Our overall takeaway from the GPU Tech Conference is that we seem to be hitting critical mass regarding much wider use of GPU tech. Of course, we’ve seen popular implementations such as Adobe’s Mercury playback engine, but now it is clear that both facilities and software developers are researching ways to use it even more. We see renderers such as V-Ray 3.0 and Octane 2.0 pushing the limits of what the GPU can do with more and more features.
In this second article from GTC, we take a look at a few case studies of sorts from companies looking to move more of their toolset to the GPU. What is clear is that the roadmap that NVIDIA has set has been critical in breaking down barriers to implementing GPU tech. From adding more memory to cards and improving their CUDA drivers with features such as unified memory, NVIDIA is laying the foundation for tools to move to the GPU. For the future, the Pascal architecture with its stacked RAM will do so even more. It’s also quite clear that the company is supportive of the efforts of their vfx & 3D customers, providing close technical collaboration on these cutting edge projects.
MPC, GPU visualisation, and Fabric Engine
Damien Fagnou, Global Head Of VFX Operations at MPC, gave a talk about their exploration of using GPU rendering to help their visualization pipeline. MPC has built an in-house framework called Muggins, which is a collection of classes and libraries which they use to build their various in-house tools. One aspect of this, MugginsGL, is used to view quick GL previews of their work to more quickly iterate through experimentation. Over the years, however, it has become more challenging because of the size of scenes with fur, materials, large crowds, cloth/clothing, hair, cities…basically all the aspects of modern visual effects scenes ends up with the reality of having billions of polygons in scenes. On top of this, they can easily have 100 textures pages for large assets, with up to 16K resolution per texture, all adding up to billions of texture pixels.
So they decided to pursue GPU raytracing for visualisation using NVIDIA OptiX. It’s a research project of sorts, with incredibly close collaboration between the teams at MPC and NVIDIA. MPC is using the C++ side of the OptiX API to get data from the host into the GPU without having to do too much coding on their end.
The idea is not to use the GPU for photo-realism, but instead for performance of viewing large scale scenes. The first concern was shaders. They use a complex shader model for their pipeline, but for this purpose they decided to implement two basic shaders, one of which was transparent. But the real question was how to get the appropriate geometry into the renderer — geometry that would give them consistent and fast results.
So they decided to use Fabric Engine to help with the process, even though they already had the Muggins framework. They found multiple benefits in doing so:
- it’s a high performance language, easy to learn and similar to python
- good memory management
- code is compiled at runtime in LLVM so it is incredibly fast
- it has extensions for Alembic, Bullet, OpenImageIO, and you can build your own extensions (they added in-house Muggins and Alice, as well as their asset management)
They were able to achieve very good results for visualising large scale scenes, especially with replicated geometry. One key has been standardizing on high end hardware (Quadro K6000, Telsa K40, 24 core CPU, Fusion iO cards). The CPU is necessary to feed the GPU and the Fusion IO card is used to speed up getting textures to the hardware.
Their challenges ahead include how to deal with complexity and different primitives, as well as the 12GB memory limit in the GPU. The other major challenge is figuring out is how to you scale GPU computing power for the artist when you need it — in other words ramp up when you need to and fall back when you don’t. But all in all, they were pleasantly surprised with how quickly they got to the level they achieved and are “very happy about the future moving forward.”
Fabric Engine – the transition to GPU
Fabric Engine’s Peter Zion gave a presentation about the process behind getting Fabric Engine KL to run on the GPU. Fabric Engine is a combination of Python code and KL. Python/DCC code used for the UI as well as the actual construction of 3D scenes, which in then drives the KL code.
KL (apparently “Kale” as they pronounce it internally at Fabric Engine) is the high level programming language used for rendering, simulation, effects, and data import/export. It is a procedural, object-oriented language with a Javascript-like syntax, which makes it quite easy to learn. KL also provides binding to OpenGL, Alembic, Bullet, Open Image IO — as well as a rich extension mechanism that allows programmers to bind custom facility libraries. But the killer feature of KL is the ability to edit it at runtime — in other words, at the point in which you use the code. This means one can dynamically change the code within a window in a host application and have it update the scene dynamically.
