SIGGRAPH had such a huge amount of NeRF content. In part 2 we begin by looking at the incredible advances published recently: starting with Gaussian Splating – one of the hottest papers in the NeRF VFX world at SIGGRAPH in LA. This is followed by the hottest demo at SIGGRAPH, NVIDIA’s working holographic 3D video conferencing system prototype. Then we look at stitching NeRFs and finally mixing them up with Stable Diffusion. Just prior to SIGGRAPH, two papers with similar names using the term ‘NeRF2NeRF’ came out. The papers are unrelated but both really useful. The first of these can stitch together NeRFs. The second opens the door to generative AI combined with NeRFs and both are in this, our Part 2 of The Art of NeRFs series (Part 1 is here).
Gaussian Splats
Radiance Fields or NeRFs are incredible, but no solution for high-quality real-time 1080P rendering has existed. Current methods are not quick to train (to a high-quality level) and they can not playback high-quality real-time (≥ 100 fps) interactively at HD resolution. At SIGGRAPH, a French team showed 3D Gaussian Splatting. Gaussian Splats achieve state-of-the-art radiance field rendering while maintaining competitive training times and providing high-quality real-time HD output.
This has been a breakout hit in the graphics community and looks to accelerate a range of NeRF-style applications dramatically. 3D Gaussian Splatting is a rasterization technique for Real-Time Radiance Fields or NeRF Rendering that allows incredibly fast rendering of photorealistic scenes learned from a small sample set of images.
Splats, in programming languages like JavaScript or Python are a programming concept used to represent multiple arguments or elements. The term “splat” comes from the idea that the operator “splats” or spreads out the values it represents. The concept has been used before in applications such as image blurring, texture mapping, and computer simulations to achieve smooth and realistic effects.
3D Gaussian Splats start from a set of sparse points produced during camera calibration, which represent the scene with ‘3D Gaussians’. In simple terms instead of polygons or triangles to define an object, it uses multiple gaussians or ‘blurry’ mathematical volumes (a Gaussian function over a grid of pixels or points).
The 3D Gaussian splats (3DGS) process uses a Structure from Motion (SfM) method to estimate a point cloud from a set of images. This is a known method that estimates a 3D point cloud from a set of 2D images.
 Next, each point is converted to a Gaussian. This could be immediately rasterized, however, only position and color data come from the SfM data. To produce high-quality results, you need to train the model. The training procedure uses Stochastic Gradient Descent, similar to a neural network, but without all the layers. This is one of the secrets to why it is so fast. It does not have all of the ‘deep’ layers of many other approaches. Training is based on calculating the loss between this early rasterized image and the ground truth image in the training.
Next, each point is converted to a Gaussian. This could be immediately rasterized, however, only position and color data come from the SfM data. To produce high-quality results, you need to train the model. The training procedure uses Stochastic Gradient Descent, similar to a neural network, but without all the layers. This is one of the secrets to why it is so fast. It does not have all of the ‘deep’ layers of many other approaches. Training is based on calculating the loss between this early rasterized image and the ground truth image in the training.
 And then it does something important… if the gradient indicates it is too ‘wrong’ – the gaussian is split, cloned or the alpha is adjusted.
And then it does something important… if the gradient indicates it is too ‘wrong’ – the gaussian is split, cloned or the alpha is adjusted.
In other words, if the gaussian is small, then it clones it. If the Gaussian is too large, it splits it and if the alpha of a gaussian gets too low, it is removed.
 Working based on a rasterization error-training approach means preserving desirable properties in volumetric radiance fields while avoiding unnecessary computation in empty space.
Working based on a rasterization error-training approach means preserving desirable properties in volumetric radiance fields while avoiding unnecessary computation in empty space.
This approach gives very fast output and it can match many current systems for significantly less training time. It produces better results with fewer ‘floaties’ and errors while providing stunning clarity when given similar training time to other methods.
The limitations are that it needs a lot of VRAM on your GPU. Most of the 3DGS work on the net that has been posted has been output on expensive NVIDIA cards with 24 GB of RAM for training, (- although 3DGS, once trained, can run with much lower RAM). 3DGS also require reasonably large amounts of disc space and for the moment they are static – but this is set to change (see below). As Dylan Ebert, a NeRF and Imaging expert posted online, there are already a lot of viewers, tools, and implementations of 3D Gaussian Splatting, including viewers in both Unity and Unreal Engine.
