is no OSX version of Studio. The company says that it has the infrastructure to go in that direction if the demand is there, “which so far for us, it hasn’t been, but it’s on our mind,” says Beaudry. “But the technology is somewhat agnostic and it could be ported over relatively simply if the demand is there.”
The Faceware live workflow includes the use of the Glassbox plugin. “Glassbox approached us, because they have a lot of experience working in virtual production and offered their services to help make a pipeline that was very UE4 centric,” explains Beaudry as to why Faceware does not provide this functionality. “We took them up on their offer and they are a pleasure to work with and super knowledgeable in the field. We trust them.”
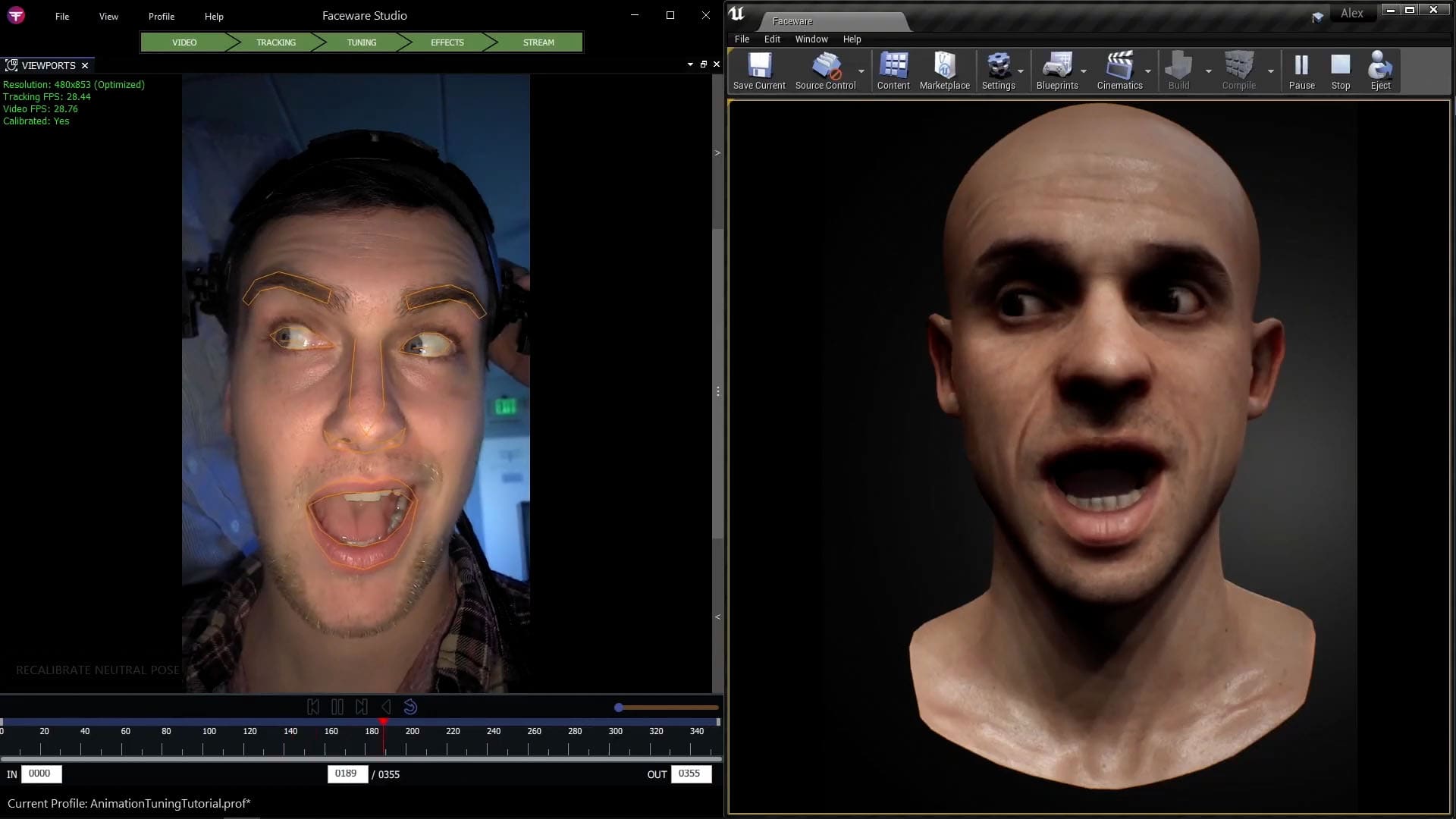
Analyzer
The Analyzer is the tracking software used for the offline workflow. It has been out in various versions for some time and is a well-developed piece of software. It tracks the face and exports the data. It tracks facial movement from the mono video feed using machine learning and deep learning. It uses markerless technology to track everything the face express, at high quality. Importantly it includes an advanced pixel-tracking technology that provides extremely accurate eye and gaze tracking. The system is markerless and adding visible markers or dots to the face does not inherently increase tracking accuracy, but markers can be added in such a way as to aid in creating the training frames.
Retargeter
Retargeter is an Autodesk Maya, 3DS Max, or MotionBuilder Plug-In. The Retargeter needs to ‘learn’ how the final face is posed based on the controls from Analyzer and Retargetter. Setting up a character in Retargeter is a two-part process. The first part involves adding the rig controls into the character, so the software knows what controls go with each part of the face. This allows the software to apply the animation to the correct places in one’s rig. The second part adds user-created poses for use with Faceware’s AutoSolve functionality.
Poses are an essential part of animating with Retargeter. Much like creating Training Frames in Analyzer, the user decides where the most distinct facial shapes are occurring and poses the character appropriately on those frames. These poses are then used in Retargeter to apply animation to the entire shot. Later they can be adjusted, more added, delete, or tweaked.
In the future, the team is looking at moving the tech from the Live Faceware Studio and further integrating it with the offline pipeline. “In the short term, we are looking at rapid production pipelines. We are looking at taking the data from Studio and not just using it as a streaming tool but as a production tool,” explains Beaudry. “Being able to work in post-production, and having studio leverage its real-time powers, to help speed up and make it easier for everyone in the short term.” In the medium term to long term, it is clear there is a real desire at Faceware to wrapping their entire tool suite into a one-stop-shop for facial animation production. “Where we sit in between capture and your final results but providing cutting edge technologies to solve the tracking problem entirely and provide high-quality data very, very quickly,” says Beaudry.
Remote capture
COVID has lead to many teams needing to work remotely. Faceware itself is distributed, so the company is very aware of the need to have portable work. While traditional capture volumes are great, many MoCap teams in the entertainment space have moved to using portable rigs, such as FaceWare with Xsens suits, vs more installed optical tracking volumes such as the VICON system, which is used in virtual production and LED capture volumes. . We have been using the Xsens inertia body mocap suit for some time and it works very well with the FaceWare system, integrating easily into one final digital human or retargeted character.
Later this week we will also be speaking to the Oscar-winning teams in the area of facial capture from this year’s Sci-tech awards.