But the big question is that since KL was initially designed with only the CPU in mind, can it also target the GPU? The goals of this transition would be effectively threefold:
- Allow most KL code to run without modification on CUDA GPUs
- Allow KL code on CPU to perform a parallel evaluation of other KL code on GPU
- Make memory management as easy as possible…you don’t have to think about it
They made a first pass at it back in early 2013, which was before CUDA 6 was released. They made really good progress, but dealing with memory issues was a real problem. The managing of copying data back and forth between the CPU and GPU was really difficult. It is simply much more complex on the GPU to manage and they really needed support from NVIDIA to make it work well.
Fast forward to the end of last year when CUDA 6 was released. This was the debut of “unified memory” in CUDA, which enables applications to access CPU and GPU memory without the need to manually copy data from one to the other. In other words (tough it is a bit of a simplification), programmers can effectively treat GPU + CPU as one big memory pool.
So due to CUDA 6, they basically didn’t need to worry about all the issues they had back in 2013 since it was all handled by the driver. This broke down a huge barrier, leading to real progress and they now target May 2014 for the release of the hybrid GPU/CPU version of Fabric Engine KL. The initial release will have a few limitations, including no support for GPU-to-GPU PEX and no support for objects and interfaces (though it can still work with their data).
From a TD standpoint, they basically don’t need to worry about where the code is running. They can make runtime changes to the code and it should work in either the GPU or CPU without any other modifications. Of course, there are technical and other limitations to GPU processing, so it’s not quite that simple. But KL also gives TDs the option determining whether something gets run on the CPU or GPU — it’s simple flag set in the code. And at runtime, the software looks at the code and directs the routine appropriately.
So…why do this? How about some benchmarks (K5000 GPU, 4×3.6GHz CPU)?:
- “Deep” Mandelbrot set: 23fps on the GPU / 2.1fps on the CPU
- Deformation in Maya: 24fps on the GPU / 5.1fps on the CPU
This was all without modifying any KL code — the same KL code was run on both the CPU and GPU from a user input perspective. Pretty stunning results.
In last year’s GTC article, we wrote about what a major factor unified memory will be moving forward, and this is a concrete example of that change. Due to the year on year improvements NVIDIA is making in their drivers, something went from not being possible to shipping within months of the CUDA 6 release.
For more information about Fabric Engine, check out our fxpodcast.
Pixar Keynote
The day started off with the second keynote presentation of the conference, which focused on how Pixar is using NVDIA’s GPU tech to help improve their creative process. You can watch the live stream, below.
The first part of the presentation featured Dirk Van Gelder, who showed how Pixar is using GPU processing in Presto, their animation software. In the second half of the presentation, Danny Nahmias and Alfonso Capparini spoke about R&D into how using NVIDIA’s OptiX ray tracing engine could lead to some significant improvements to their lighting pipeline. The demo showed interactive ray-traced lighting inside The Foundry’s Katana.
The presentation was targeted towards the general audience of GTC, which includes disciplines far outside the 3D and VFX fields — so it’s not necessarily a hard-core tech discussion. That being said, the keynote had really some great nuggets of info and what was quite interesting is the focus as to how a GPU approach can help the creative process much earlier than the final render. It’s all to easy to fall into the trap and say that GPU rendering couldn’t be used because it can’t handle the final due to memory limitations or that the GPU ray tracer doesn’t support a certain feature.
What this presentation showed, however, is that there can be significant benefits to implementing GPU rendering in the pipeline for both creative and workflow reasons. Watching the Katana lighting demo it’s easy to see how having an interactive experience when adjusting lights versus waiting an hour for a CPU render could be a huge workflow improvement for the lighting team. Work through early versions using the GPU and then do fewer CPU renders to check before sending off to the farm.