Visual Effects Compositing of RGB + W Captured Gaussian Splats
Infinite Realities is a leading capture company and they have been extensively exploring 3DGS. Using their custom-built RGB + W video scanning system, Infinite Realities captured a static pose of their 3D/4D Scanning expert Henry Pearce, under varying “baked” RGB + W illumination patterns using HDRI probes as input into their real-world rig. They used classic HDRI’s from the hdrlabs.com and hdri-haven.com websites.
The 3DGS were trained, trimmed, cleaned, and rendered out using a custom-built version of Inria’s Sibr viewer. They then took the rendered frames into After Effects to composite the 3DGS back over the source HDRI images that were used in the RGB+W capture rig.
The original tests used HDRIs that the team had access to, but the team can also generate an infinite amount of new baked or imagined lighting states via their capture rig. Any HDR location probe could be used and thus mimicked since they can relight the subject virtually.
They used the CamTrackAR plugin to get the motion data from an iPhone to simulate real-world handheld capture of the subject for the test below. Making the effect seem naturally shot.
Infinite Realities were featured in several previous stories here at fxguide, most recently with their work with Synthesia.
IR + AeonXShowcasing:
4x R&D lighting tests of Henry Pearce lit with Infinite Realities physical lighting rig using various HDRI’s including:
Lee Perry-Smith and the team have been testing this technique on static 3D gaussian splats, but they are looking forward to doing moving tests in the future.
“Over the past year, IR has delved into R&D using Nvidia’s Instant Neural Graphics Primitives (INGP) and Inria’s Gaussian Splatting (3DGS). This has rekindled our dedication to scanning humans and recreating them digitally, especially in motion,” commented Lee Perry-Smith. “With these new tools, we can scan subjects with more detail, capturing elements like shiny surfaces, transparent materials, and fine human hair with greater ease.”
Lee Perry-Smith believes this progress will allow people to preserve current scan data for upcoming spatial and holographic devices of the future. The company is following closely to see how this technology evolves in the next 6-12 months .”We’re particularly enthused about the potential of 3DGS and are actively integrating its capabilities into real-time R&D projects and conventional VFX compositing workflows. While there’s still ground to cover in terms of training, playback, and compression, its promise is undeniable.”
Above is a ‘moving Gaussian Splat’ which is actually multiple 3DGS swapped in and out very quickly like a flipbook.
“We’ve been working on a custom version of Inria’s Sibr viewer to be able to playback (flipbook mode) a sequence of frames at around 60fps to navigate in real-time. We still have some work to do on compression and loading frames into VRAM on the GPU to improve performance,” explains Lee Perry-Smith. This was a crude method implemented quickly to test performance, as currently there is no temporal consistency between frames, hence the color and brightness flicker but we are eagerly awaiting this code release via Github to hopefully improve the training quality further.”
NVIDIA’s working Holographic 3D Video Conferencing System.
The most impressive demo we saw at SIGGRAPH was the real-time NeRF conferencing system by NVIDIA in partnership with Looking Glass. Michael Stengel from NVIDIA and Shawn Frayne from Looking Glass sat down to explain their 3-way 3D video conferencing system that uses just mono RGB input video but runs in real-time on a Looking Glass 3D display powered by an RTX 6000 ADA GPU.
The system allowed three people in separate locations to talk to each other – as if we were making eye contact with pose redirection through GPU-accelerated NeRFs streaming – all with NVIDIA Maxine audio effects and Spatial audio. The system required no special glasses and did not work via a system like the head-tracked stereo rendering (as seen on Acer SpatialLabs laptops) – it just worked immediately as anyone sat down at a system and said Hi to the other participants using real-time NeRFs.

At SIGGRAPH in LA, the team allowed anyone to try out the AI-mediated 3D video conferencing system in the Emerging tech section. The goal of the research is to convert 2D to 3D just from the RGB mono (normal) camera, to enable live 3D video conferencing. In effect, the system transmits and renders people in ‘3D’ – but not as a 2D video, but as a 3D Looking Glass ‘hologram’. “We do that with a one-shot neural network that takes in 2D inputs and generates a neural radiance field as output,” explained Stengel. “This is a description of a 3D volume, and in particular, our representation uses tri-planes, which is a 3D volume format that has basically a description for three orthogonal views: frontal view, top view, and side view. We’re using that representation as an intermediate format for 3D.” This NeRF format works extremely well for compression and is ideal for the NVIDIA GPU hardware, one gets all the benefits from years of 2D hardware video encoding tech – but the signals are then reconstructed into a Hologram. “We can exploit our video encoding, which we have already implemented in hardware to reach really high compression rates so that we can very efficiently encode, decode, and stream that kind of data. And it makes it very compatible and competitive with traditional 2D video conferencing, but in full 3D,” adds Stengel.
The latency during the booth demo was about 70 milliseconds from the camera-captured frame to the rendered frame on the live companion display. That included all the encoding of the video stream, streaming to the server, decoding there, creating the 3D volume, encoding that part, streaming it back to the client, decoding there, and rendering from the neural radiance field to the display.
It did not include the buffer swap, but that would, in the worst case Stengel estimated that would increase the render time by an additional 16 milliseconds. Naturally, this would depend on the network connection, but in the field, it could be in a range of 100 milliseconds, which is very competitive with traditional video conferencing.
“It really depends on how you tweak the quality,” he adds. “What you see right now is five megabits upstream, which is a fairly high-quality RGB stream for a mono image and at full HD resolution.” And downstream is 2 x 10 megabits, – thus 20 megabits for a three-person conversation such as the one demonstrated at SIGGRAPH.
In terms of user experience, a Looking Glass screen produces a space about as deep as the screen is high. In this conferencing volume, you can turn your head from person to person, and the system makes it feel like you are speaking directly to another person. This is unlike Zoom, where everyone is front-on to their cameras but not making eye contact. In the NVIDIA demo, the real-time NeRFs made it feel as if the other two people were floating casually on either side of you, and you could move your head to see further around the sides of their heads – interactively. It really was like having two Star Wars holograms floating in front of you – but without the blue tint and classic Star Wars’ signature Hologram interference lines across the image.