The total presentation is about an hour, with the real time lighting research segment beginning about 27:00 in.
Red Giant Universe & OpenGL
Red Giant recently announced Universe, a new membership-based offering for plugins and transitions, built on an entirely new platform. Sean Safreed, co-founder of Red Giant, hosted a session on the tech behind the new architecture, as the performance of the plugins heavily relies on the GPU for processing power. We covered the release in the past, but wanted to dive into a bit more about how the plugin creation works. Why? Because it’s pretty cool from an approachability standpoint.
At GTC, there’s a lot of talk about CUDA and parallel processing, but for Universe Safreed chose to go with OpenGL due to the fact that it is quite mature and makes cross platform and cross hardware development easier. They have plans for CUDA and Open CL capabilities where appropriate, but that comes well in the future.
The GPU framework contains hundreds of Open GL shaders mapped to javascript, with a floating point compositor that matches Photoshop or After Effects. It also has simple WebGL style drawing capability, with future plans for a 3D engine. There’s also some custom code modules included to handle specific tasks such as cartooning, atmospheres, etc.
From a programming perspective for the plugin creators, the development takes a different approach than almost any other system we know of. Instead of using traditional computer programming languages such as C++ or Python, the plugins are instead authored using Javascript. According to Safreed, this is because they wanted to make it as approachable to artists as possible — and Javascript seemed to be a better fit than anything else. The javascript system uses the Google V8 engine.
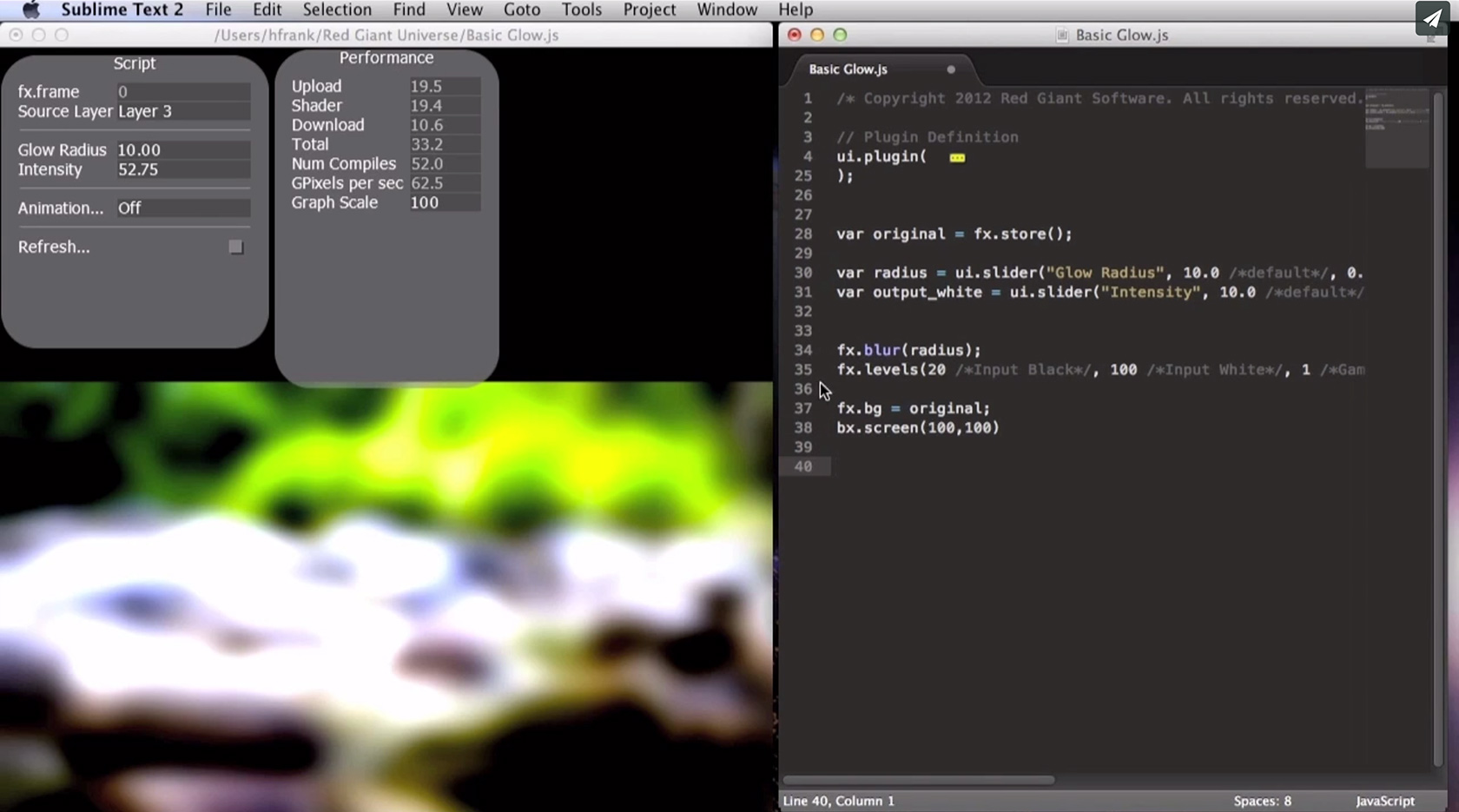
The plugins aren’t actually distributed as scripts, but instead as native plugins for each and every supported application: Final Cut Pro X 10.0.9, Premiere Pro CS 6, After Effects CS5.5, and Motion 5.0.4 (and later versions of the apps). This happens by running the Javascript file through a custom Red Giant compiler of sorts, which then outputs all the plugins for the various programs as well as keeps track of versioning of the plugins.