In the live conference demo at SIGGRAPH, the system was producing 45 views on the 32-inch Looking Glass holo screen – which is what allows the image to appear as a Hologram. The Looking Glass display seemed smooth, but it could run higher and work with 90 or 100 views, producing a very smooth and clear image. To prove that point, a non-real-time playback-only 65-inch Looking Glass additional demo was also shown running at a higher rate of views and at a much higher 8K resolution. It was showing footage in real-time from pre-rendered material streaming from a separate NVIDIA A5000 mobile GPU Laptop system under the monitor.

The higher clarity 8K display uses an NVIDIA proprietary ML super-resolution pass on each view. It uses various features that the system would otherwise discard on the real-time video conferencing system. The offline rendered 8K system, uses all the features of the NVIDIA’s AI inference process and this allowed the team to have it hallucinate much more detail for each view.
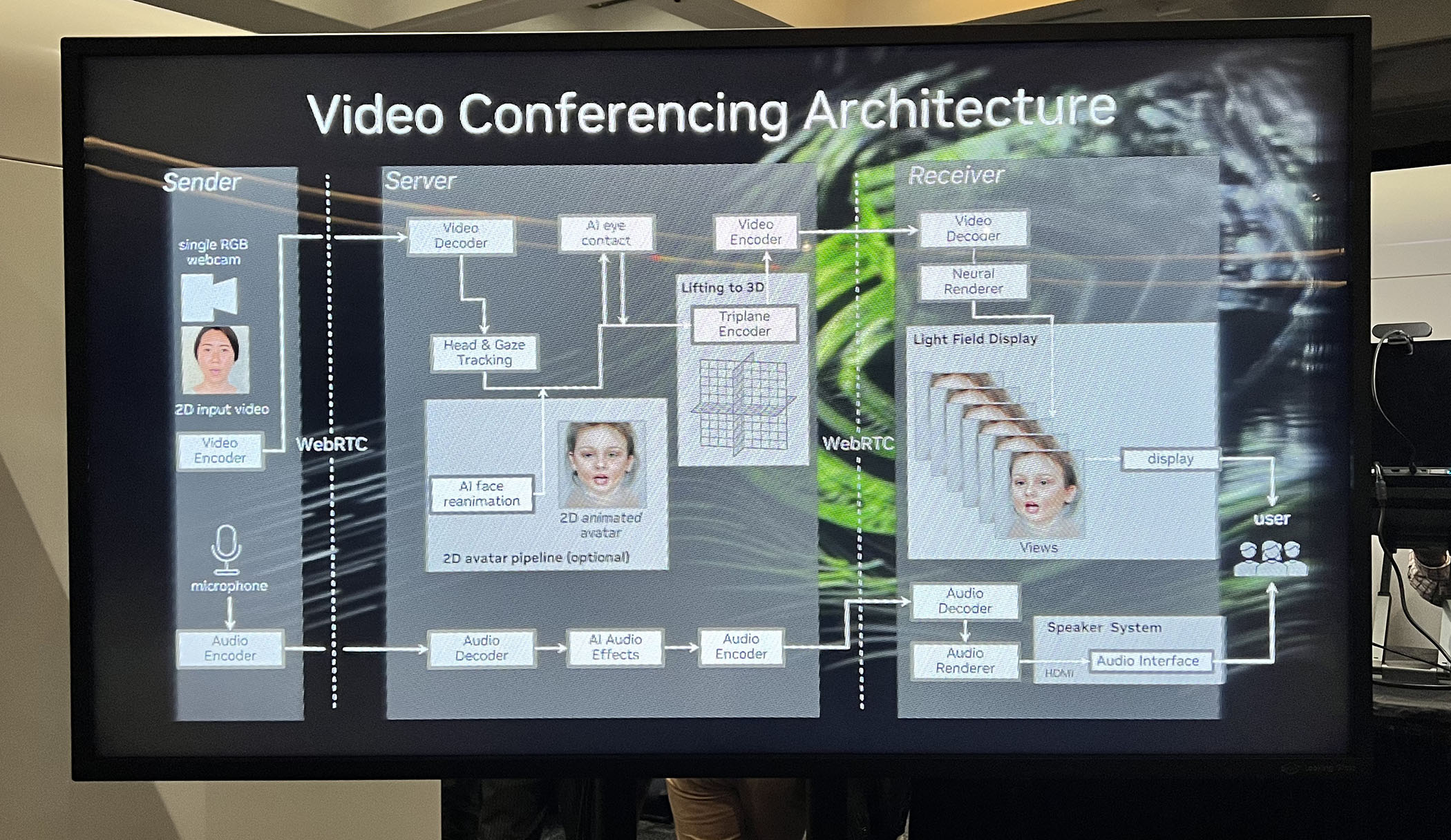
With both the live and the pre-rendered 8K system, your brain fuses the images together very smoothly, so you don’t see many effects, other than a bit of decoupled, ‘aliasing’, in the Live demo. The super res is “using StyleGan as a backbone. This creates a feature vector, and we arrange those features,” Stengel explains. “The first three values are the color and then we have additional features that we generate that help with the super-resolution, but for the real-time system, we just discard the other features.”
For editing up prerendered sequences Shawn Frayne, from Looking Glass, explains that “most of our software currently supports 3D workflows. We have a plugin for Unity and also for the Unreal Engine, plus Cinema 4D, Blender, etc.” Thus if you have native 3D content, in your software pipeline the system can handle all the layering in the background. “Whatever you see in your 3D creation workflow, you click the button, and then it handles those two steps to get it to the display.”
Stitching NeRFs: ‘NeRF2NeRF’:Pairwise Registration of Neural Radiance Fields.
nerf2nerf: Pairwise Registration of Neural Radiance Fields
One of the key issues for NeRF in production is being able to stitch together two NeRFs. A new paper for registration neural fields was published that extends classical optimization-based local registration to work with NeRFs.
NeRFs do not have traditional illumination and color, so to make registration between two NeRF is complex. As one can’t align NeRFs based on normal illumination and color, they introduce the concept of a “surface field” – a field distilled from a pre-trained NeRF model that measures the likelihood of a point being on the surface of an object. The process then optimizes iteratively to find a transformation that aligns the surface fields of the two scenes.
A clear use of this technology would be stitching together drone-captured NeRFs to build out a location scout or survey. In fact, one of the motivations of this paper was trying to have multiple drones or robots go around a location such as a city, get different NeRFs, and then be able to fuse them together into one giant NeRF. In VFX, this could also be used to create a new hybrid virtual set from disparate location samples. In this latter case, the scene would not need to be a natural or perfect extension of one NeRF into another. Even with only partial commonality, the two NeRFs can be aligned and fused.
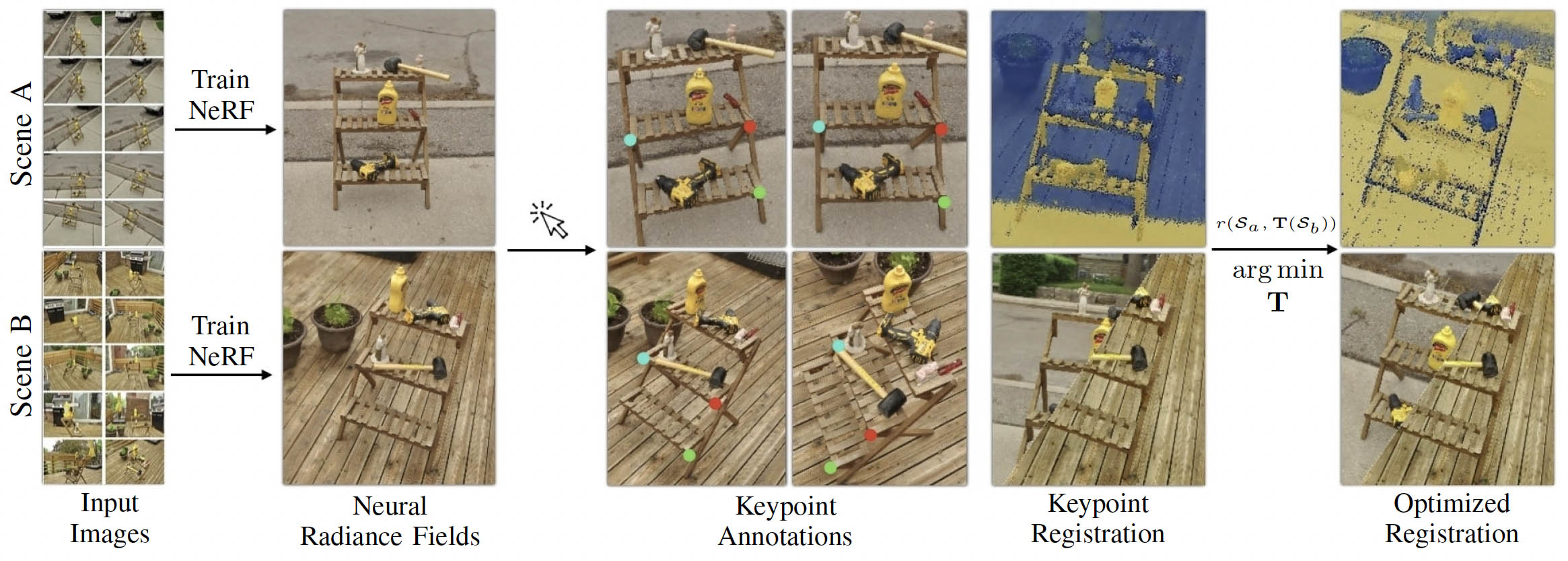
In the example above while the main stand is common to both locations, the floor and objects on the stand are different, yet the two NeRFs can be optimally registered and aligned.
We spoke to Lily Goli, lead author from the University of Toronto. Goli is a senior PhD and when she started her PhD in 2021, NeRF had just come out. “Back then there was a rise in how to make NeRFs better,… but people weren’t focused on processing NeRFs when they were already made, and there really still aren’t.” In her paper, Lily Goli and the team avoid the lossy conversion of converting these NeRFs to polygons and instead operate directly on the neural fields. They use their new concept of surface fields as a geometric representation of the NeRFs. Surface fields are invariant to different illumination configurations. This is not true of photogrammetry approaches.