They key to the system is the aforementioned framework of GPU functions which have been created by Red Giant. They run the range from color correction, blending functions, noise, blurs, keyers, and more. The library also includes functions for creating UI elements for the plugin, such as numeric entry boxes, sliders, and pulldown menus. There are hundreds of functions available for use and more continue to be added over time.
Using a text editor, authors create elements in Javascript by referencing the UI functions. And then call on the GPU functions by referencing the appropriate functions. Red Giant has even created a custom package for Sublime text editor which will autocomplete code, making programming easier. Users can preview their results using “Supernova”, an in-house tool created to test the plugin as well as build the plugins for various packages.
Red Giant’s Harry Frank recorded a brief overview video showing this functionality, which we’ve included here.
As far the future, they are continuing to add dozens of new effects to the library, with over 30 currently in process. They have plans for a sophisticated 3D engine (non-ray traced), a text engine, and a 2D graphics engine on the GPU.
A big question many have asked (including myself) is “can we write our own?”. The answer is yes, but not right now. Red Giant has plans to make the tools available to artists so they can code away, but there is a lot of work and cleanup that needs to be done before releasing to such a wide audience. That decision, as well as how the plugins would be shared and distributed are all up in the air at this point, but a sensible timeframe for release seems to be in early 2015.
In the meantime, it is an interesting project to keep your eye on.
As an aside, if you’re a Smoke or Flame artist and interested in creating custom shader tools, you should check out Matchbox. For the last several releases the Autodesk products have had “Matchbox” nodes, which are effectively GLSL shader nodes that users can program themselves. But the best part is that several users – Jeroen Schulte,Julian Tarkhanov, and Ivar Beer — created a repository for user-created shaders at logik-matchbook.org/. We’ll be having a full article detailing their work, but in the meantime check out the shaders and learn how to code them over at fishbowl.tv.
Pingback: NVIDIA GPU Tech Conference: Report 2 | Occupy VFX!
Pingback: NVIDIA GPU Tech Conference: Report 2 | fxguide | timcoleman3d