A surface field is not a density field (which we discussed in Part 1 of this Art of NeRFs). The density field is defined as the differential probability of having a solid particle in a space. So by definition, it’s not bounded, it’s a positive number, anything bigger than zero, and you don’t know what you’re going to get at each point. Because NeRFs are optimized, the points inside the object do not have a meaningful density value, and the density values inside an object are very noisy. The density field is very powerful but it is different from the new surface fields. From a pre-built NeRF, the surface field is the probability between zero and 1 (100%) of a point being on the surface of an object. “It’s not noisy, and you can get a very neat field of where the surface has values of one,” she explains. Why do we need a surface field? “In order to be able to register two objects together, we need a good representation of their geometry. Because we want the representation to be something like an SDF (Signed distance function) or occupancy field, – which are popular already and useful for registration, we decided to derive something more useful from the density field.” Inherently, normal 2D registration processes take into account illumination and texture. They’re looking to match color values. Whereas, once the NeRF is made, it is independent of the view-based illumination, which is why this process works actually better than converting the NeRF to a classical 3D model with baked-in textures. “We basically try to just have a geometric representation. So in our process, we drop anything that has to do with the appearance, texture, or illumination.” explains Goli “The fact that this is not dependent on illumination is helpful.”
In the future one might include some color information to help even further such as Albedo, but the team left that work for future research. “Getting the Albedo and the illumination separately from a NeRFs still, I believe, is an open problem,” she adds. “There is, of course, some works being done in the space, (with human faces) but they are very dependent on their learning dataset and still not very generalizable.”
Mixing them up with Stable Diffusion. The other ‘NeRF2NeRF’ paper
Presented at ICCV 2023 is Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
This paper can be thought of as opening the door to mixing NeRFs with Stable Diffusion. We spoke to lead author Ayaan Haque, who at just 19 and as an undergraduate came up with a simple yet powerful idea. As a student at UC Berkeley studying EECS, under Angjoo Kanazawa, he has been working on generative 3D research and foundation models.
The paper offers a method for editing NeRF scenes with text instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, his group at Berkley came up with the innovative method that uses the image-conditioned diffusion model known as InstructPix2Pix to iteratively edit the input images while optimizing the (NeRF) scene, resulting in a new 3D scene that respects is based on the original NeRF but changed by whatever generative idea you have.
In VFX terms this would allow you to put up a drone, scan a location in summer, and then build a NeRF – naturally looking just like the summer location. However, you could get the computer to cleverly offer up ‘inferred’ images of the same scene under snow in winter, and now your NeRF is of the same location under snow. To be clear, the ‘model’ of your environment never left the NeRF representation… it has not been rasterized or output as polygons to do this transformation… it is all still inside the Neural Network, but it is just now a snowy winter version of your location – it is no different from if you had done a drone shot at that location in winter.
There is no reason this has to be used just on wide open environments – you could change the clothes of a captured NeRF person or adjust their makeup, hair, expressions, or even their entire identity with a new face.
The system works like this
Once you have the input images and built your NeRF, you gradually update a reconstructed NeRF scene by iteratively updating the dataset images while step by step re-training the NeRF:
- An image is rendered from the scene at a training viewpoint.
- It is edited by InstructPix2Pix by giving it a global text instruction, – i.e. Make this scene look like it is under snow in winter
- The original training dataset image is replaced with the edited image.
- The NeRF continues training as usual and the process repeats.
If you just used InstructPix2Pix on all the images before you did anything – there would be no spacial consistency. Running InstructPix2Pix on each picture away from the NeRF would give different things in each shot – each time. It would be as if they were photographed days or weeks apart. By stepping through the process, the NeRF slowly ‘absorbs’ the new global directive and thus it produces one sensible consistent NeRF.
As with so many NeRF innovations, the results are stunningly real but not exactly art-directable. The NeRF that is output does deliver on what the global aim was – such as converting the scene to winter, but you can’t edit the NeRF to add a bit more snow here – or a bit less snow there… you just get the winter version of the scene slowly evolving. It does however point to an incredible new direction that could see Stable Diffusion and NeRFs start to feed and build on each other.
From Lab to Production
The NeRFs above are all only tests, but they point to major new directions that should be expanded upon as this NeRF technology moves from R&D, done by brilliant researchers, to being deployed in production by VFX TDs and artists. One of the biggest challenges VFX teams face is just keeping up with what is happening in this field. (Our thanks to Johannes Saam (Framestore) for even finding the last paper). The explosion of new approaches will still take time to both be adopted by VFX teams and then for those projects to see the light of day and be released. But there is little doubt we are only at the start of this entirely new way of generating captured and manipulated digital imagery.
We will publish more in the coming months here at fxguide.